음.. 뭐랄까. 도커에는 이미지와 컨테이너라는 개념이 있는데, 이 기본적인 부분에 대해서도 사실 좀 나눠서 설명할 수 있느냐 아니냐에 따라서도 이야기가 좀 달라집니다. 조금만 보면 금방 다른 이야기라는 것이 알 수 있지만, 한번의 설명글이 있는 쪽이 좀 더 좋겠군요. 우선 이미지가 좀 많이 좋은 것이 있어서 그걸 가져와서 설명을 하겠습니다.
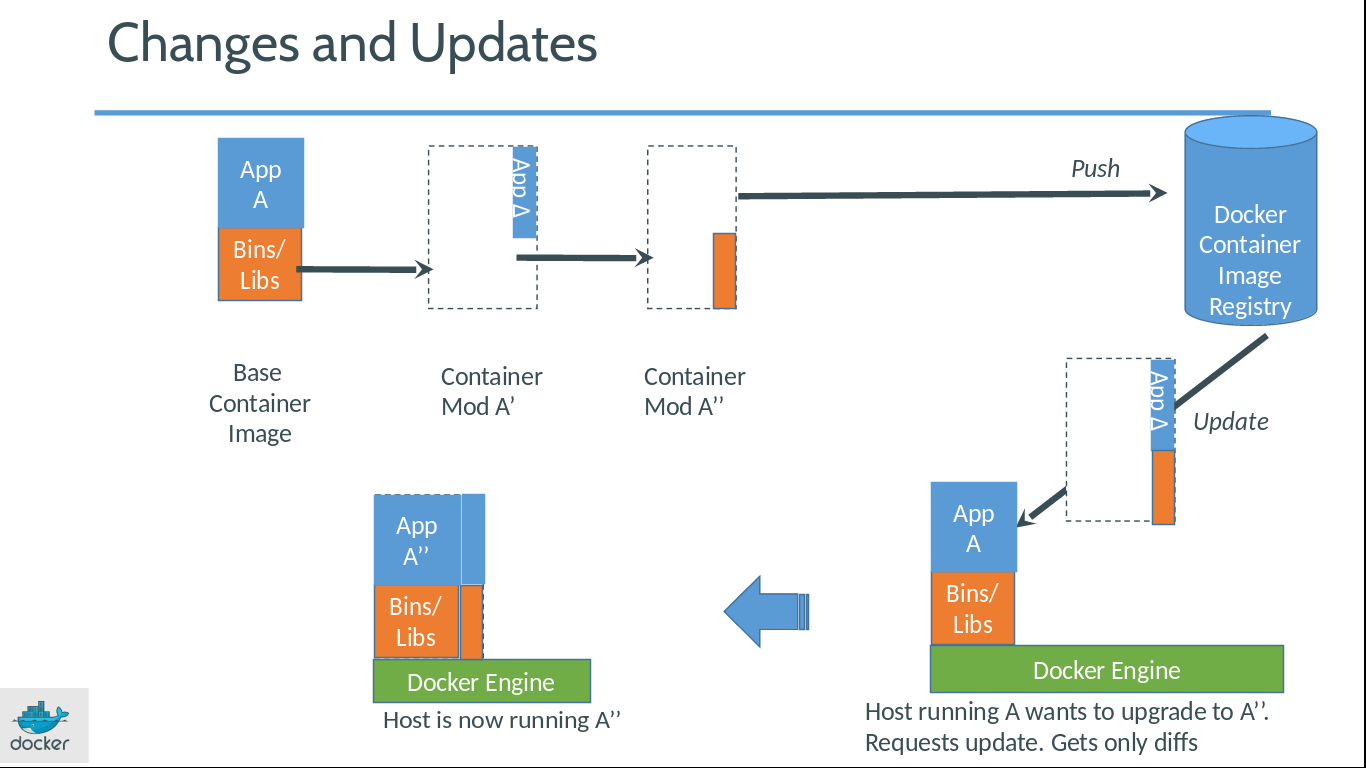

