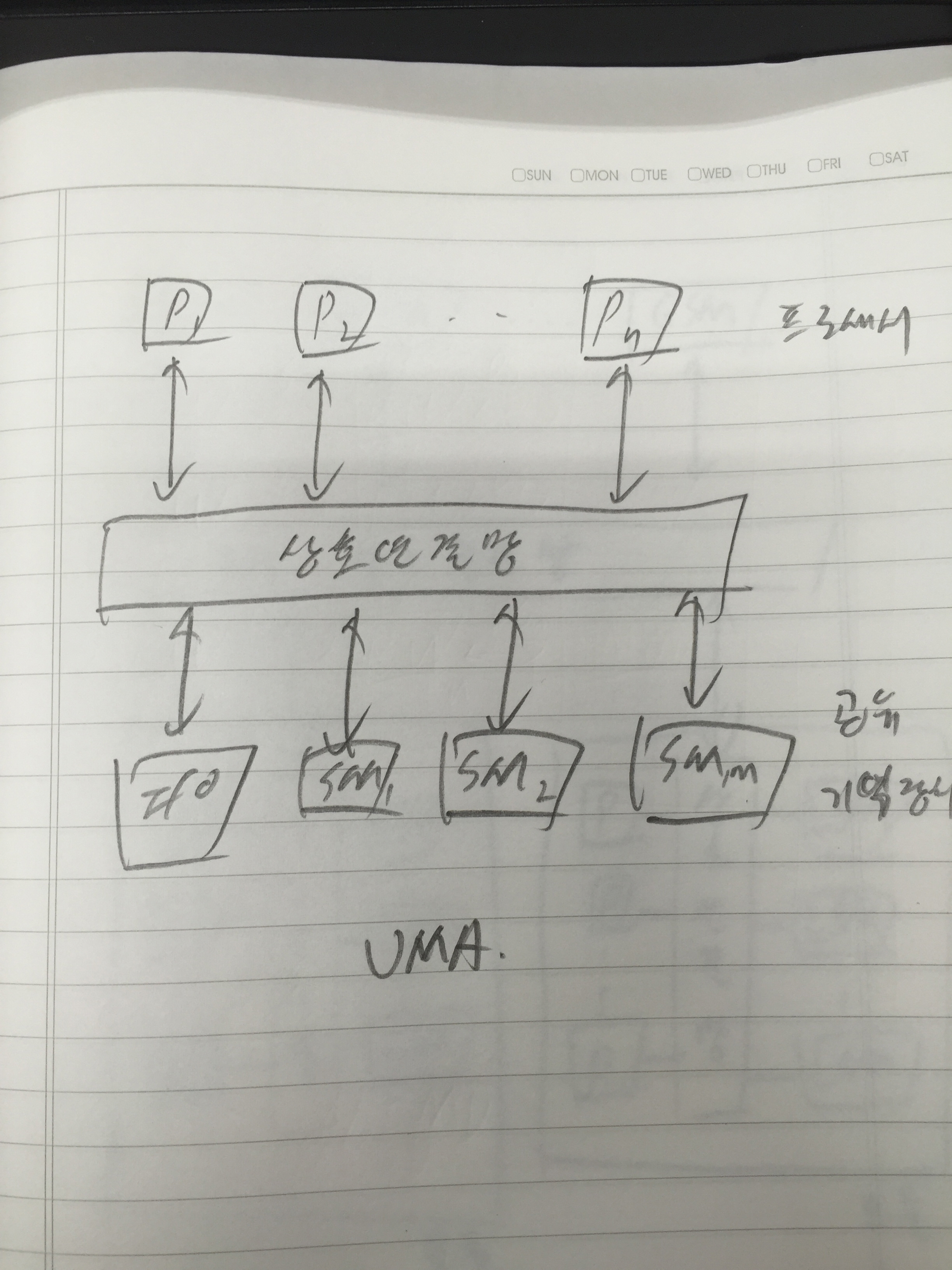
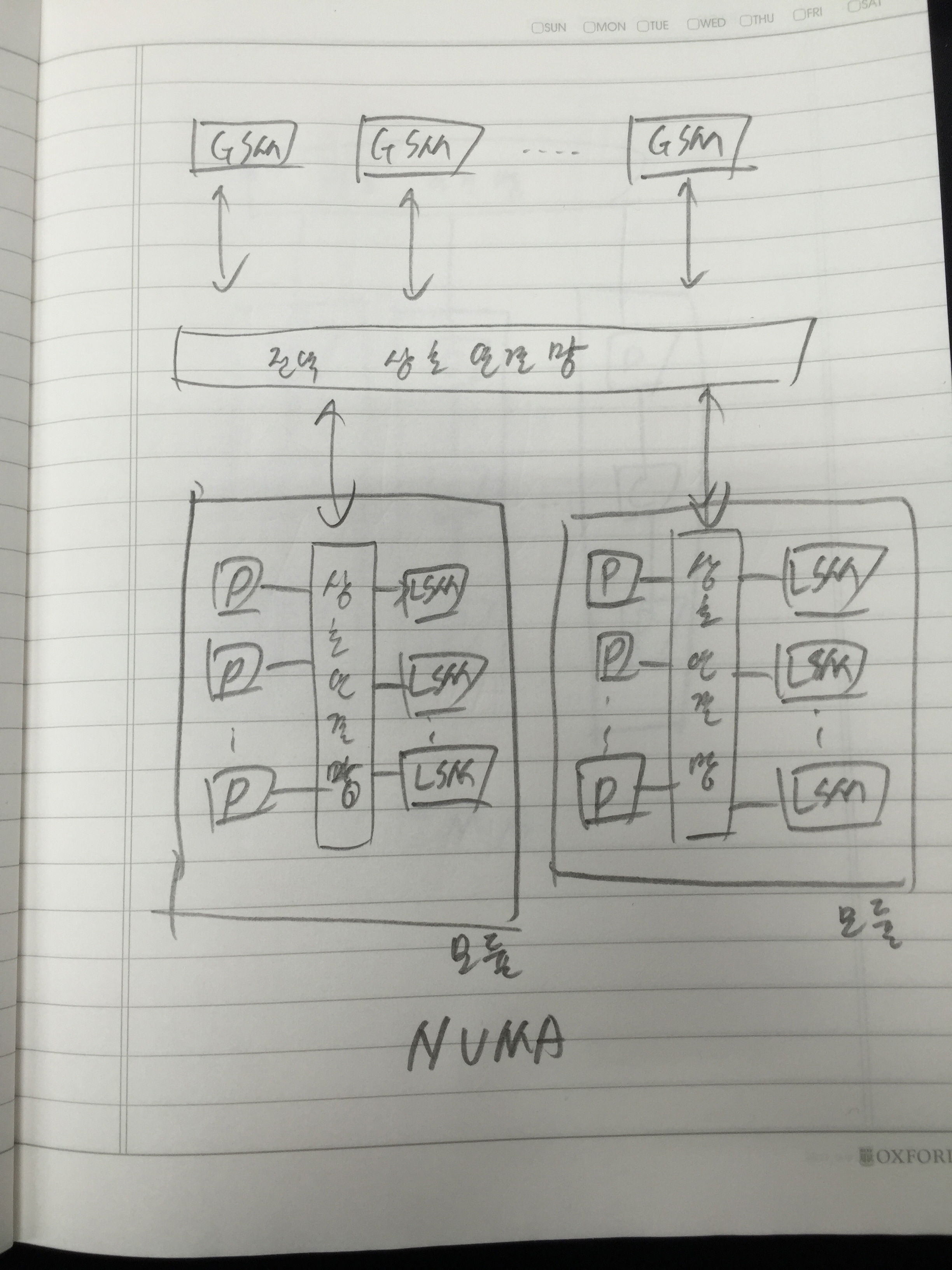
