make 파일을 작성할 때는 컴파일에 필요한 각 처리 단계와 의존성을 분명히 지정해주었다. 이와 같이 make가 해야 할 일을 분명히 지정하는 것을 명시적 규칙(explicit rules)이라고 한다. 이와 반대로, make 내에 미리 정의된 규칙을 이용해 make 파일을 단순화시키는 규칙을 암시적 규칙(inference rules)이라고 한다.
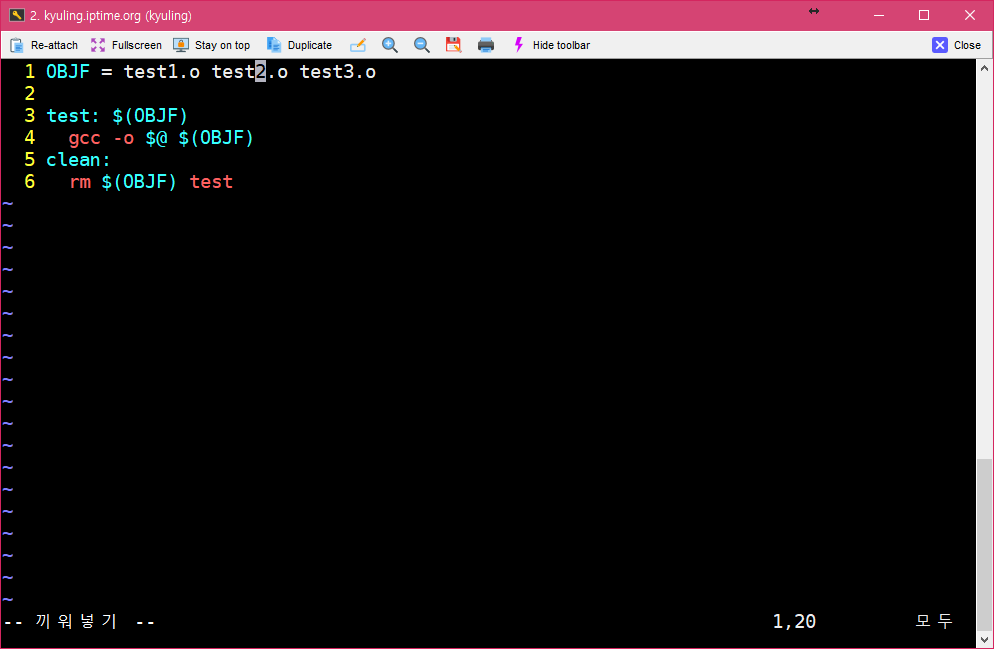
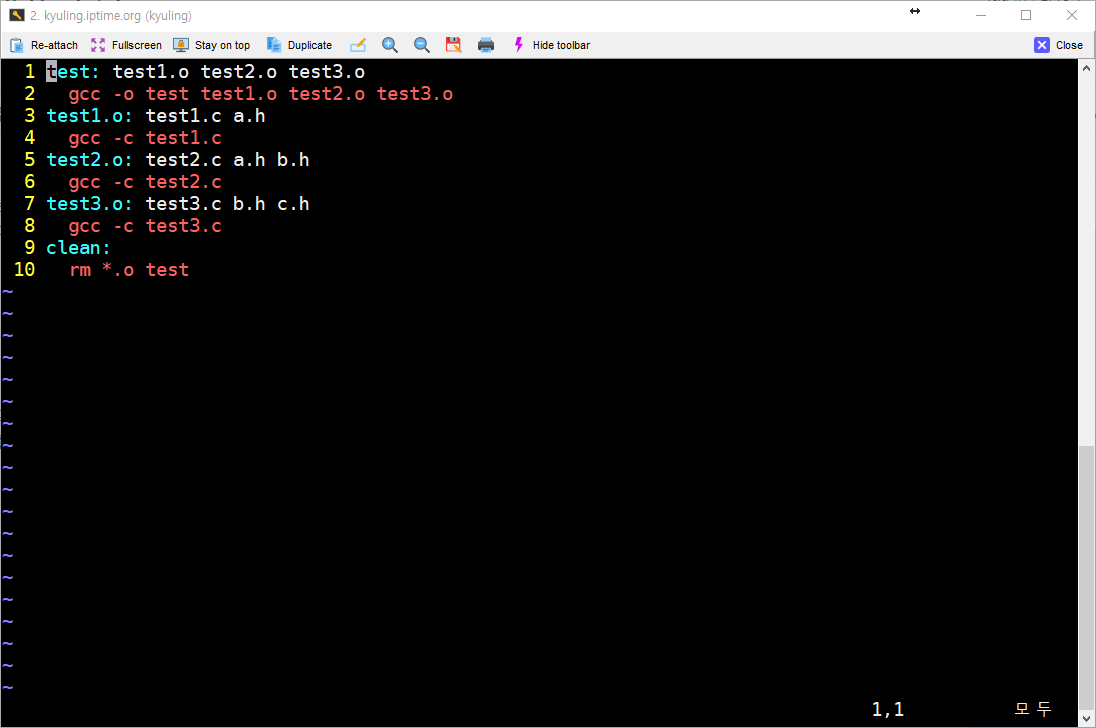
이를 보여주기 위해서 전에 작성하던 make 파일을 상당히 줄여서 예시로 보여주겠다.
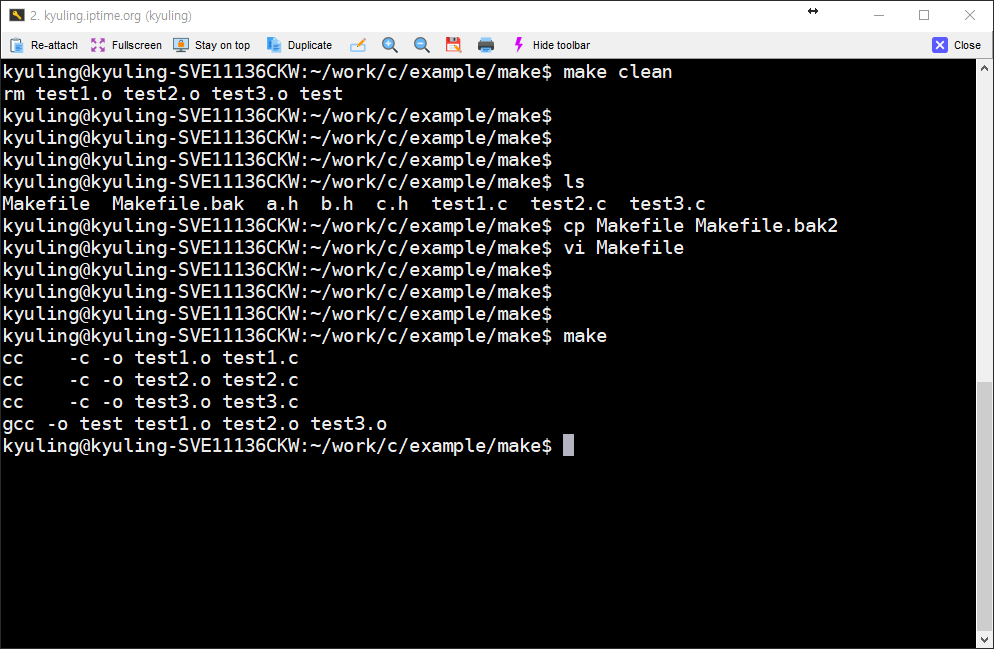
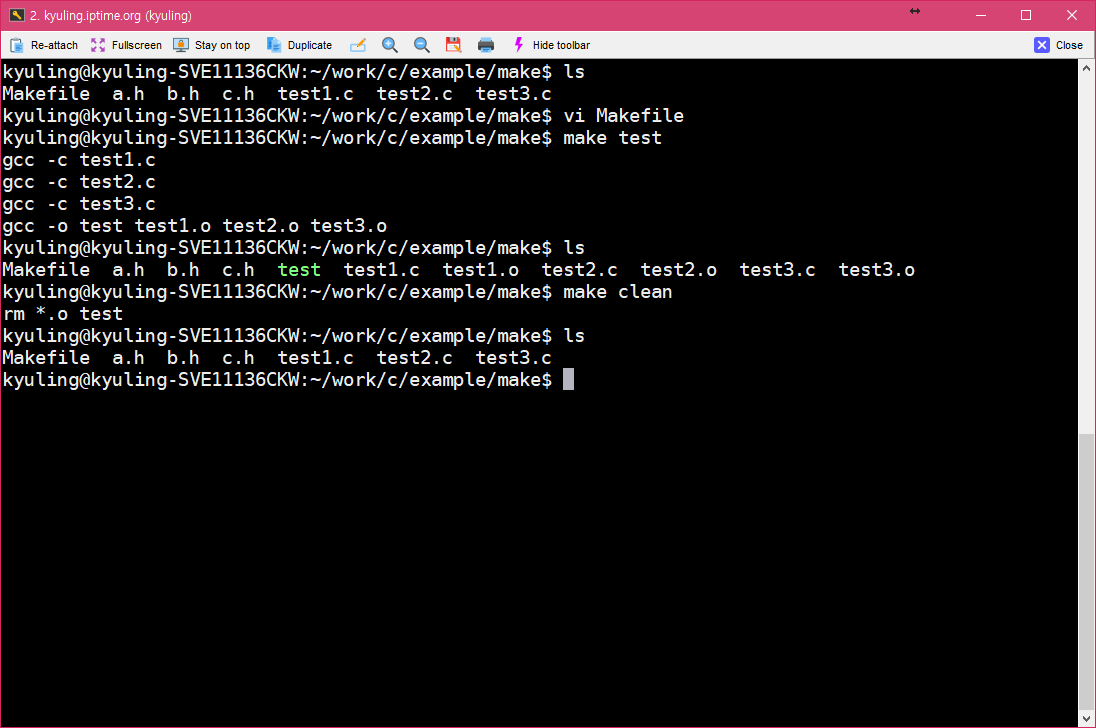
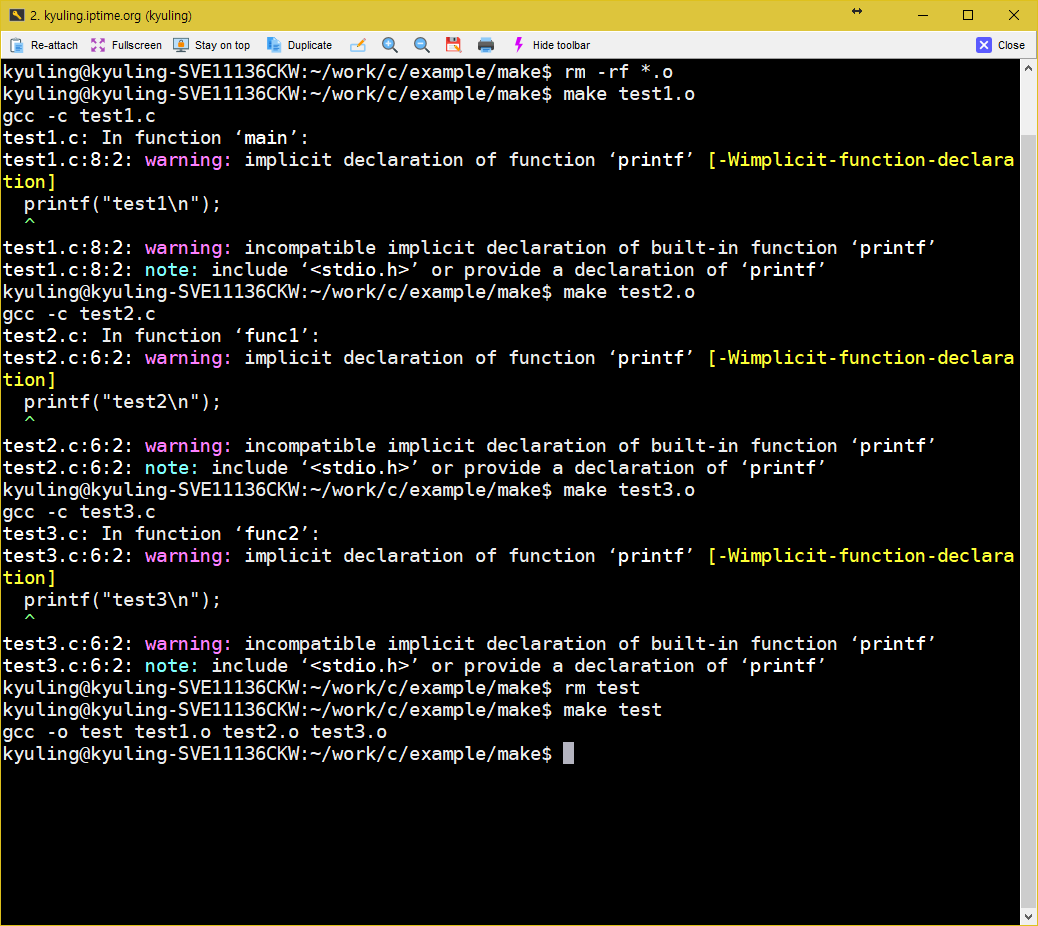
소스 파일에서 오브젝트 파일로 컴파일하도록 하는 단계를 빼고 그냥 바로 test를 오브젝트로 만들어서 빌드하도록 하였다. 전에 글들의 코드를 보고 비교하면 상당히 단축시킨 것을 볼 수 있다. 이 코드는 실행하면 그대로 컴파일 된다. 그 결과가 아래의 화면이다.