우선은 가장 기본이 되는 베이스 이미지가 있습니다. 이는 리눅스 배포판의 유저랜드만 설치된 파일을 말합니다. 보통은 리눅스 배포판 이름으로 구성되어 있습니다. 아니면 리눅스 배포판 유저랜드(사용자 공간)에 Redis나 Nginx 등이 설치된 베이스 이미지도 만들 수 있습니다. 그래서 도커의 이미지라고 하면 주로 베이스 이미지에 필요한 프로그램과 라이브러리, 소스를 설치한 뒤 파일 하나로 만들어낸 것을 가리킵니다. 각 리눅스의 배포판 이름으로 된 베이스 이미지는 배포판 특유의 패키징 시스템을 이용할 수 있습니다. 우분투라면 apt-get을, 레드햇 계열이라면 요즘은 DNF를 이용하겠군요. 또한 원하는 베이스 이미지는 직접 만들어서 사용할 수 있습니다.
근데 이것이 매번 베이스 이미지에다가 필요한 프로그램과 라이브러리, 소스 등을 추가하다 보면 용량이 큰 이미지가 지속적으로 생길 것이라고 생각하는데, 위의 그림과 같이 변화된 곳만 별도로 이미지가 생기고, 실행할 때에는 베이스 이미지와 바뀐 부분이 합쳐져서 실행됩니다. 그래서 도커는 초기 환경이나 업데이트된 환경이나 그렇게 큰 구조를 가지지 않습니다.
아래에는 도커 이미지에 대한 버전 업데이트의 의존 트리를 보여줍니다. 구조를 보시면 개발자들이 개발한 소스코드의 버전 관리 트리와 비슷한 구조인 것을 보실 수 있습니다.


거의 git하고 비슷하죠. 16진수의 특정 ID로 구분되고, 각 이미지에 대해서는 독립적인 형태로 진행됩니다. consumer, nodeflakes, nodeflakes-server로 최종적인 구조에서 별도의 작업 단위로 branch가 진행되어 조금씩 수정되어 이용되는 구조인 듯 합니다. 정리하자면, 도커는 이미지를 통째로 생성하지 않고, 바뀐 부분에 대해서만 생성을 진행한 뒤, 부모 이미지를 계속 참조하는 방식으로 동작합니다. 도커에서는 이를 “레이어”라고 합니다.
도커의 이미지는 파일입니다. 그렇기 때문에 저장소에 올린 뒤에 다른 곳에서도 받을 수 있습니다. 그리고 저장소에 올릴 때에는 자식 이미지와 부모 이미지를 함께 올립니다. 받을 때도 똑같습니다. 이후에는 수정된 이미지만 주고 받는 구조입니다.
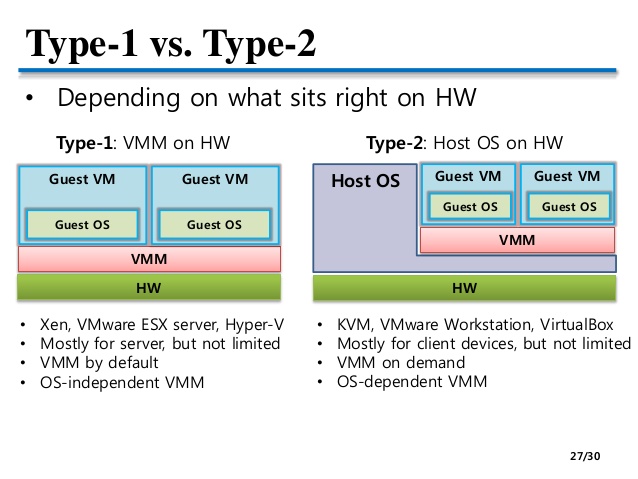
이미지에 대한 설명은 여기까지이고 이제 컨테이너에 대한 설명을 하겠습니다. 컨테이너는 이미지를 “실행한 상태”입니다. 이미지로 여러 개의 컨테이너를 만들 수 있습니다. 운영체제로 생각해 본다면 이미지는 [실행 파일]이고 컨테이너는 [프로세스]입니다. 이미 실행된 컨테이너에서 변경된 부분을 이미지로 생성할 수도 있습니다. 이렇게 운영체제와 비교해서 보니, 도커는 특정 실행 파일 또는 스크립트를 위한 특정 실행환경이라고도 볼 수 있겠군요. 그러면 이제 앞에서 봤던, 아래의 그림과 같은 설명이 이해가 되는 겁니다. 하이퍼바이저와 게스트 운영체제의 자리를 도커가 가지고 가는 구조죠.


리눅스와 유닉스 계열에서는 파일 실행에 필요한 모든 구성요소가 잘게 쪼개져 있습니다. 이는 시스템 구조가 단순해지고 명확해지는 장점이 있습니다만 의존성 관계를 해결하기 어려워지는 단점을 가지고 있습니다. 그래서 리눅스와 유닉스 계열에서는 각 배포판마다 미리 컴파일 된 형식으로 프로그램을 배포하고 그 의존성을 미리 검사할 수 있는, 일명 패키지라는 시스템이 만들어지게 됩니다. 하지만 서버를 실행할 때마다 일일이 소스를 컴파일하거나 패키지를 설치하고 설정하고 하는 작업은 상당히 귀찮은 작업입니다. 서버 대수가 많아지면 더 할 말이 없습니다. 이때 도커 이미지를 사용하면 실행할 서버가 몇 대든간에 이미지를 실행하여 컨테이너를 계속 만들어 쓰면 됩니다.