gitlab….. 상당히 편한 녀석이다. 규링은 시놀로지에서 엄청나게 잘 쓰고 있기도 하고…
근데 어떤 썩을 것 땜에 시놀로지 나스 시스템이 망가졌다. ㅠㅠ

뭐, 이 기회에 욕심나던 작업도 있고 해서 데이터를 일단 외장하드로 다 뜬 다음에, 그대로 공장 초기화를 시키기로 해서 초기화 진행. 그리고 필요한 것들을 하나 하나 설치하고 있는데….
gitlab 설치할 때에는 패키지 구성되어 있는 걸 설치해서 간단하게 설치하자 해서 패키지 센터에 있는 녀석으로 설치를 했다. 자기 혼자 알아서 도커도 깔아주고, 자기 혼자 알아서 이미지 떠서 도중도중 입력한 smtp 정보나 도메인 정보, 관리자 계정 이메일 등의 여러 설정값 넣어준대로 알아서 잘 되나 싶은데…
계속 시작도 못하고 죽는다…!
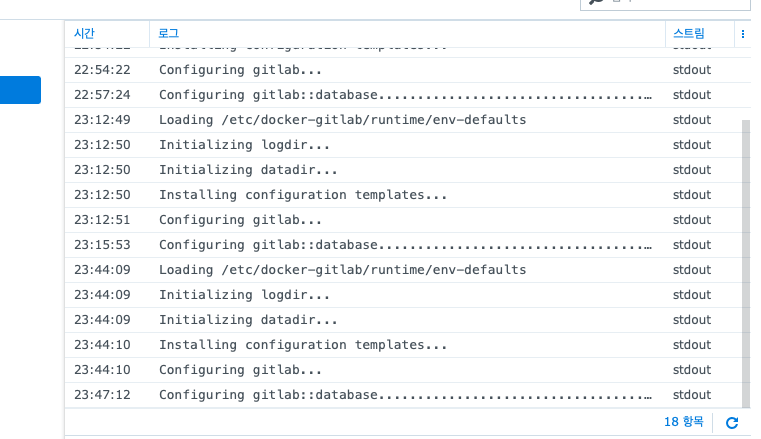
자꾸 데이터베이스 관련해서 죽는다….
….이게 왜 이런가 싶어서 자동으로 만들어진 도커들을 살펴보는데 거기에 답이 있었다.
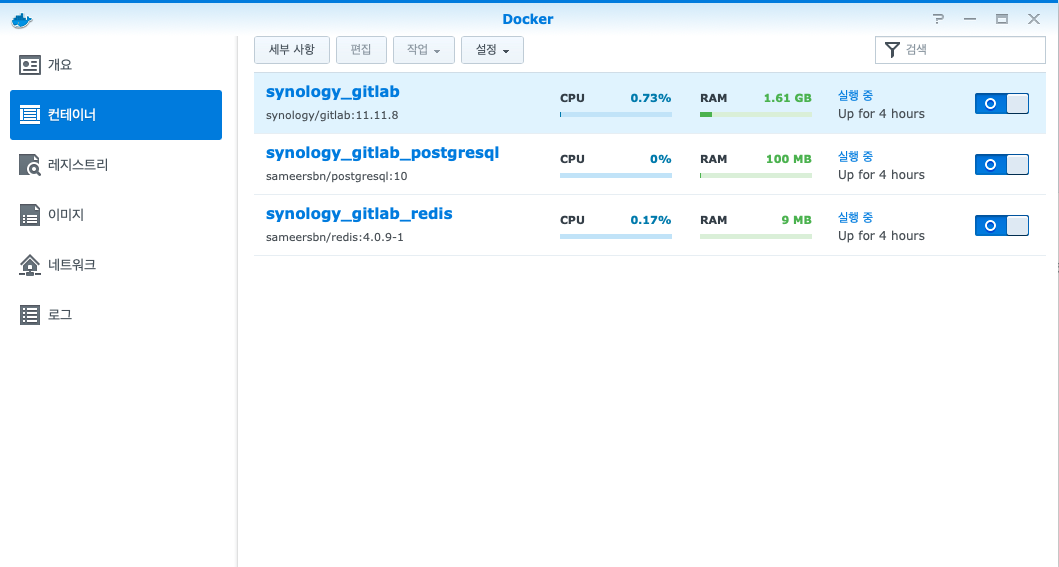
내가 안되던 때에는 맨 위에 있는 gitlab 본체의 컨테이너만 실행이 안되어있었다. 근데, 그 밑에 DB쪽인 postgresql은 멀쩡하게 돌고, redis도 멀쩡하게 돌고 있었다. 그 말인 즉, 본체에서 디비에 접근을 못해서 지 멋대로 꺼진 건데…
그럼 걍 네트워크 브릿지가 막힌거네..?
해서 브릿지 정보를 확인하고….