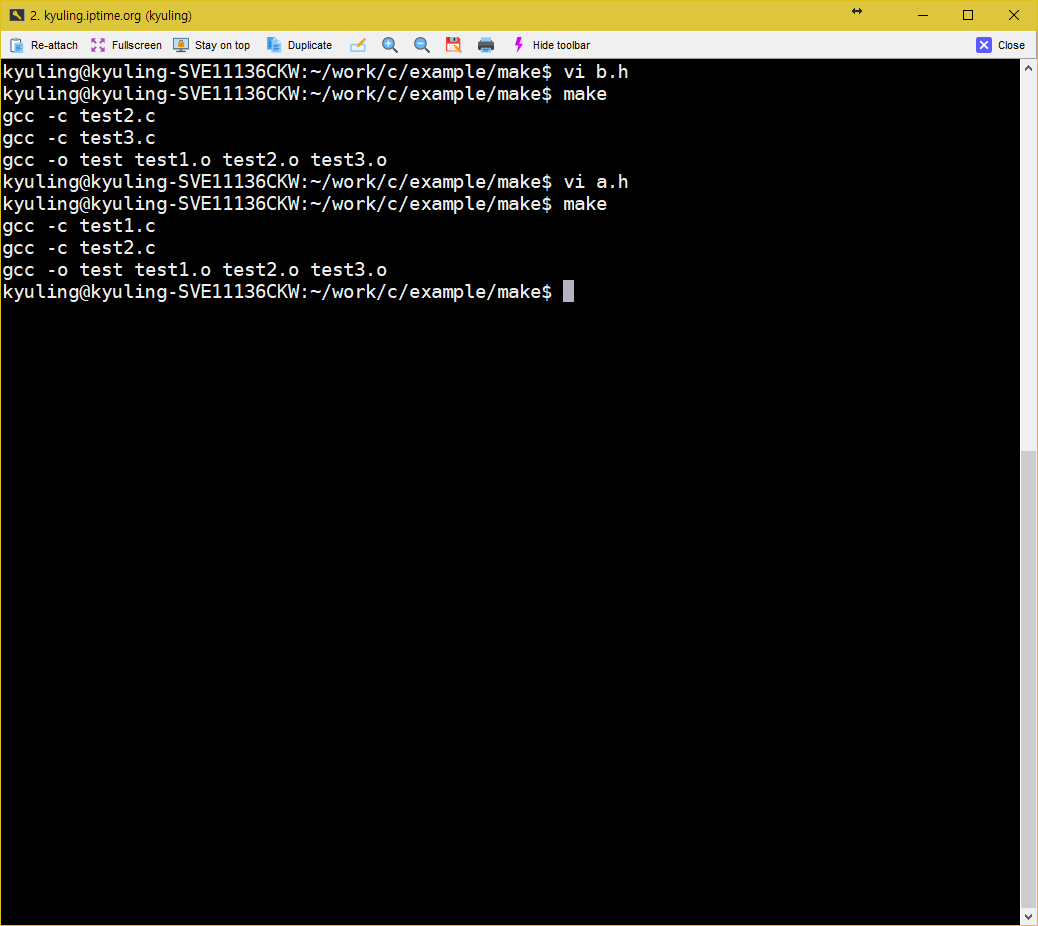
대상이 되는 test를 생성하기 위해 make는 의존하는 파일들을 살필 것이다. 그러나 대상이 의존하는 test1.o test2.o test3.o 이 세 파일이 존재하지 않기 때문에 make는 다시 저 파일들의 대상으로 있는 곳을 찾으려 한다. 이때, 찾지 못할 경우에는 오류를 내고 중단할 것 같지만, 실제로는 암시적 규칙에 따라 오브젝트 파일을 gcc가 생성할 수 있는 것을 알기 때문에, test1.o test2.o test3.o 파일을 생상하기 위해 의존하는 파일을 스스로 찾고 컴파일러 호출까지 알아서 수행한다. 이때, 실행 결과에 찍힌 규칙을 보면 알겠지만 gcc를 호출하는 것이 아니라 cc 컴파일러를 호출하였다.
이 과정을 보고 싶다면 make -p 라고 해서 -p 옵션을 통해서 볼 수 있다. 실행하면 아래와 같이 쭉 나온다. 아래 화면에 스크롤 바를 주목해라. 내용 장난 아니게 많다. 암시적 규칙으로 어떤 것들이 불러지는지 알고 싶다면 계속 스크롤을 내려서 살펴보는 것도 좋을 것이다. 근데 당장은 이해 못한다.