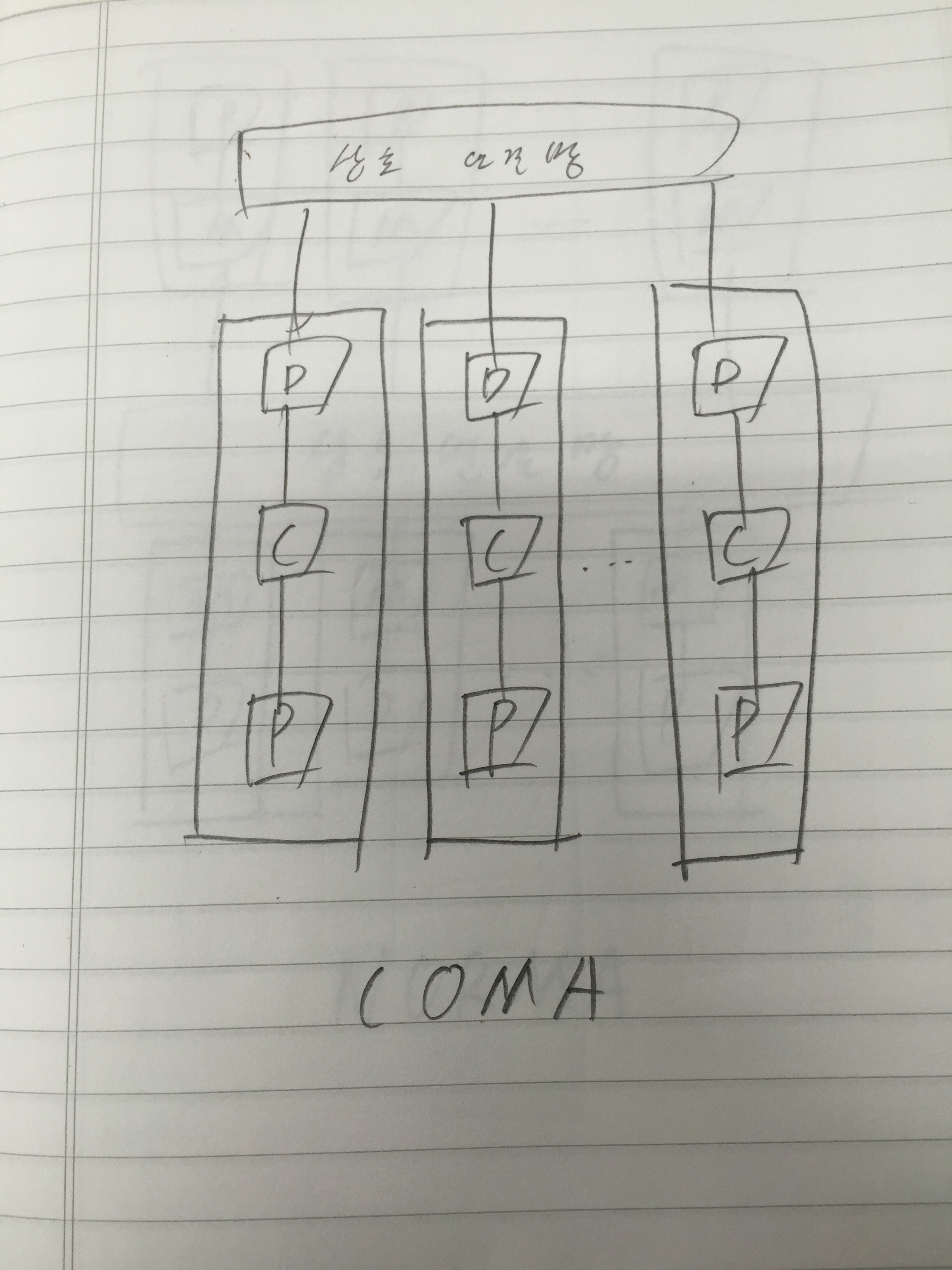
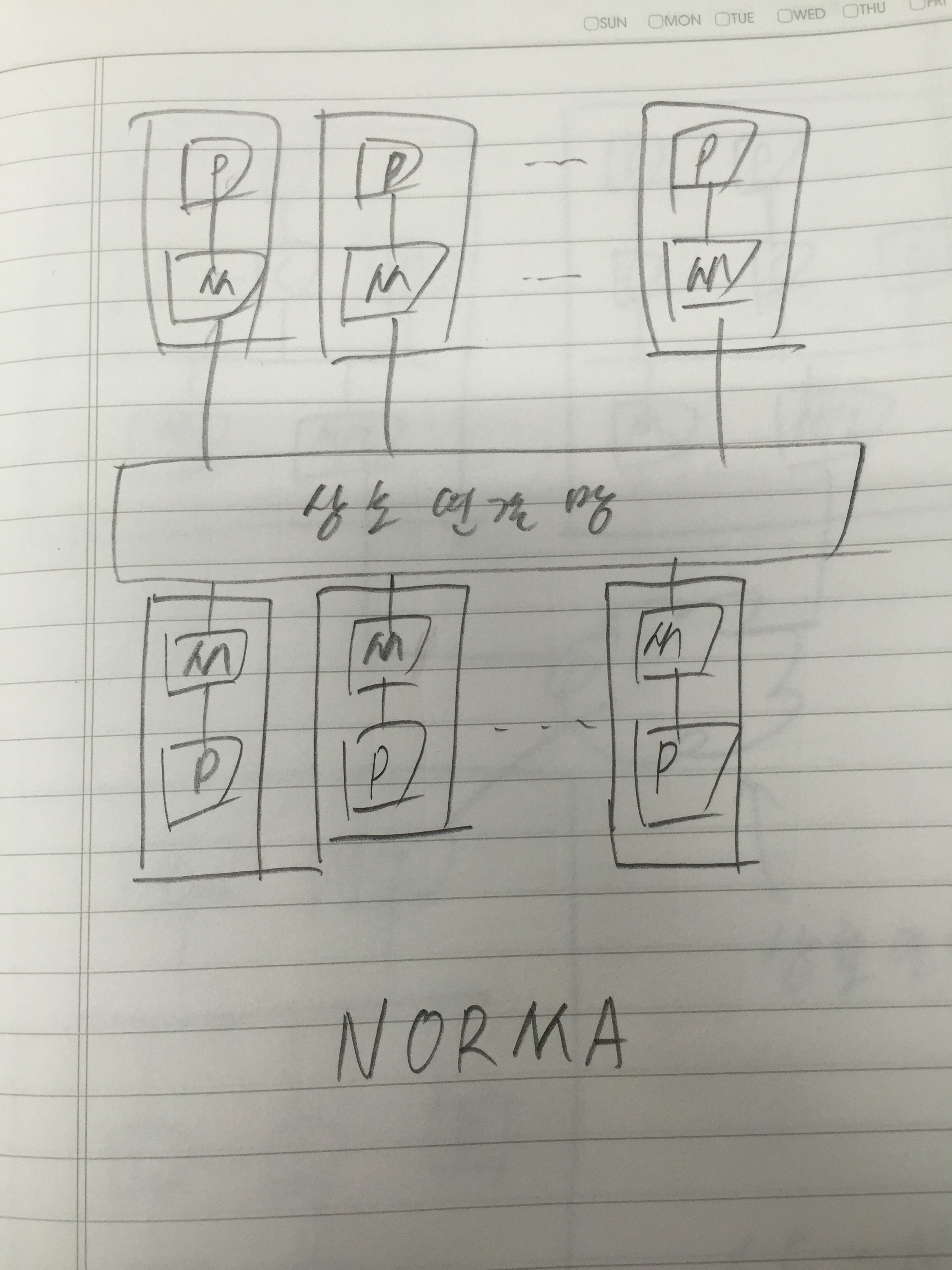
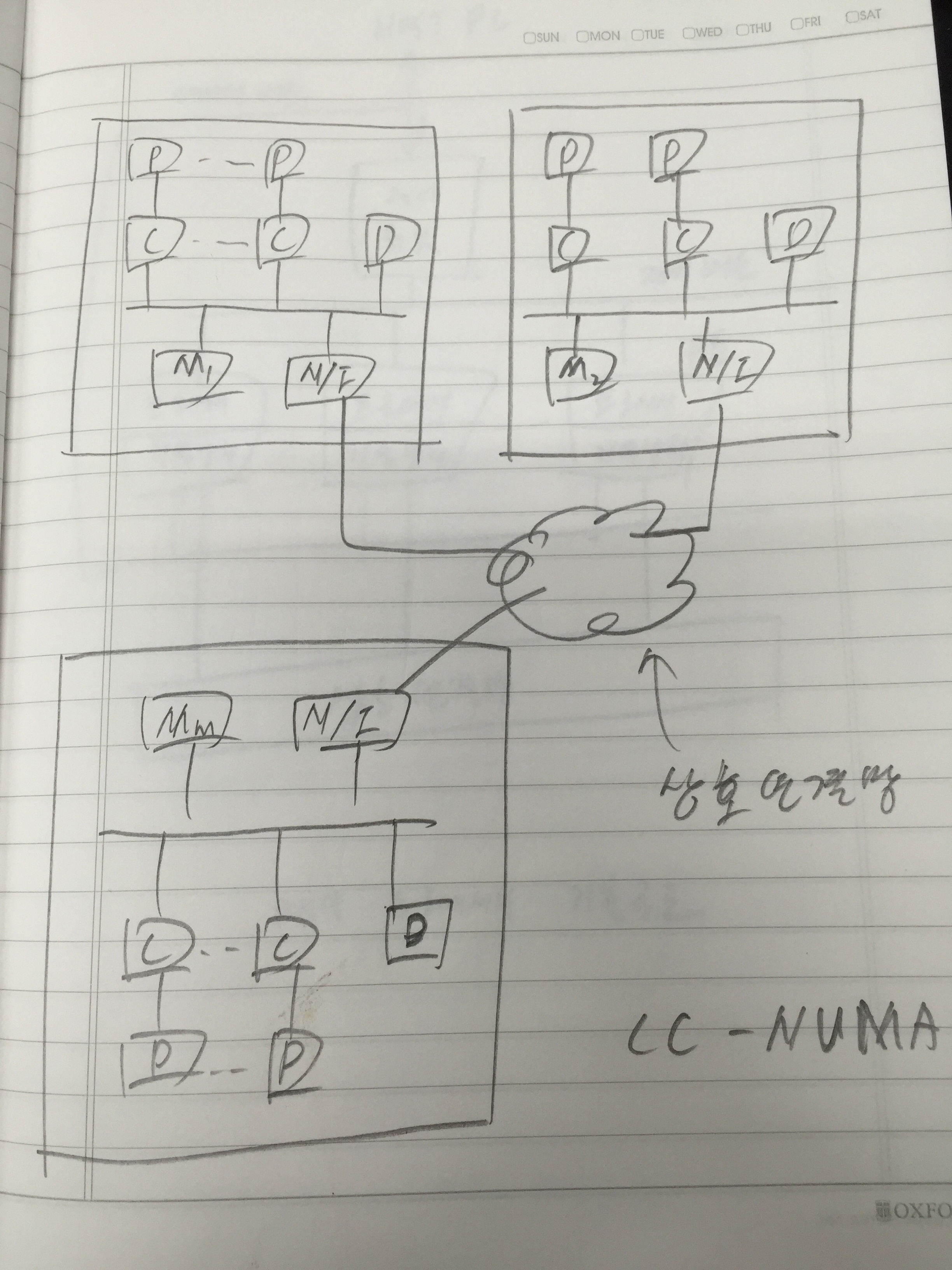
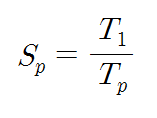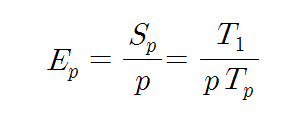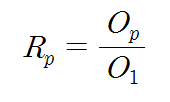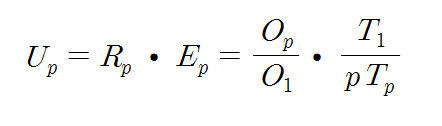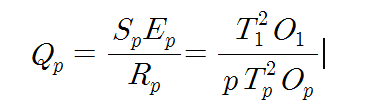아키텍트를 개발하고 연구하는 사람들한테는 몇 년 전부터 들려왔던 버즈워드이지만 서비스 개발하는 사람들한테는 이게 뭔 마법의 단어처럼 막 이용되고 있어서…..
