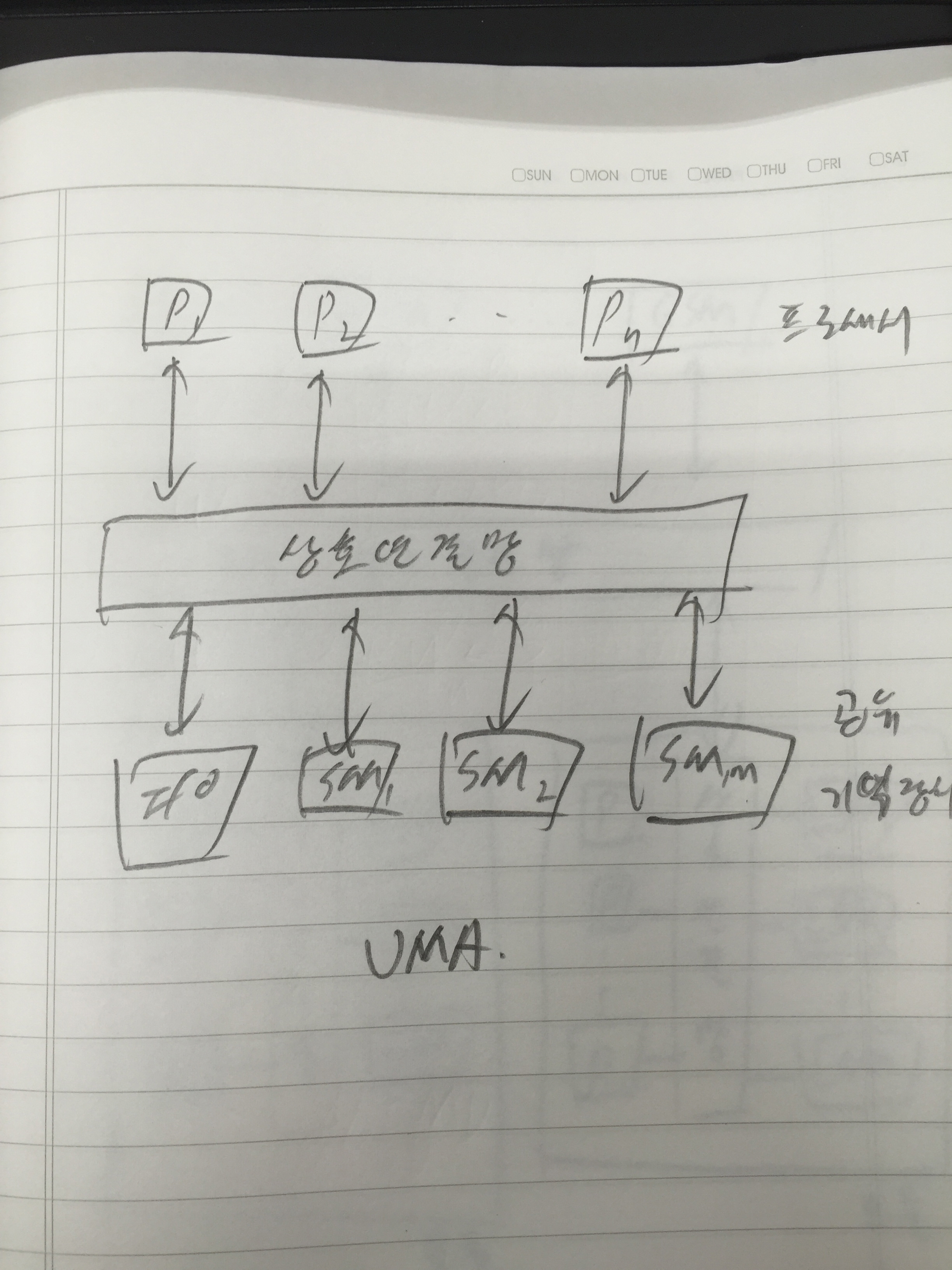
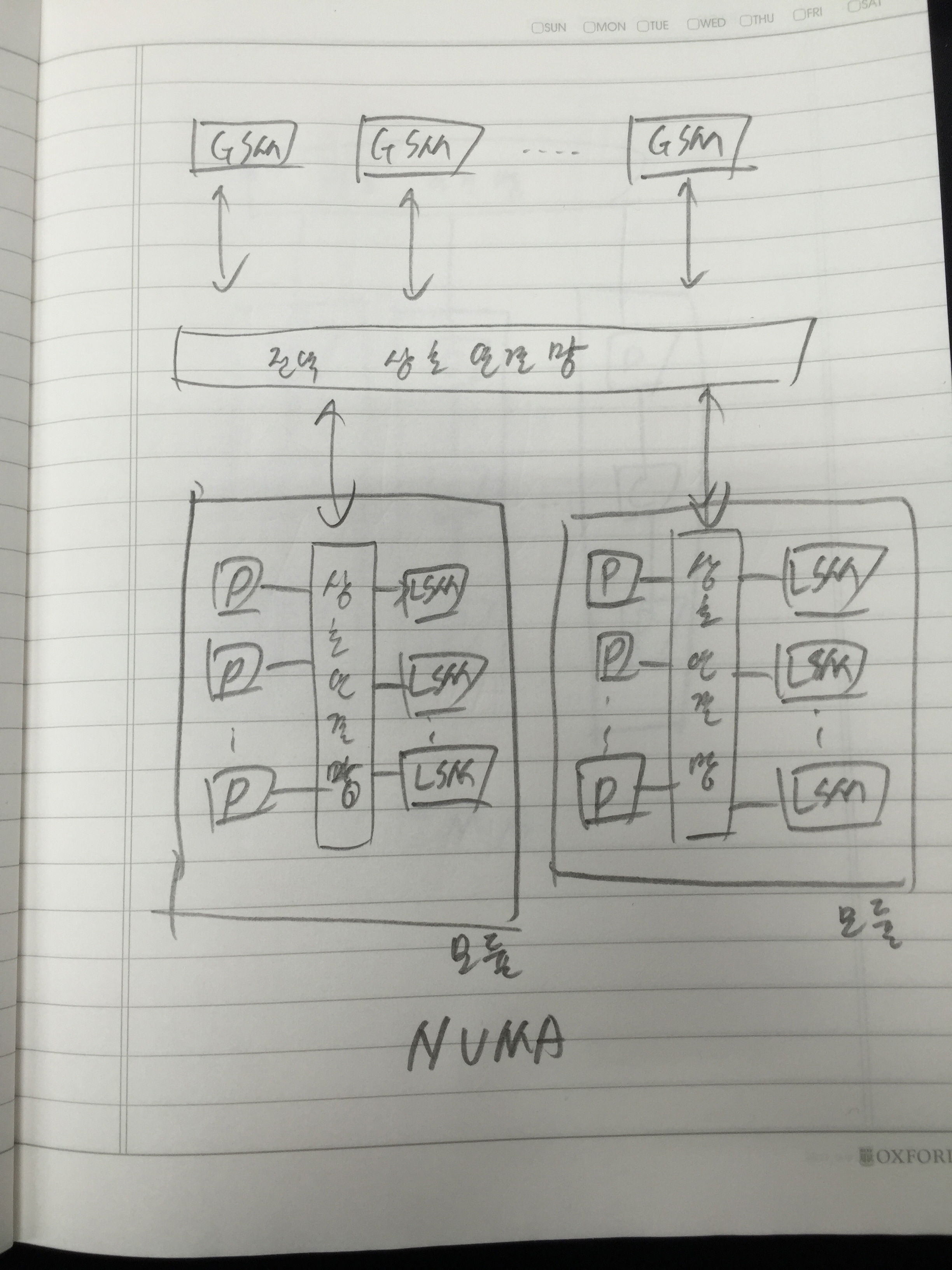
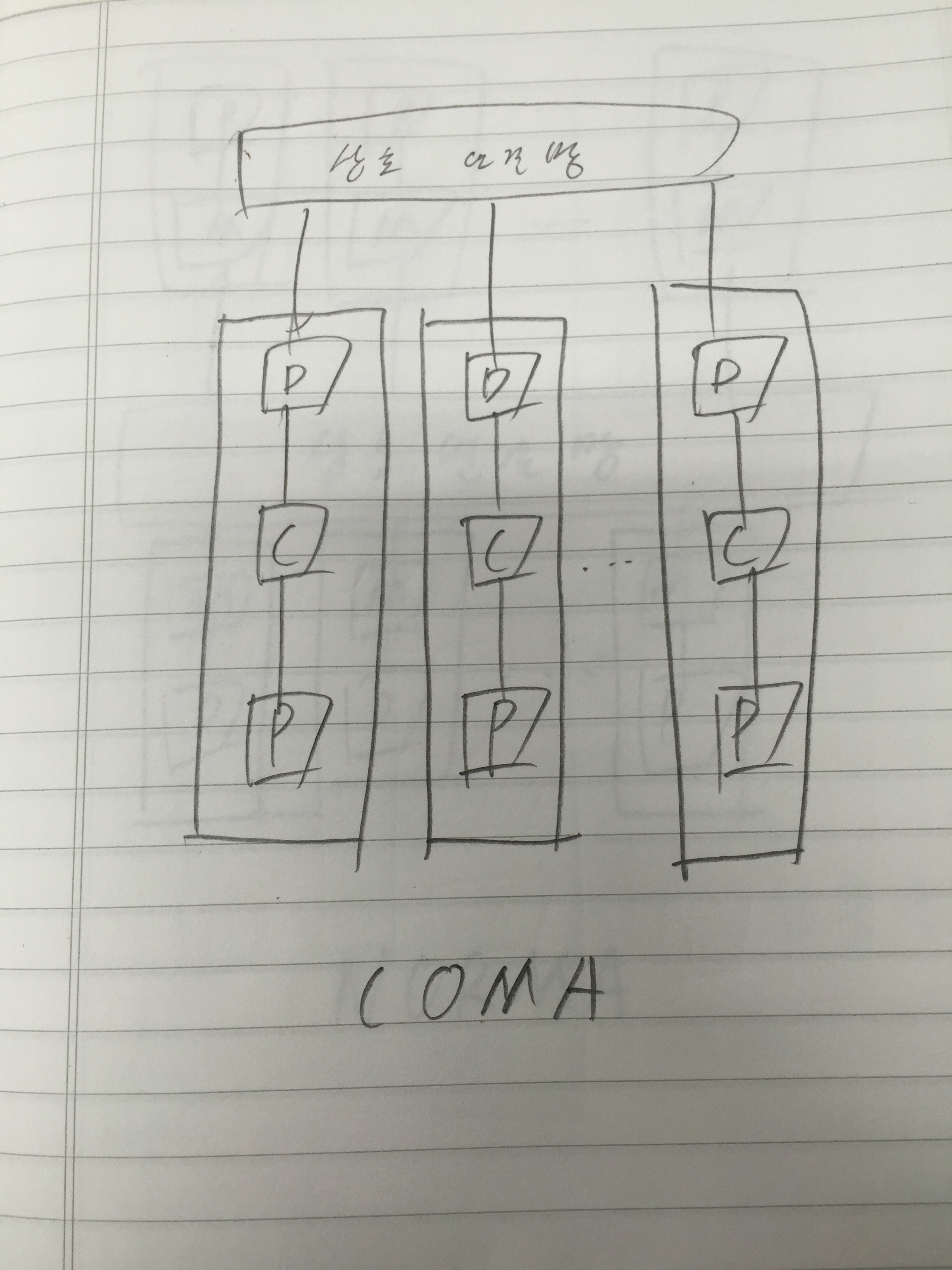
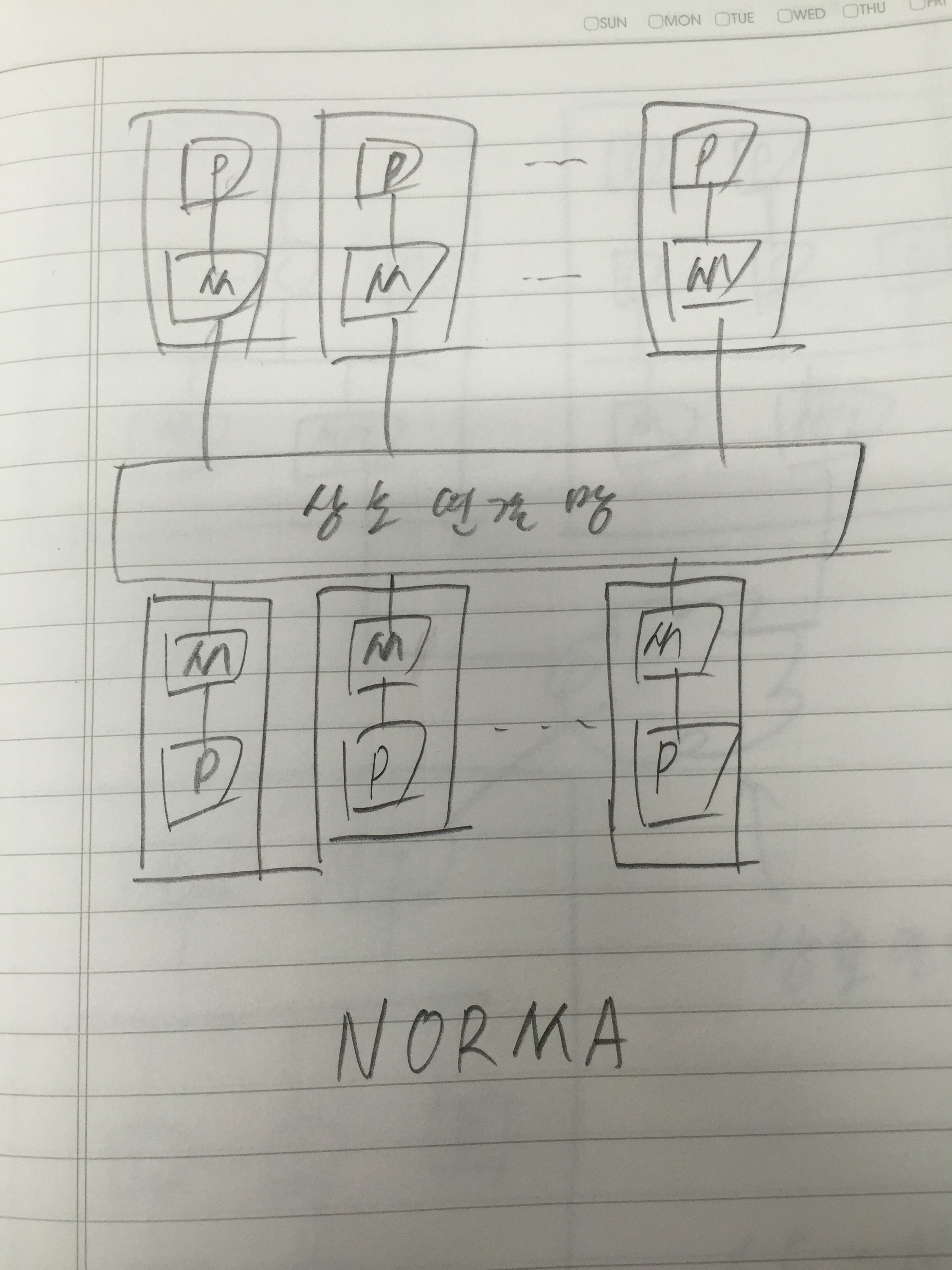
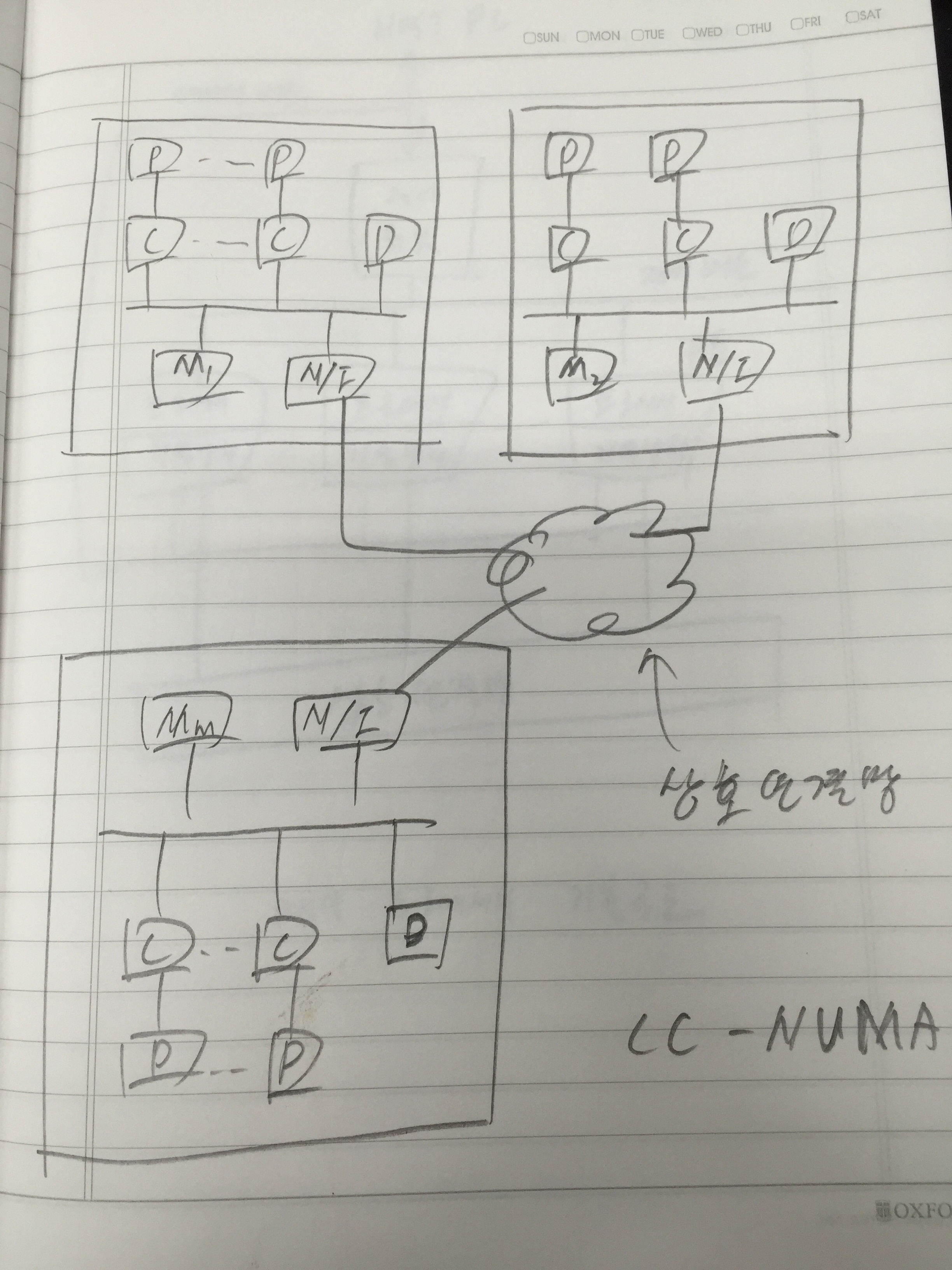