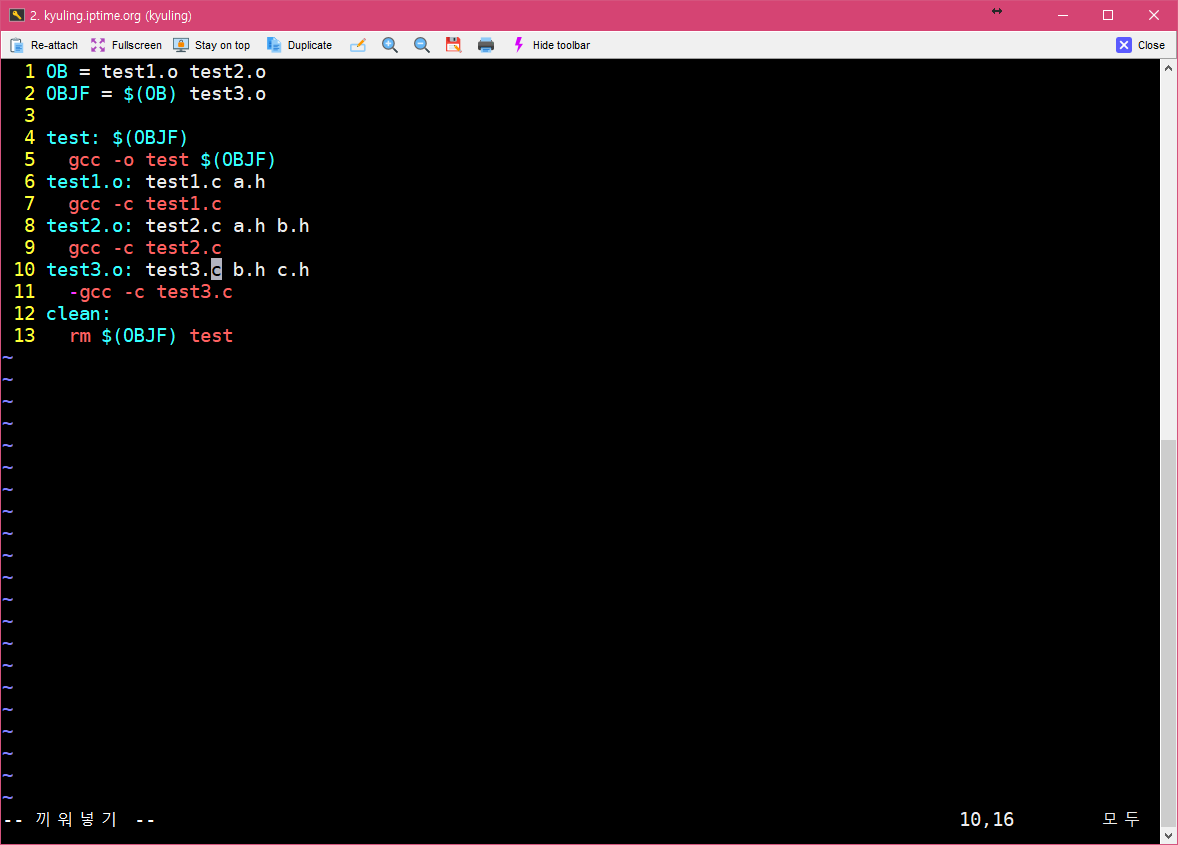
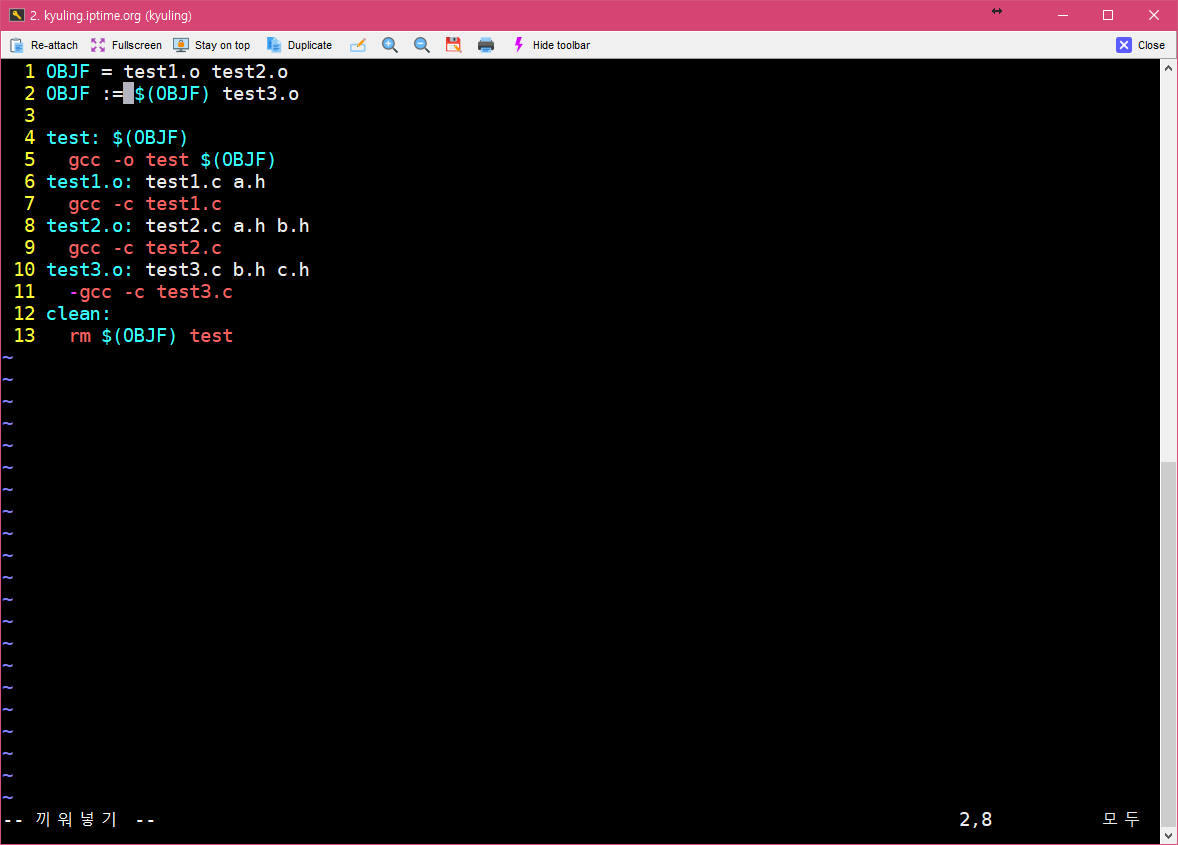
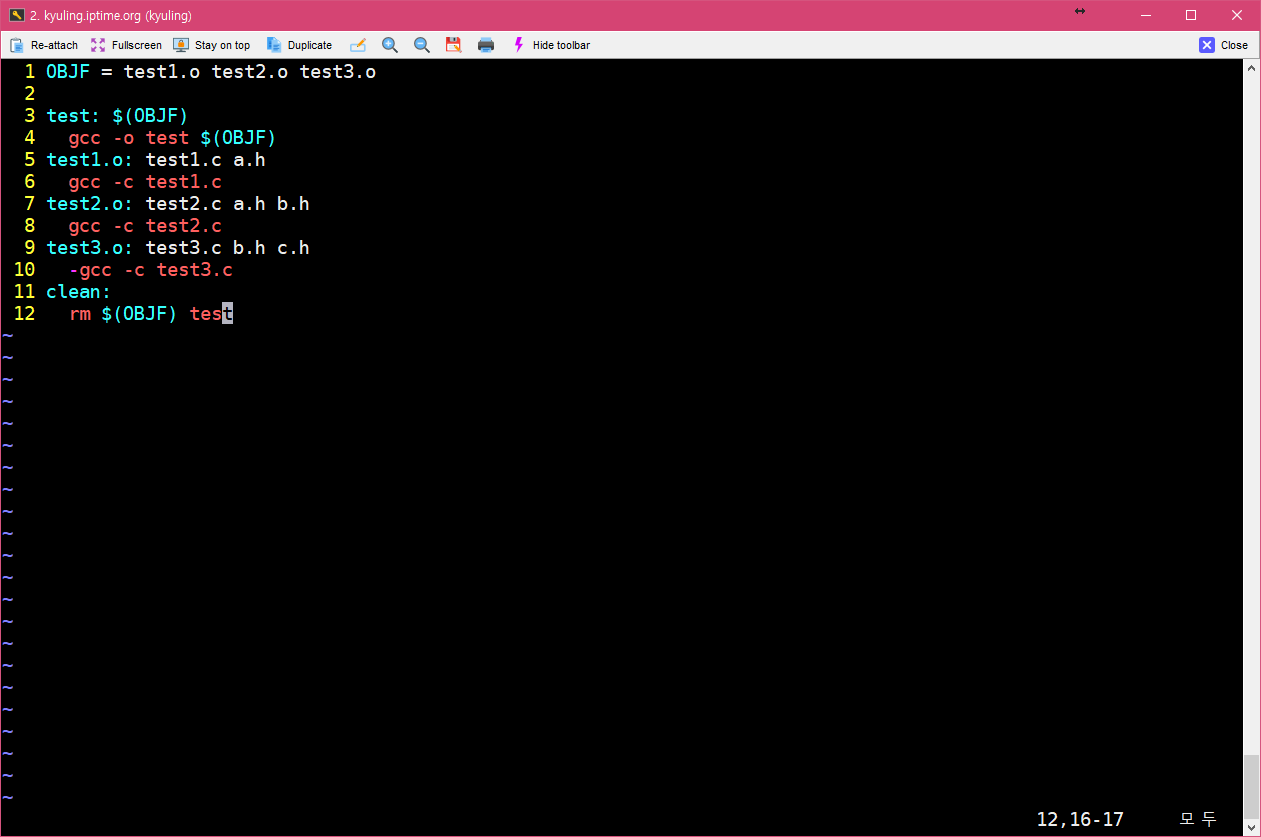
OB 매크로에 test3를 추가하는 형태로 OBJF를 바꾼 것이다. 그러면 일전에 모든 것을 다 선언했던 매크로와 동일한 효과가 있다.
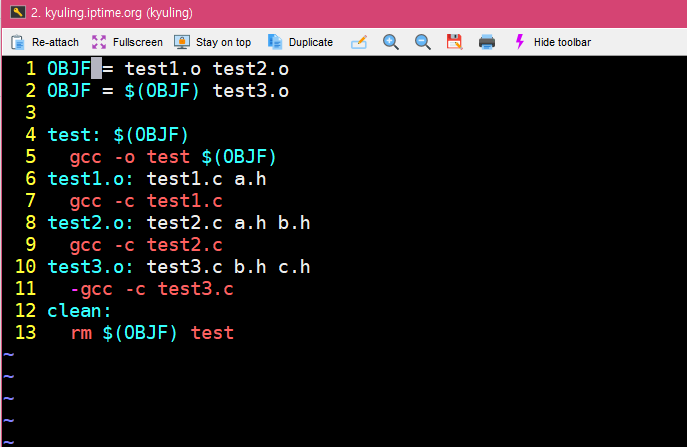
그렇다면 이제 프로그래밍 좀 해본 분들은 한 번 정도는 생각해 볼 만한 것이 바로 변수에 변수 뒤엎어 쓰듯이 매크로도 그런 식으로 쓸 수 있지 않을까 하는 생각을 할 것이다. 예를 들어 이렇게 말이다.
