병렬 프로그래밍이 여러곳에서 말 나오면서 제일 많이 들어봤을 법칙이다. 병렬 처리를 이용하여 얻을 수 있는 속도 향상에 대한 한계를 제시한 법칙이다.
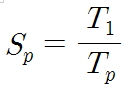
직렬 알고리즘 중에서 반드시 순차적으로 처리되어야 하는(= 병렬화 할 수 없는) 부분의 비율을 Amdahl의 비율이라 하는데, 여기서는 a라고 정하고 이야기를 진행한다. 실제 시스템에서 병렬화 할 수 없는 부분에 해당하는 예를 보면, 프로그램이나 데이터를 다운로드 하는 데 걸리는 시간, 운영체제의 커널 실행 시간 혹은 연산들 간에 선행 관계가 존재하는 경우 등등이 있다. a를 고려하면 Tp는 아래와 같은 식이 된다.
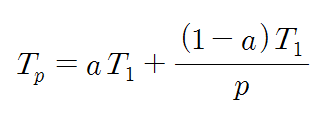
그를 통해 속도 향상은 아래 식으로 표현된다.
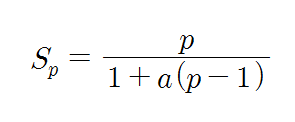
그런데, 만약 사용 가능한 프로세서의 수가 무한대라고 가정하면, 속도 향상의 비율값은 아래와 같아진다.
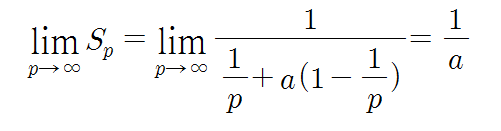
즉, 병렬처리를 이용하여 얻을 수 있는 최대 속도 향상은 a값의 역수가 된다. 예를 들어, 계산할 알고리즘 중에 반드시 순차적으로 처리해야 할 부분이 5%가 있다면, 프로세서가 무한히 많이 사용되더라도 속도 향상은 최대 1/0.05 = 20배 밖에 되지 못한다는 것이다. a값이 큰 경우에는 프로세서의 수가 증가하더라도 속도 향상은 거의 얻지 못하고 포화되며, 결과적으로 시스템 효율이 크게 떨어진다는 것을 알 수 있다.
그러나, Amdahl의 법칙도 처리할 응용의 특성에 따라 해석이 달라질 수 있다. 예를 들어, 대부분의 공학 및 과학 계산 문제들에서 Amdahl의 비율 a는 문제의 크기 n에 따라 값이 달라지게 된다. 여기서 문제의 크기란 선형방정식의 차수, 즉 변수의 개수에 해당한다. 그 크기가 증가하면 그만큼 계산량이 증가하게 되는 반면에, 순차적으로 처리되어야 하는 부분은 거의 일정하게 고정되기 때문에 a값은 상대적으로 감소한다. 이렇게 되면 즉.
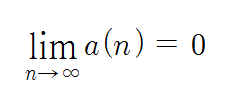
이 될 수 있다. 따라서 그러한 응용들을 처리하는 경우에 문제의 크기가 무한대로 커진다고 가정하면, 속도 향상은 아래의 식과 같이 정의될 수 있다.
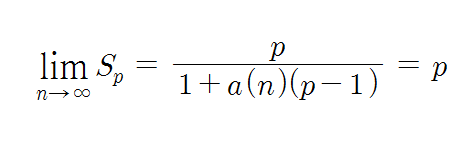
이러한 예는 실제로 미국의 Sandia 국립연구소에서 몇 가지 응용들을 1024개의 프로세서들로 구성된 하이퍼큐브시스템에서 처리한 결과, 거의 선행적인 성능 향상을 얻을 수 있다는 것을 입증하였다. (유명한 논문이다. 단, 작성날짜가….ㅠㅠ J.L.Gustafson, “Reevaluating Amdahl’s Law”, Communications of the ACM, Vol31, No. 5, Maay 1988, pp 532-533)
결론적으로, 큰 응용 문제가 효율적인 방법으로 처리되는 이상적인 경우에는 Amdahl의 법칙과는 달리, 프로세서의 수에 비례하는 선형적인 속도 향상을 얻을 수 있다는 것이다. 여기서 주의해야 할 사항은 문제의 크기가 증가하면 기억장치의 용량도 증가해야 하며, 그렇지 않은 경우에는 속도 향상이 프로세서의 수보다 기억장치 용량에 의해 더 큰 영향을 받을 수 있다는 점이다. 이 부분은 이후에도 지속적으로 설명하겠다.
병렬 컴퓨터의 성능 한계에 대한 초기의 비관적인 내용들을 확인해보았다. 이런 예측들은 응용 문제의 크기가 증가하고 효율적인 통신 매커니즘이 설계되면 충분히 개선될 수 있는 것이 입증되고 있었고, 그에 대해서도 현재 실제로 입증되고 있다. 그래서 최근의 개발된 거의 모든 고성능컴퓨터시스템들은 병렬처리 기술을 사용하고 있다.