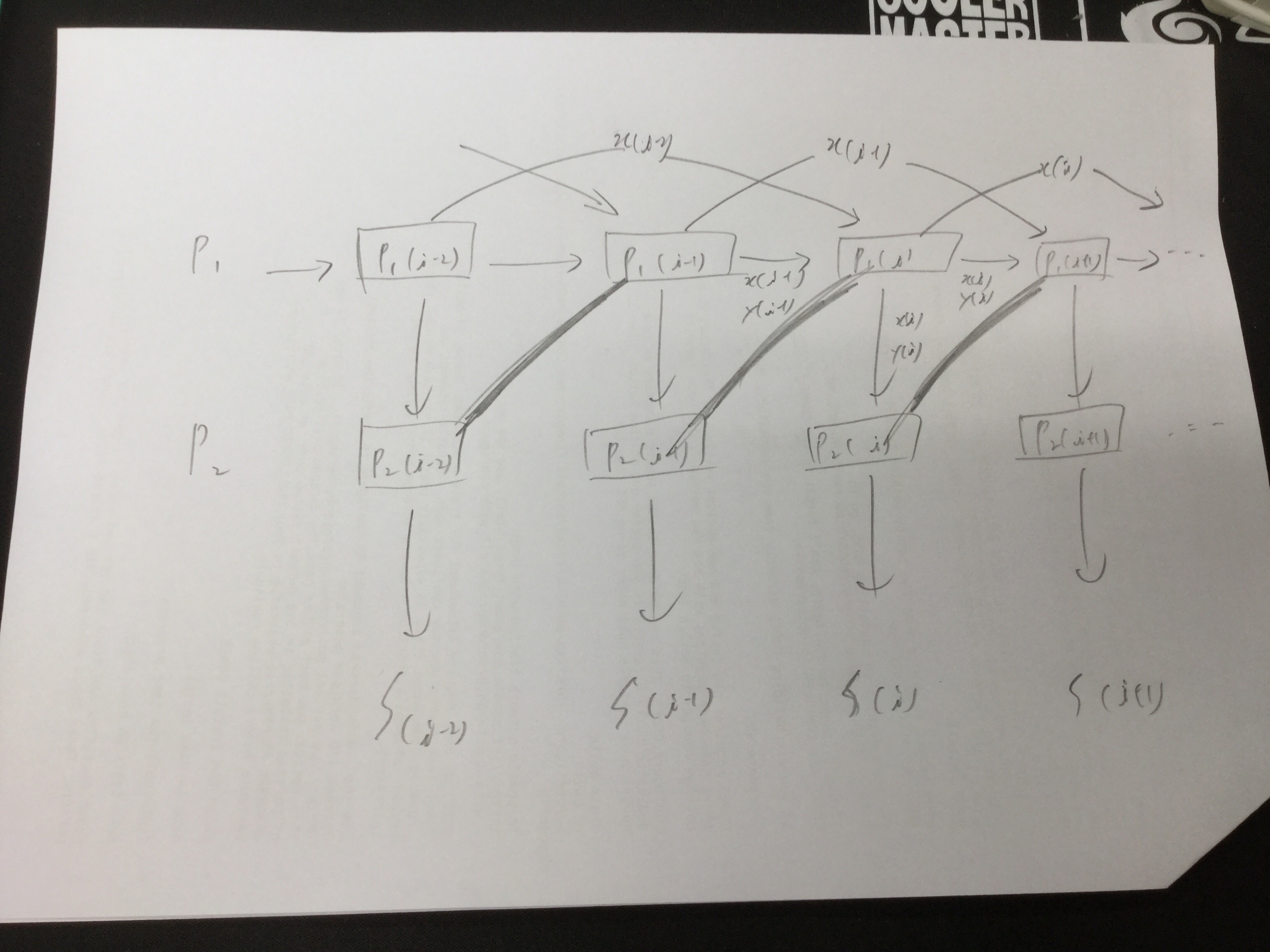
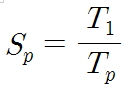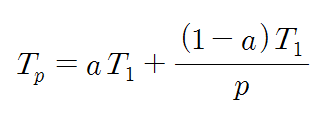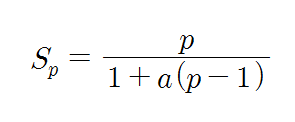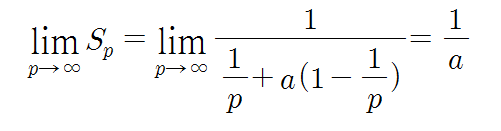