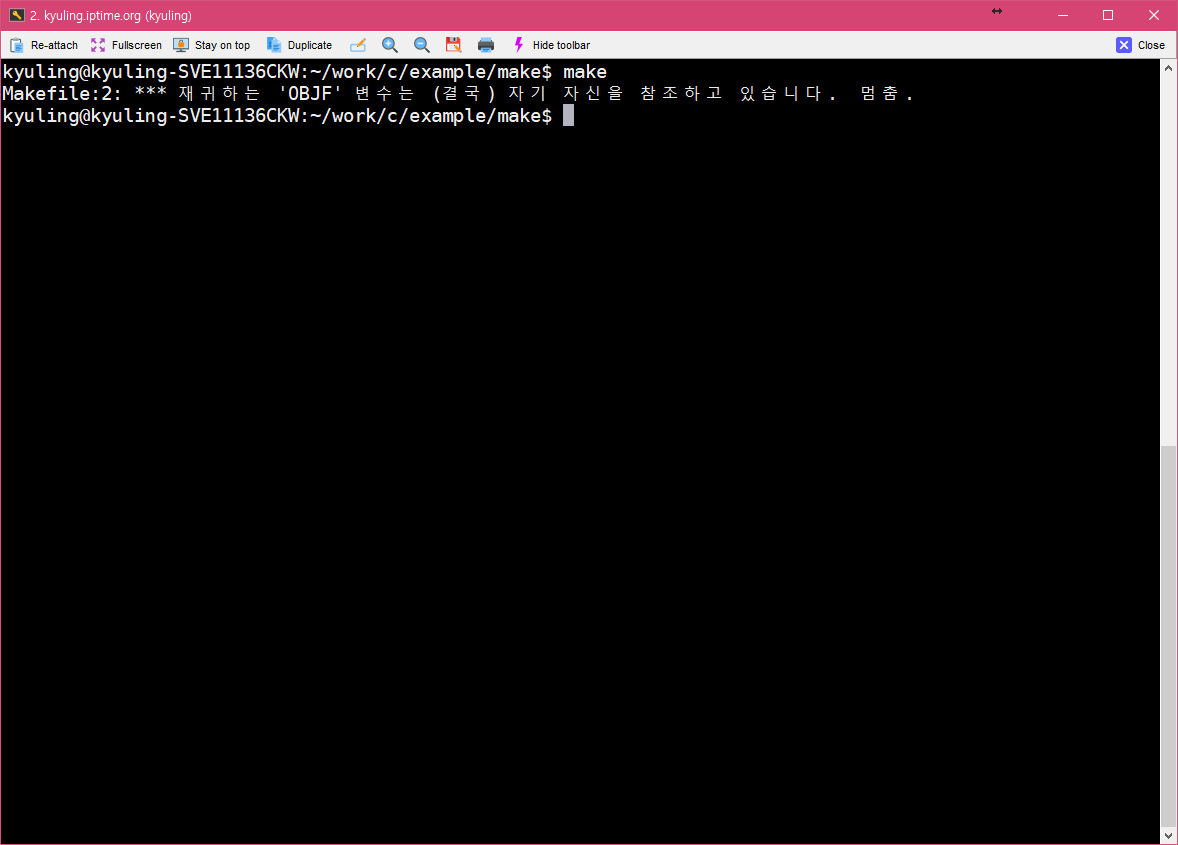
확대해서 보일 수 있도록 캡쳐를 하였다. 위의 화면과 같이 하면 되겠지? 라는 생각들 할 수도 있다. 결론부터 말하면 안된다. 아래처럼 된다.
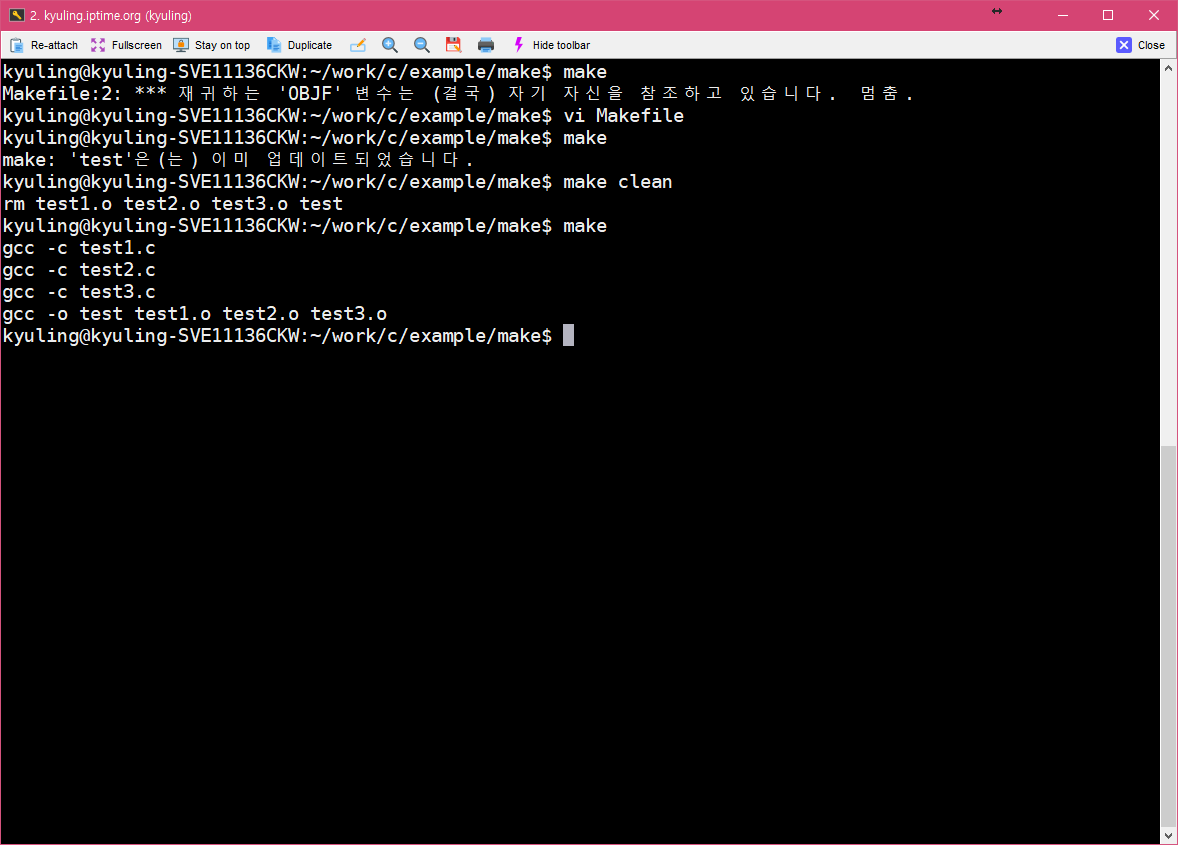
매크로가 정의되는 방식에는 두 가지 방식이 존재한다. 재귀 확장형 매크로와 단순 확장형 매크로가 존재하는데, 우리가 지금 이용하는 make의 경우에는 재귀 확장형 매크로이다. 따라서 이미 선언한 OBJF에 대해서 불러오는 부분에서 이용한 $(OBJF) 부분에서 재귀 콜이 불러져서 다시 참조하는 형태, 즉 다른 매크로를 포함하면 같이 확장을 하는 형태로 만들어졌기 때문에 오류를 낸 것이다. 똑똑한 매크로 실행기가 먼저 알아서 멈춰진 것이다.
그럼 이걸 단순 확장으로 만들 수 없는 걸까? 당연히 있다. 단순 확장 매크로는 말 그대로 단순히 확장만 되는 형태로 만들어지고, 매크로의 정의 차이에 따라서 이걸 판단하게 된다. 우선 단순확장에 대해서만 살펴보려고 하는데, 단순 확장의 경우에는 :=를 통해 확장하면 된다. 아래처럼 해주면 된다.
간단하다. 설명만 힘들 뿐이다. (ㅠㅠ) 이를 실행해보면 오류 없이 진행될 수 있는 것을 볼 수 있다.
그렇다면 기존에 있는 내용에 대해서 치환할 수 있는 매크로도 존재한다. 기본식이 다음과 같다.
$(M_NAME:old=new)
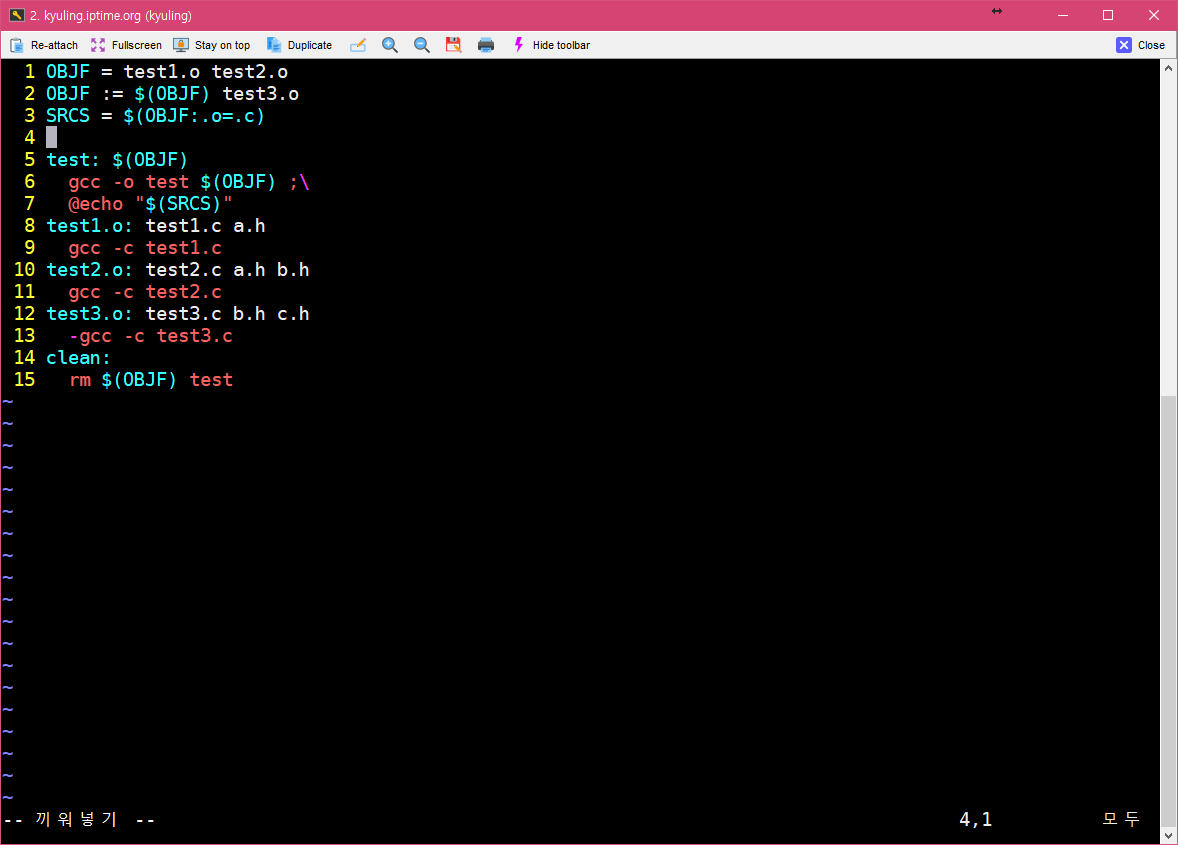
old가 기존에 있던 부분이고, new가 치환하려는 부분이다. 이건 예시 코드를 만들어서 보여주겠다. OBJF에 있는 .o 확장자를 .c 확장자로 변경해 보겠다.