뭔가 좀 제대로 떠들어 주는 사람이 진짜로 별로 없어지고 있다.
거기에 아직도 구식 마인드를 가진 사람들은 하드웨어가 눈에 보여야지만 되는 마인드를 가진 분들도 많은지라…
서버리스 컴퓨팅을 이해하기 위해서는 클라우드 컴퓨팅에서 주로 이야기하는 IaaS, PaaS, SaaS에 대한 이해가 어느 정도 있다는 전재 하에서 말하는 FaaS(Function as a Service)에 대한 개념도 제대로 잡혀있어야 한다. 이것은 이제 사용자가 기능을 코딩하고 빌드, 배포 및 실행 단위로 만들어 쓰는 그 과정 자체가 복잡하지 않는 상태에서 해당 기능에 대한 구현을 위주로 하는 작업을 말한다. 그러나 이를 위한 모든 아키텍트들이 전부 뒤에 숨어서 보이지 않는, 즉 서버가 보이지 않는 구조를 이루고 있는 것이 바로 서버리스(serverless) 구조인 것이다.
Raghuram Sirish씨의 교훈적인 말이 있는데, 원 글은 기억이 안나고 지금 번역된 이야기를 하도 떠들어서 번역된 이야기를 기억해서 그 이야기를 적어보겠습니다.
“90년대에는 응용 프로그램을 작성하고 하드웨어에허 실행했습니다. 그 다음 사용자가 동일한 하드웨어에서 여러 응용 프로그램을 실행할 수 있는 가상 시스템이 출시되었습니다. 그러나 각 응용 프로그램에 대해서 본격적인 운영체제들이 실행되고 있었습니다. 그러나 컨테이너의 도입으로 가볍고 민첩한 운영체제의 중복성직 기능 및 프로세스 수준으로 격리되었습니다.”
라고… (이건 제가 원문 좀 확실히 뒤져서 수정하겠습니다. 꼭!)
좀 사설이 길어졌는데, 그럼 서버리스가 정확하게 뭔데? 라고 하면 클라우드 네이티브 컴퓨팅 파운데이션에서 정의한 백서가 있습니다.
“서버리스 컴퓨팅은 서버 관리가 필요없는 응용 프로그램을 작성하고 실행하는 개념을 의미합니다. 하나 이상의 기능으로 번들 된 응용 프로그램을 플랫폼에 업로드 한 다음 즉시 필요한 요구에 따라 정확하게 실행, 확장 및 요금 부과가 이루어지는 보다 정교한 배포 모델을 말합니다.”
라고 되어 있습니다. 즉, 서버리스에서 중요하게 생각하는 것은 사용자가 프로비저닝, 관리, 확장 측면에서 서버의 비용과 복잡성에 대해서 걱정할 필요 없이 응용 프로그램을 구축, 실행할 수 있도록 하는 환경을 말합니다.
그럼 서버는 없는 것이냐고요?
아닙니다. 서버는 존재합니다. 단지 숨어 있습니다.