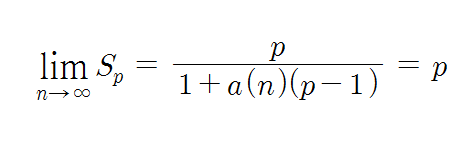병렬 컴퓨터는 프로세서들을 포함한 많은 하드웨어 자원들을 중복적으로 사용하여 구성하는 시스템이기 때문에, 단일 프로세서 시스테보다 성능이 높아지는 것은 당연한 일이다. 그러나 여러 가지 요인들에 의하여 성능 향상이 그에 비례하여 높아지지는 못하고 있다. 따라서 시스템 개발자들은 투자한 가격 대 성능비를 높이기 위하여 많은 노력을 계속하고 있다. 그를 위해 병렬 컴퓨터의 속도와 성능 향상 및 효율에 대한 척도에 대해서 살펴봐야 한다.
- 처리 속도
처리 속도는 시스템에서 단위 시간당 처리할 수 있는 연산들의 수로써, 여러 척도들이 사용되고 있다.
MIPS(Millions of Instructions Per Second): 초당 실행 완료되는 명령어들의 수를 나타내는 단위이다. 예를 들어, 1MIPS 및 100MIPS는 각각 초당 백만 개 및 1억 개의 명령어들을 실행하는 속도를 나타낸다. 그리고 1GIPS = 1000MIPS 로서, 초당 10억 개의 명령어들을 실행하는 속도이다. 8개의 프로세서들로 구성된 시스템은 퇴대 80MIPS의 실행 속도를 가질 수 있다. (여러 요인들에 의하여 실제로는 그보다 더 낮아진다.) 이 척도는 SIMD에서는 하나의 명령어가 실행되는 동안에 여러 개의 데이터들에 대한 연산들이 동시에 수행되기 때문이다.
MFLOPS(Millions of Floating-Point Per Second): 부동 소수점 연산에 대한 처리 속도를 나타내는 단위이다. 이 척도는 주로 과학계산 응용들을 처리하는 슈퍼컴퓨터의 처리 속도를 나타내는 데 사용되는데, 최근에 슈퍼컴퓨터로 분류되고 잇는 시스템들은 데부분이 TFLOPS 이상의 처리 속도를 기본으로 가지고 있다.
LIPS(Logical Inferences Per Second): 위의 두 척도들은 모두 수치 계산의 처리 속도를 나타내는 반면, LIPS는 인공지능 프로그램의 처리 속도를 나타내는 척도이다. 즉, 시스템이 단위 시간당 처리하는 논리 추론들의 수를 나타낸다.