위의 화면과 같이 SRCS라고 하는 소스코드 파일들을 매크로 선언으로 하였다. 그 다음에 이걸 확인하기 위해서 명령어를 하나 추가해서 보여주려고 한다. 아마 오류가 날 코드이다.
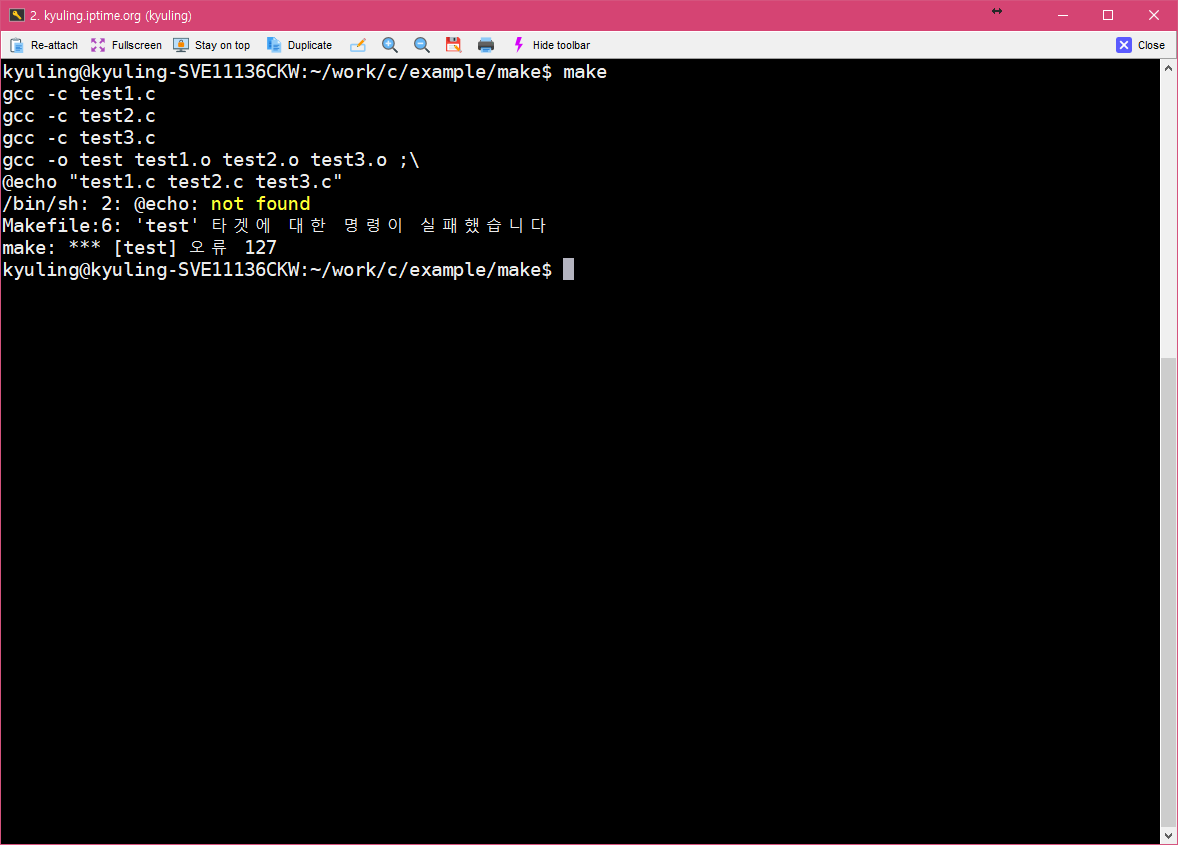
실제 실행한 화면이다. 예상대로 오류가 났다. (이거에 대해서는 나중에 글을 추가하겠다.) 그러나, 실행하려는 구문에 보면 뒤에 확장자가 .c로 바뀐 것을 볼 수 있다.
앞에서 살펴본 매크로의 경우에는 사용자가 원하는 대로 맞출 수 있는 매크로이기 때문에 사용자 정의 매크로라고 한다. (이 표현은 프로그래밍 언어 관련된 내용을 많이 보다보면 중복되게 나오는 표현이라 익숙할 것이다.) 그러나, make 파일을 만들 때 이용할 수 있도록 미리 정의된 매크로들이 존재하는데, 이를 내부 매크로라고 한다. 내부 매크로의 종류와 의미는 아래와 같다.
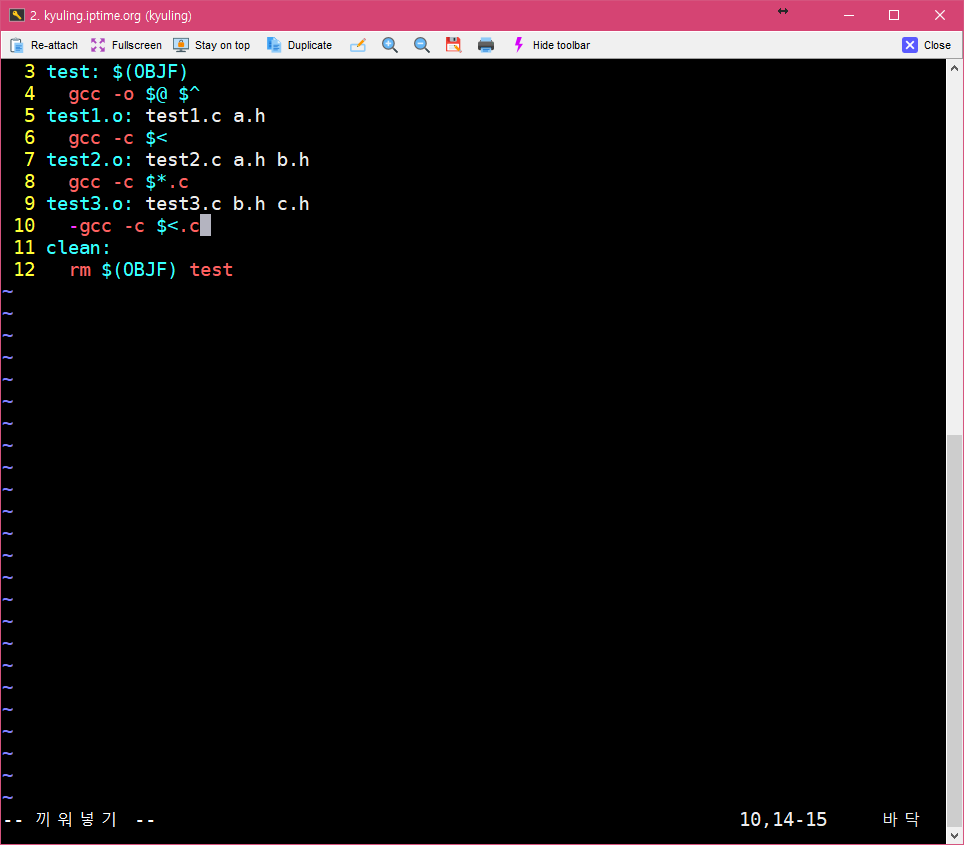
$@ |현재 목표 파일의 이름
$* | 확장자를 제외한 현재 목표 파일의 이름
$< | 현재 필수 조건 파일 중 첫 번째 파일 이름
$? | 현재 대상보다 최슨에 변경된 함수 조건 파일 이름
$^ | 현재 모든 필수 조건 파일들
이 내부 매크로를 이용하여 앞에서 살펴본 예제를 더 간단하게 만들어보자.
이 표현이 익숙하다면 상관 없겠는데 필자의 경우에는 은근 싫어하는 스타일이라서 사용하진 않는다.
make 파일을 작성하다 보면 같은 파일 이름을 여러 번 써야 하는 경우가 있다. 이를 매크로를 사용하면 편리하고 명령어를 단축시킬 수 있는다. 매크로는 다은과 같이 정의하면 된다.
M_NAME = value
사용자가 임의로 정해서 쓰는 매크로 이름인 M_NAME은 등호 오른쪽의 값으로 확정되면 다음과 같은 형태로 이용할 수 있다.
$ (M_NAME)
매크로를 이용하면 복잡한 구문을 간단한 단어로 표현할 수 있으므로, 짧은 make 파일을 만들 때보다는 더 복잡한 파일을 작성할 때 유용하다. 그리고 매크로 이름은 대소문자 모두 가능하지만 코딩 규칙 상 대문자만을 사용하는 것을 일반적이라고 한다. 그리고 make 파일의 상단에 미리 정의한 다음에 이용한다.
매크로를 이용하여 이전에 예시로 보여주기 위해 작성하였던 make 파일을 좀 더 단축시켜보았다. 그 결과가 아래의 화면이다.
앞에 장에서는 긴 내용이긴 하지만 make에 대한 기본적인 것들을 다뤘다. 이 내용에서는 앞의 장의 내용을 한번 실습해 본 상태에서 make에 대한 기타 내용을 추가하여 설명하려고 한다. 이 내용들은 make 파일을 만드는 데 있어서 부가적인 내용들이지만, 소스코드가 많아지고 makefile의 양이 많아지고 할 경우에는 유용하게 쓰이는 내용들이다. 또한 현재 C, C++ 프로젝트 중 규모가 거대한 프로젝트에서는 이 내용들이 많이 이용될 것이니 좀 내용이 길고 힘들더라도 이것까진 제대로 익혀두자.