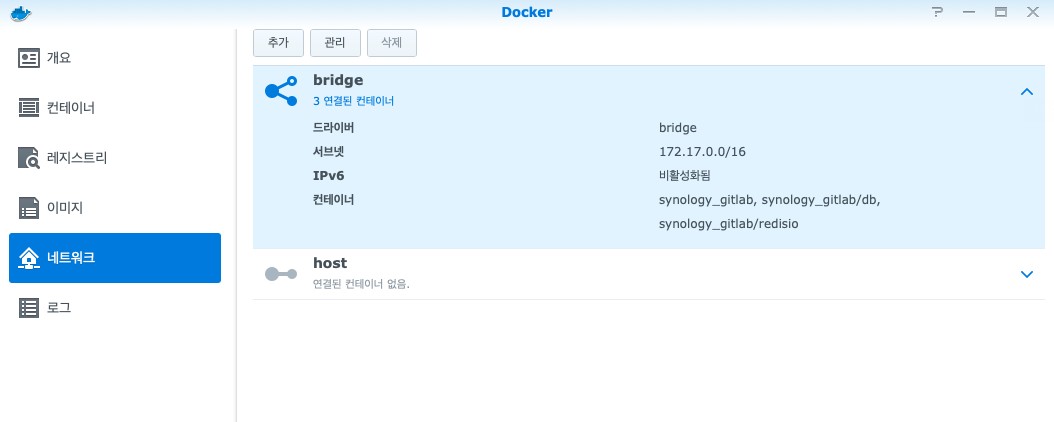
브릿지 정보에 있는 저 IP와 서브넷 정보를 방화벽에서 규칙 허용을 해줘야 한다…! gitlab 포트의 방화벽 허용과는 별개로..!
그전에 정보 적고 올린 것들은 아마 방화벽 설정따윈 하나도 안한 채로 막 쓰고 있는 것들이겠지….!!!! 머리를 장식으로 달고 글쓰는 거냐..!!!!!
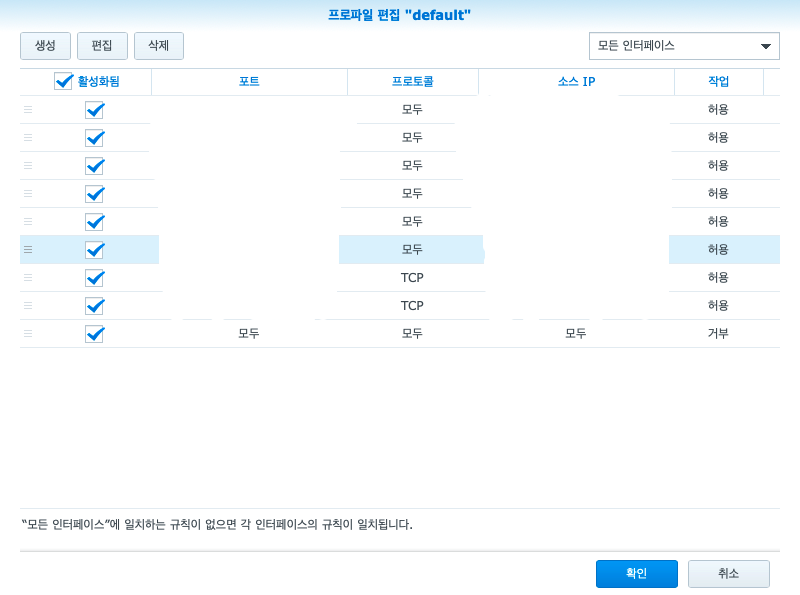
방화벽을 적용하는 데에는 규칙이 있다. 아무것도 없으면 방화벽은 동작 안하는 거나 마찬가지이다. 그래서 허용할 규칙에 대해서 해당 소스가 되는 ip 정보와 포트 정보를 입력하여 허용을 진행하고, 그 외에는 전부 거부를 하는 것이다. 그렇게 해서 허용하는 목록만 허용하게 되고 나머진 다 막는 것이 방화벽 적용 규칙이다. 이 부분에 허용을 안했으니 막힐 수밖에….ㅠㅠ
분명 아무것도 안하고 그냥 설치했더니 바로 실행되었어요 하는 것들… 방화벽 규칙이나 보안 규칙 빡시게 안잡은 것들일꺼다 분명…
근데 보안 땜에 방화벽을 먼저 설정 싹 다 해놓고 gitlab을 설치해서 쓰니깐 gitlab은 도커 브릿지 네트워크 통해서 네트워크 인터페이스가 되어 있으니 당연하게도 저쪽에서 막힌 것이다. 그러니 저쪽을 열어주면 해결.
참고로 라우터에서 포트포워딩까지는 안열어줘도 된다. 실제로 외부로 포트포워딩을 해야 하는 gitlab 접속할 때 이용할 포트(시놀로지 패키지 기본 설정 포트가 둘 있다. 그 둘만 해줘도 됨.)는 방화벽도 허용해줘야 하는 것이긴 하지만, 라우터의 포트포워딩쪽에서는 브릿지쪽은 안해줘도 외부 접속은 문제 없다. gitlab 구성요소들간의 통신의 문제를 해결하기 위한 것이니 나스의 네트워크 방화벽만 허용되어도 된다.
이거 땜에 시간은 날려먹었지만….
잊을만한 내용을 다시 상기하기에는 좋은 것 같아서 공유를 하려고 한다.
이런 정보는 삽질하면서 얻은 거니 블로그 글로 남겨야지….ㅠㅠ

p.s. 해당 서비스마다의 ip를 열어주는 것도 좋지만, 방화벽 설정 규칙이 너무 번거로워지기 땜누에 별로 추천하고 싶진 않다. 포트 범위는 nmap 같은 곳에서 잘 안잡히지만 특정 포트는 nmap으로 쉽게 스캔되기 때문에 공격 당하기 참 좋은 구실을 만들어 줄 수도 있다.