- 속도 향상
속도 향상은 앞에서 설명하였던 바와 같이, 프로세서 수가 p개인 병렬컴퓨터가 단일 프로세서 시스템에 비하여 몇 배의 처리 속도를 가지는지를 나타내는 척도이다. 어떤 프로그램을 단일프로세서 시스템에서 처리하는 데 걸리는 시간을 T1이라 하고, 동일한 프로그램ㅁ을 p개의 프로세서들을 가진 병렬컴퓨터에서 처리하는 데 걸리는 시간을 Tp라고 할 때, 속도 향상 Sp를 나타내는 식을 다시 쓰면 아래와 같다.
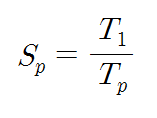

Sp는 일반적으로 프로세서 수보다 더 작은데, 그 주요 요인들로는 불균등한 작업부하 및 각종 병렬처리 오버헤드들을 들 수 있다.
- 효율
병렬컴퓨터에서 효율이란 아래의 식과 같이 속도 향상과 프로세서의 수의 비율로 정의된다.
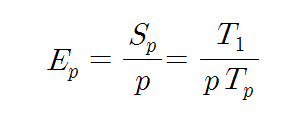

예를 들어, p=10인 병렬컴퓨터를 이용하여 8배의 속도 향상을 얻었담면, Ep=0.8이 된다. (80%) 즉, 효율은 투자 비용에 따른 효과를 나타내는 척도이다.
- 중복성
중복성이란 어떤 응용 프로그램ㅁ을 병렬컴퓨터에서 처리하는 경우에 수행되는 연산들의 수와 단일 프로세서 시스템에서 처리하는 경우에 수행되는 연산들의 수의 비율을 말한다. 이 식은 아래와 같이 표현할 수 있는데, 이 값은 항상 1보다 크다. 그 이유는 병렬처리를 위하여 별도의 동작들(프로세서 동기화 및 프로세서 간 통신 등)이 추가적으로 수행되어야 하기 때문이다. 결과적으로, 그 연산들을 처리하는 만큼 시간이 더 소모됨으로써 속도 향상과 효율이 저하되는 것이다.
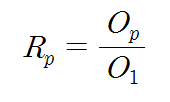

- 시스템 이용률
시스템 이용률은 아래 식과 같이 표현된다.
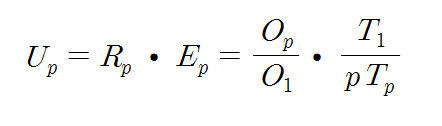

이것은 하드웨어 자원들이 어느 정도 효율적으로 사용되는지를 나타내는 척도이다. 즉, 프로그램을 처리하는 전체 시간 동안에 하드웨어 자원들이 실제 사용중인 상태에 있었던 비율을 가리킨다.
단일 프로세서 시스템에서는 O1 = T1인 것으로 가정한다면, 식은 더 간단해진다. 병렬 컴퓨터의 시스템 이용률은 대부분 1보다 더 적은데, 그 주요 이유는 프로세서들이 처리할 작업량이 균등하지 못하여 일부 프로세서들은 대기 상태에 있게되는 것과, 데이터 의존성으로 인하여 다른 프로세서로부터 데이터가 전송되어 올 때까지 기다려야 하는 경우가 있기 때문이다. 이 부분은 나중에 별도로 상세 설명이 필요하다.
- 병렬처리의 질
병렬처리가 어느 정도 효과적으로 이루어졌는지를 나타내는 질을 이전까지 작성한 식을 토대로 하여 종합적으로 작성하면 아래와 같이 정리된다.
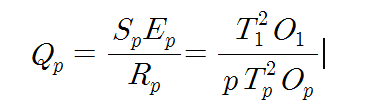

즉, 병렬처리의 질은 속도향상과 효율에 비례하며, 중복성에는 반비례한다. 여기서 Ep는 항상 1보다 작고, Rp는 1과 p 사이의 값을 가지므로, Qp의 상한값(limit)은 속도 향상인 Sp가 된다.
일단 이정도의 내용만 가지고 병렬 컴퓨터의 성능 척도에 대해서 간단하게 살펴볼 수 있었다.