가짜 대상
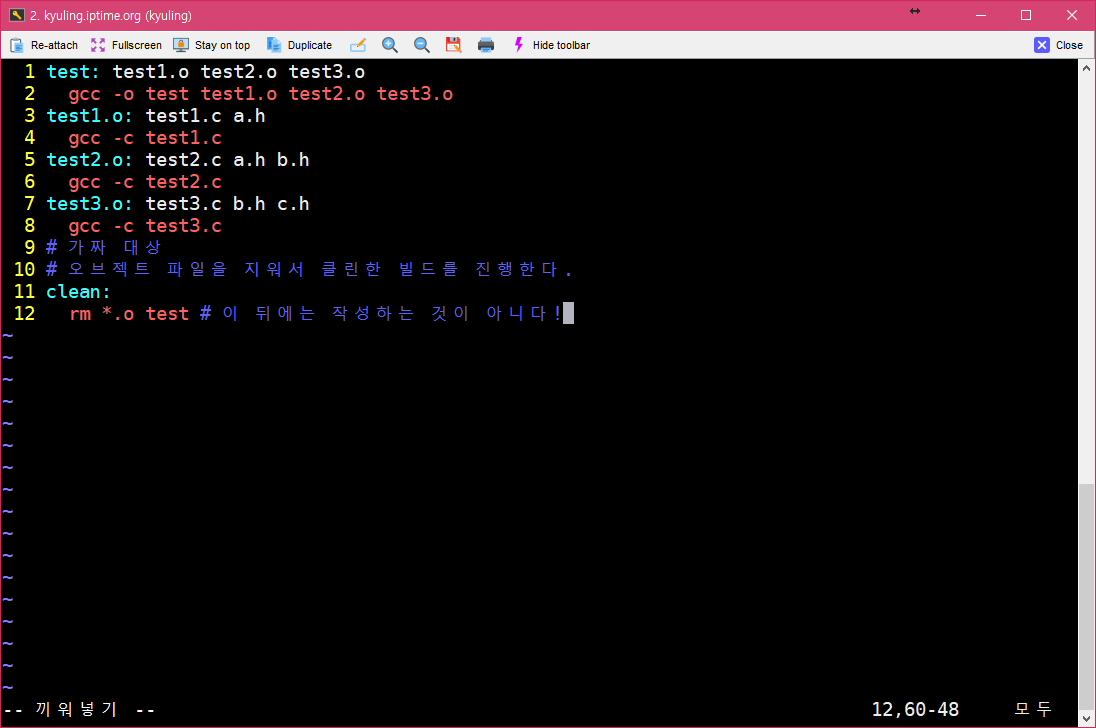
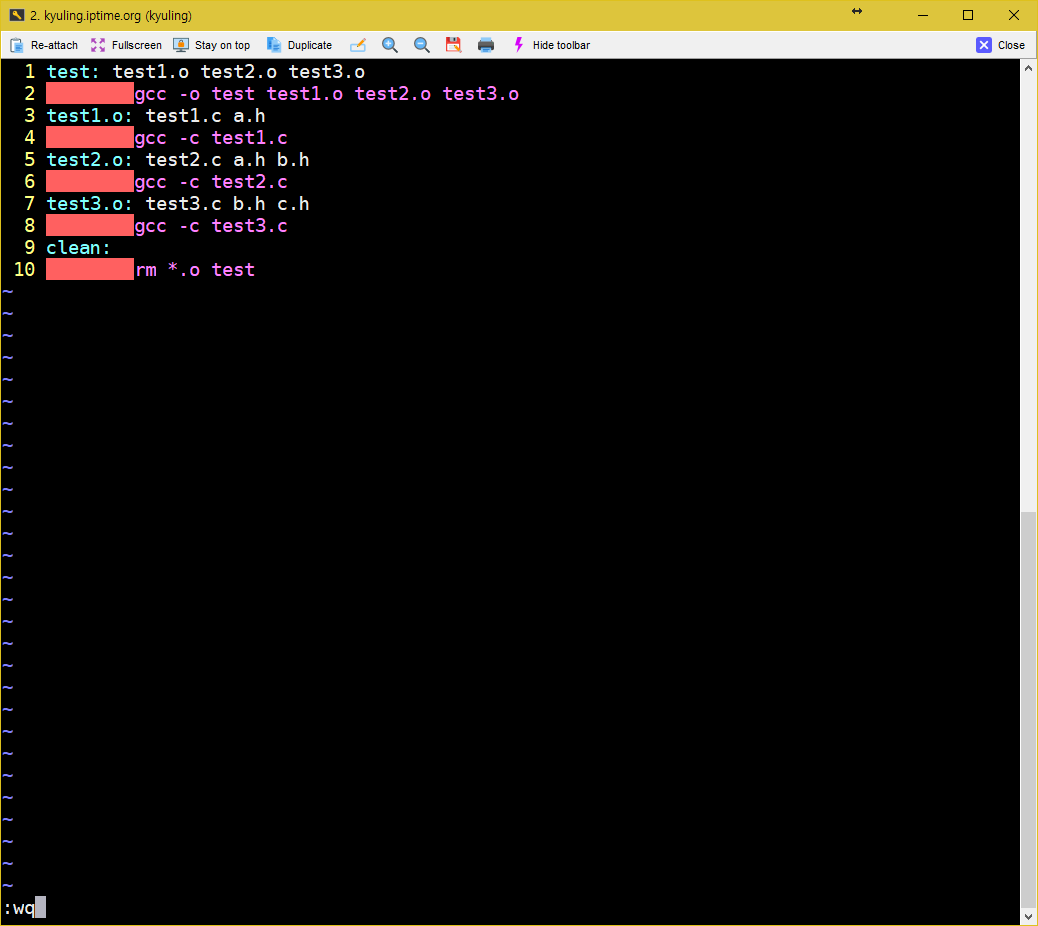
make 파일의 대상에는 실행 파일과 오브젝트 파일 뿐 아니라 사용자가 임의로 정한 레이블 이름이 올 수 있다고 하였다. 이를 구체적으로 살펴보기 위해서 아래와 같은 make 파일을 작성하였다.
중요한 것은 여기에 있는 바로 clean 레이블이다. clean이라는 대상은 실제 파일에 대응하지 않는 형태의 레이블이다. 이를 두고 가짜 대상이라고 하는데, 이런 가짜 대상은 사용자가 원할 때 make가 특정 명령을 실행하도록 하기 위해 만들어 사용한다.
그리고 clean은 의존성을 갖지 않기 때문에 make는 clean 대상을 만날 때마다 대상이 항상 최신으로 업데이트 된 상태로 간주한다. 이 대상을 구성하려면 다음과 같이 실행해야 하는데, 다음 결과를 보면 알 수 있듯 clean을 대상으로 삼는 명령이 실행된다.
주석
주석은 개발자와 다른 사람이 코드를 이해하는 데 도움이 많이 된다. 필자의 경우에는 주석을 엄청나게 이용하는 편이다. 주석문을 삽입하면 추후에 자신이 작성한 코드를 수정하고자 할 때 훨씬 쉽게 수정할 수도 있고, 다른 사람들이 작성한 코드도 주석문의 내용을 통해 쉽게 이해할 수 있기 때문이다. 그래서 make 파일에도 주석을 이용하여 작성할 수 있는데, #이 앞에 있으면 그 뒤의 문장은 주석이 된다. 단, 프로그램 코드의 주석과 달리 명령 라인 뒤에 주석을 붙이지는 않는다. 셸이 #에 대해서 메타 문자 형태로 인식하여 이것을 변환하려고 시도할 수 있기 때문이다. 리눅스를 쓰는 친구들은 configure 파일에도 보면 주석을 작성하는 데 옵션 뒤에 주석을 쓰는 것을 보지 못했을 것이다. 이와 같은 원리로, 따라서 주석은 코드와 전혀 관계 없는 곳에 작성한다.
자동 의존 관계 생성
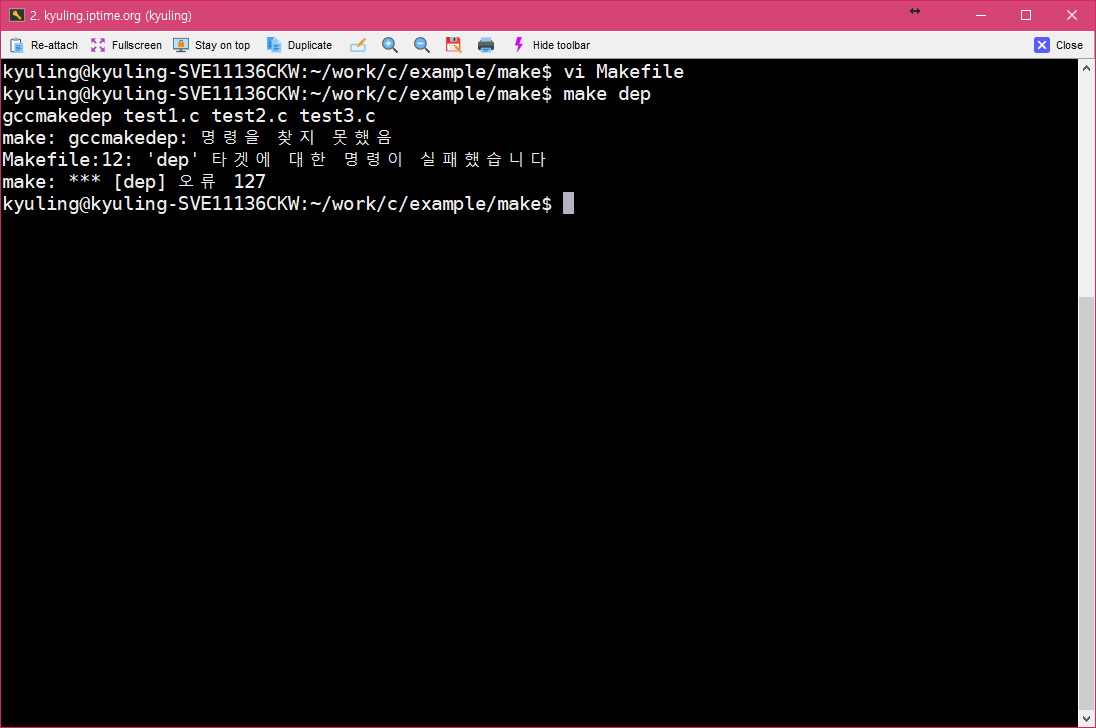
의존 관계의 경우, gcc에서 자동으로 생성할 수 있는 방법이 있다. gccmakedep 명령어를 이용하면 의존 관계를 자동적으로 생성할 수 있다. 그런데, 이 작업을 거치기 전에, 우분투 사용자들은 다음과 같은 명령어로 패키지를 하나 설치해야 한다.
sudo apt-get install xutils-dev
이 작업은 gcc의 기본 환경인 make에 있는 것이 아니라 imake라고 별도의 패키지에 있는데, 이걸 포함하고 잇는 것이 바로 저것이다. (페도라 계열을 그냥 바로 gccmakedep을 설치하면 알아서 저걸 깔아준다.) 그러지 않으면 오류가 난다.