어디에? 클라우드 속에 숨어 있습니다.


…..말장난 아닙니다. 저 용어 자체에 속으면 안됩니다. 우리는 여전히 서버들이 연결되서 서비스화된 인터넷 속에 살고 있습니다.
진짜로 중요한 것은 개발자가 개발을 위해 생각하는 것 외에 가치에 대해서 별도로 생각하지 않아도 된다는 것이 중요한 것입니다. 사실 클라우드 환경에서 제공되는 컴퓨팅이나 API 등도 이런 내용들이 있지만, 서버리스에서는 이 점이 기존 비즈니스 레벨의 관점까지 꿰뚫고 있기 때문에 더더욱 강조되어 이야기를 합니다. 기능 관리에 대해서 주로 걱정을 하는, 즉 비즈니스적인 가치를 중요히사는 기능에 대해서 주로 생각하면서 개발을 진행합니다. 대신 그걸 구축하고 하는 데 시간 할애하는 것을 막는 겁니다. 또한 스케일링 등의 관리 작업에 대해서도 자동화 되어 있기 때문에 이를 걱정하지 않는 겁니다.
그럼 이에 대한 관리는? 플랫폼을 제공하는 측에서는 이 플랫폼을 제공하기 위해 구축해놓은 서버가 있겠죠? 바로 이걸 관리하는 것입니다. 구글 클라우드 플랫폼, 아마존 AWS, 마이크로소프트의 애저 등의 공용 클라우드 오퍼링의 경우에 이것들을 관리하고 고객이 해당 기능에 대한 실행을 확인하고 청구하면 됩니다. 개발자는 이러한 서버들과의 프로비저닝이나 상호 작용에 대해서 걱정할 필요가 없는 사설 클라우드나 데이터 센터의 경우에도 각자의 팀이 존재해서 관리를 진행할 것입니다.
이 녀석이 왜 중요할까요?
이녀석에 대해서 이야기를 주로 하는 가장 큰 이유가 바로 FaaS입니다. FaaS는 이벤트 또는 http 요청에 의해 기능이 트리거되는 이벤트 중심의 컴퓨팅 환경을 제공합니다. 개발자는 이 이벤트 또는 http 요청에 의해 트리거되는 기능을 사용하여 응용 프로그램 코드를 실행하고 관리합니다. 또한 개발자는 작은 단위의 코드를 FaaS에 배포합니다. 이 코드는 서버 또는 기타 기본 인프라를 관리할 필요 없이 확장된 개별의 작업으로 보고 필요에 따라 실행하는 실행 단위화가 됩니다.
하지만 이 FaaS가 지금은 완벽한 단계가 아닌 상황인지라…. 이 녀석을 이용하는 가장 좋은 환경이 바로 이벤트가 발생했을 때, 어플리케이션이 실행해야 하는 기능으로 동작하는 것이 좋은 사례이다. 그러나 이러한 종류의 작업들에 대해서는 여러 가지 고려 사항이 발생하게 된다.
- 독립적인 작업 단위로 구성되었을 때 비동기식, 동시성, 병렬화가 용이한가?
- 스케일링 요구 사항에 예측할 수 없는 큰 차이가 있는 산발적 수요에 대한 대처가 되는가?
- 무방비, 이회성, 즉각적인 콜드 스타트 여부
- 속도의 가속에 대한 요구와 요구에 변화하는 비즈니스가 역동적으로 발생하는가?
어려운 것이다…;ㅅ;
그렇지만 서버리스 자체는 새로운 형태의 기술이자 패러다임이다. VM과 컨테이너가 앱 개발 및 배포 모델을 변화시켰던 것과 마찬가지의 수준으로 다가올 것이다. 또한 FaaS도 극적인 변화를 가져오는 요소가 될 수 있다. 단, 이것들이 아직 초기 단계이기 때문에 정확하게 알아야 한다. 안그러면 기존의 영역들에 대해 애매모호하게 묻혀서 이용될 것이다.