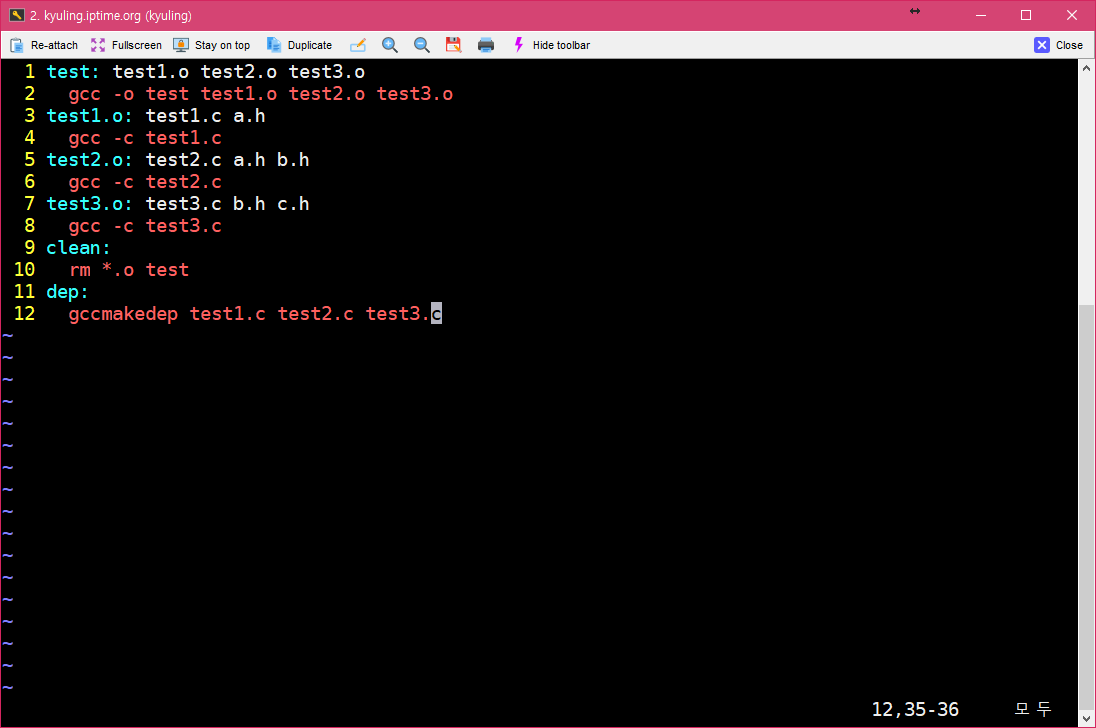
그럼 의존성은 어떻게 자동으로 만들 수 있는지 확인해 보겠다. 우선 전에 이용하던 make 파일을 수정한다.
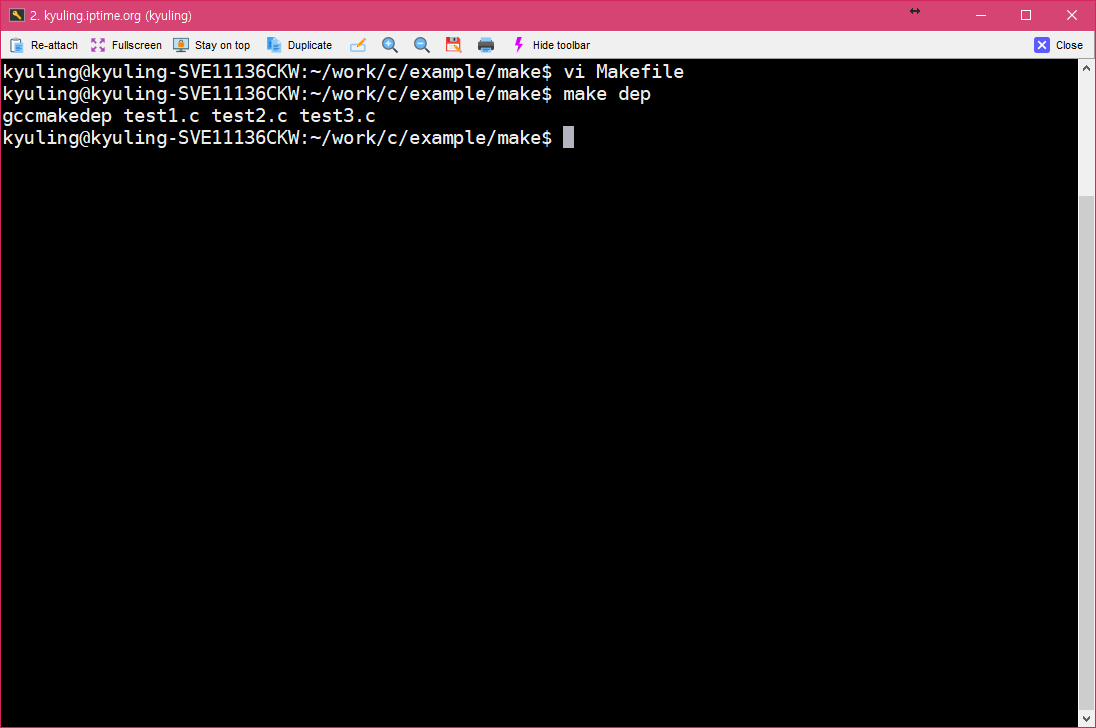
dep이라는 가짜 대상을 만들고, gccmakedep 명령으로 세 코드의 의존성을 생성하도록 하였다. 그리고 저장 후 빌드를 할때, 아래와 같이 나오면 위의 패키지가 설치되어 있지 않은 것이다.
아래와 같이 나와야 정상적으로 끝난 것이다.
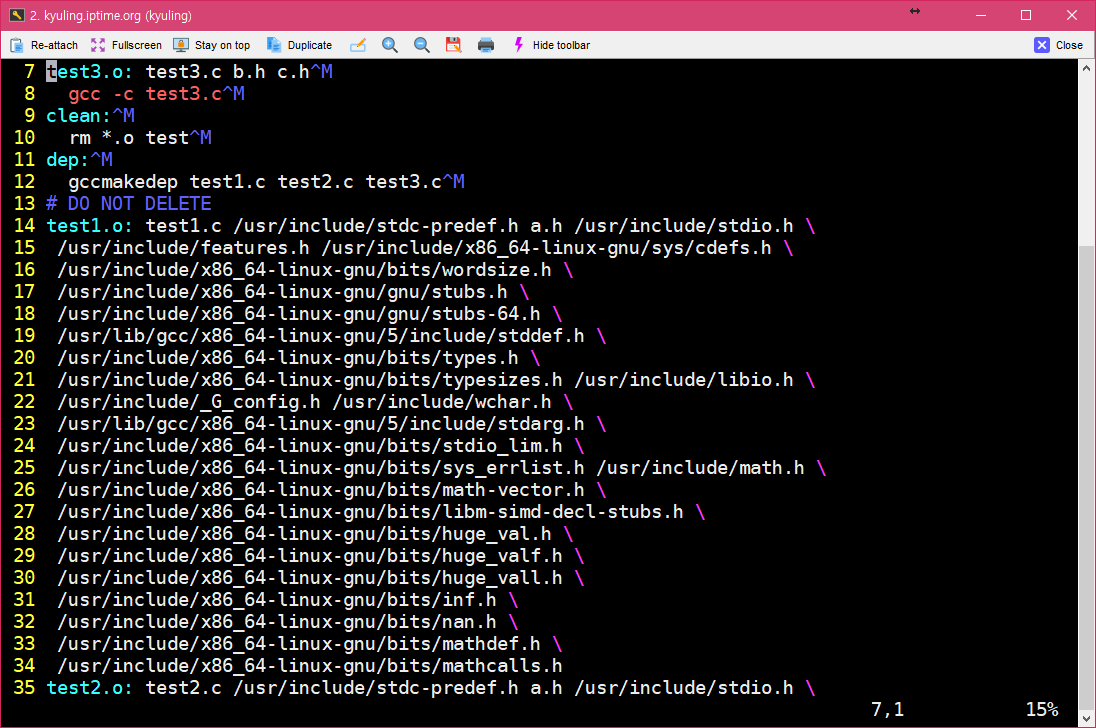
그리고 나서 Makefile을 열어 보면 아래와 같이 작성되어 있는 것을 알 수 있다.
주석으로 DO NOT DELETE라고 적힌 곳부터가 자동으로 생성된 코드이다. 각각 사용자가 작성한 헤더인 a.h 말고도 다른 것들이 더 있는데, 저것들이 a.h 안에 삽입되어 있는 stdio.h와 연관된 의존 헤더들이다. 현재 시스템이 어떤 컴파일러, 어떤 라이브러리가 설치되어 있느냐에 따라서 의존된 결과가 다를 수 있다.
긴 명령어 쓰기
바로 위에 그림에 자동으로 생성된 의존 관계를 보면, \로 끝이 끝나는 걸 볼 수 있다. 이것이 바로 명령어가 옆으로 길어져서 다음 라인으로 옮겨 쓰기 위해 이용하는 것이다. \의 뒤에는 아무것도 작성하지 않고 바로 다음 문장으로 넘어간다. 여러 문장으로 하고 싶을 경우에는 끊어야 할 부분에 \를 입력하여 다시 길게 작성한다.
여러 개의 셸 명령 사용
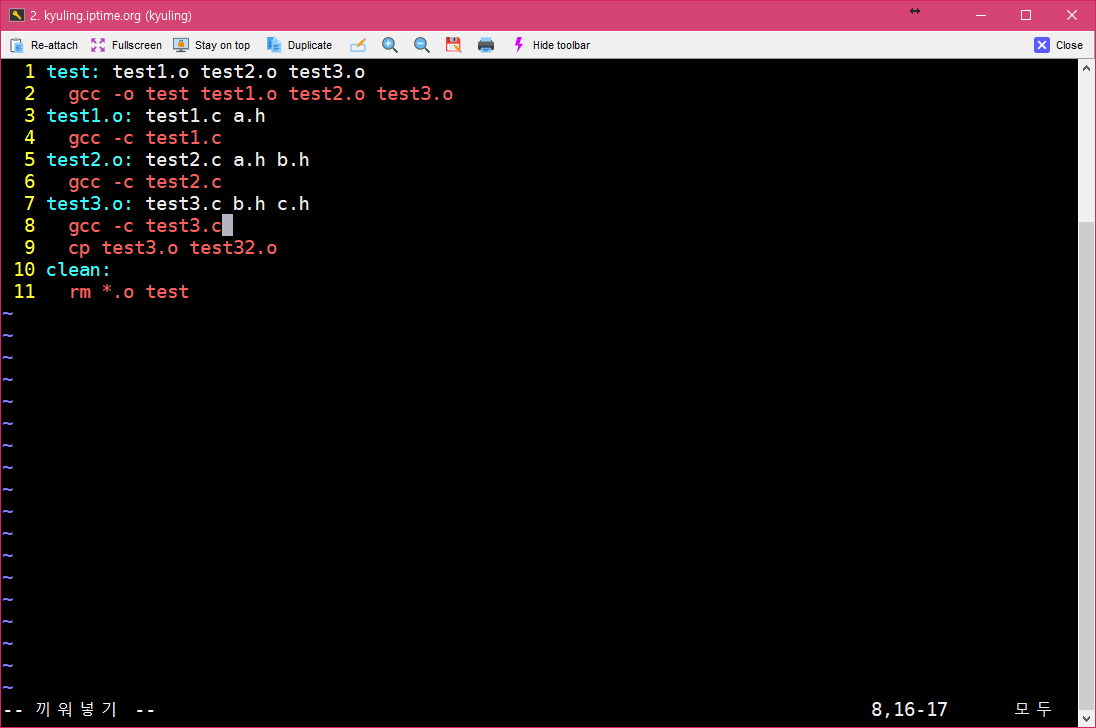
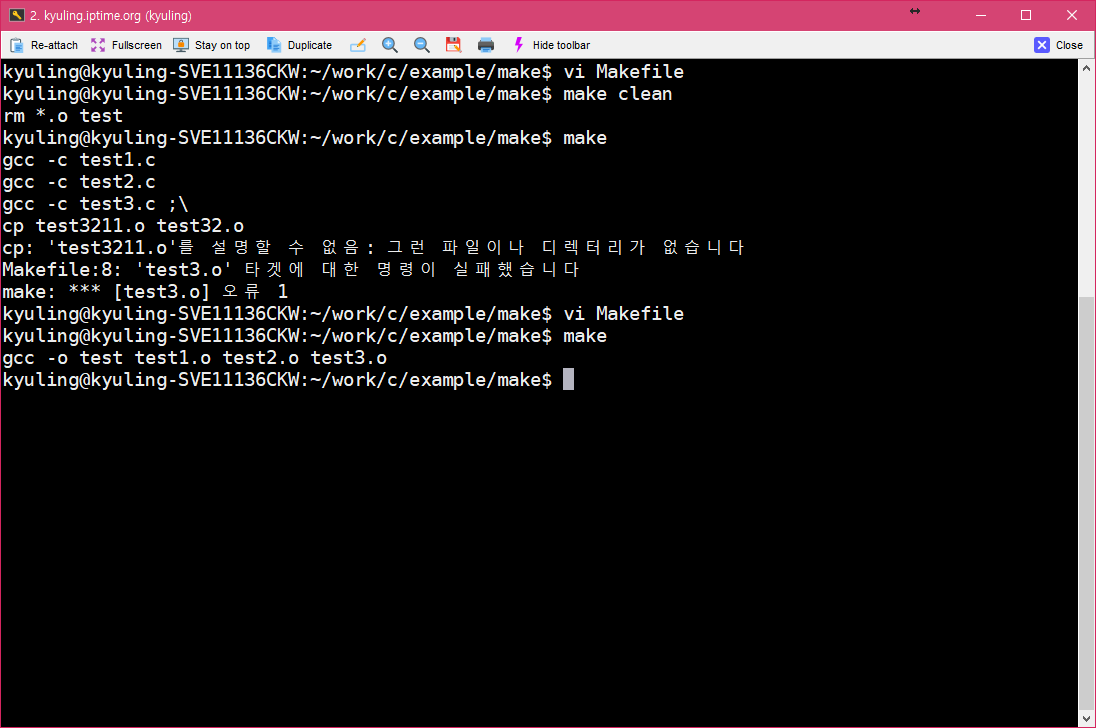
make 파일 내에서는 모든 셸 명령을 사용할 수 있다. 그러나 모든 명령이 다른 셸 안에서 실행되기 때문에 하나 이상의 명령을 사용할 때 문제가 생길 수 있는데, 이를 해결하기 위해서 세미콜론(;)을 이용하여 작성을 한다. 아래와 같이 적으면 오류가 나는 상황인데,
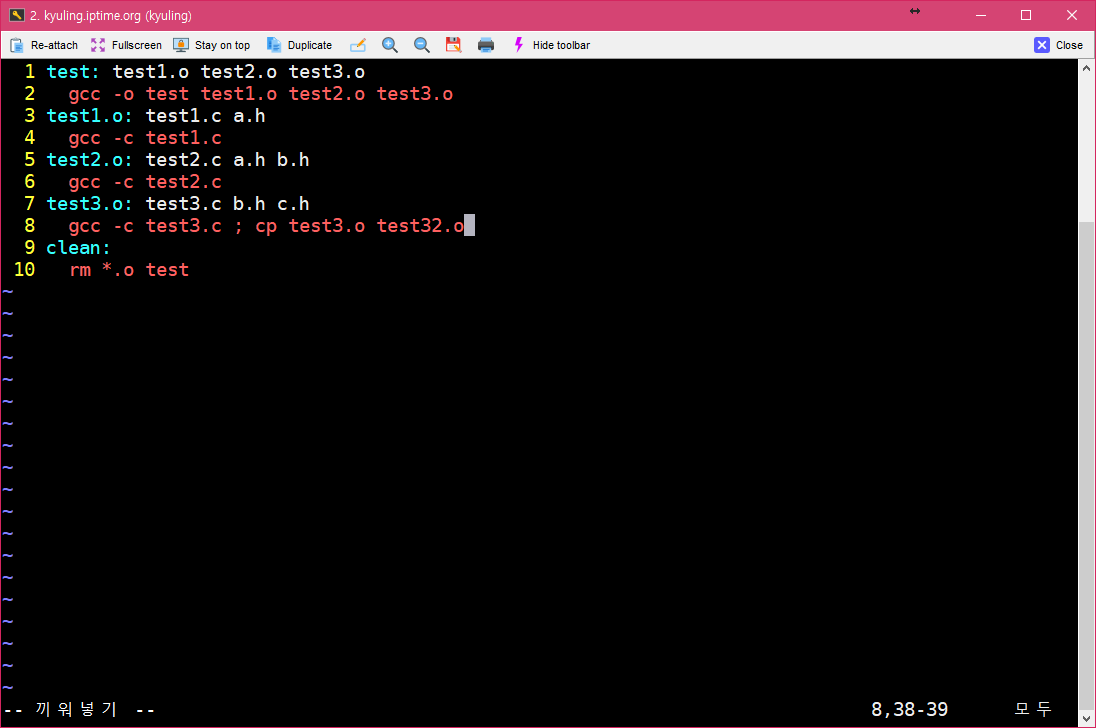
세미콜론을 넣고 한 문장으로 작성하면 된다.
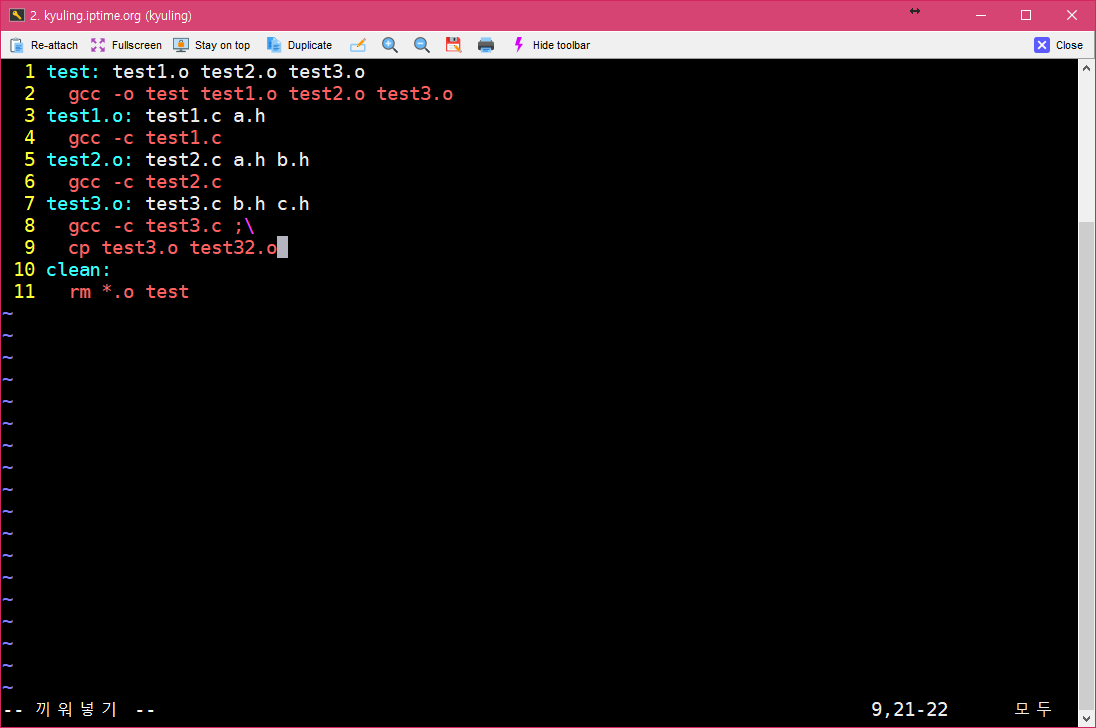
물론, 다음 문장으로 넘겨서 쓰는 것도 가능하다.
이것을 실행해 보면 확실히 test3.o 레이블을 실행할 때, 명령이 두 라인 실행되어서 복사본이 만들어지는 걸 볼 수 있다.
명령 실패 무시
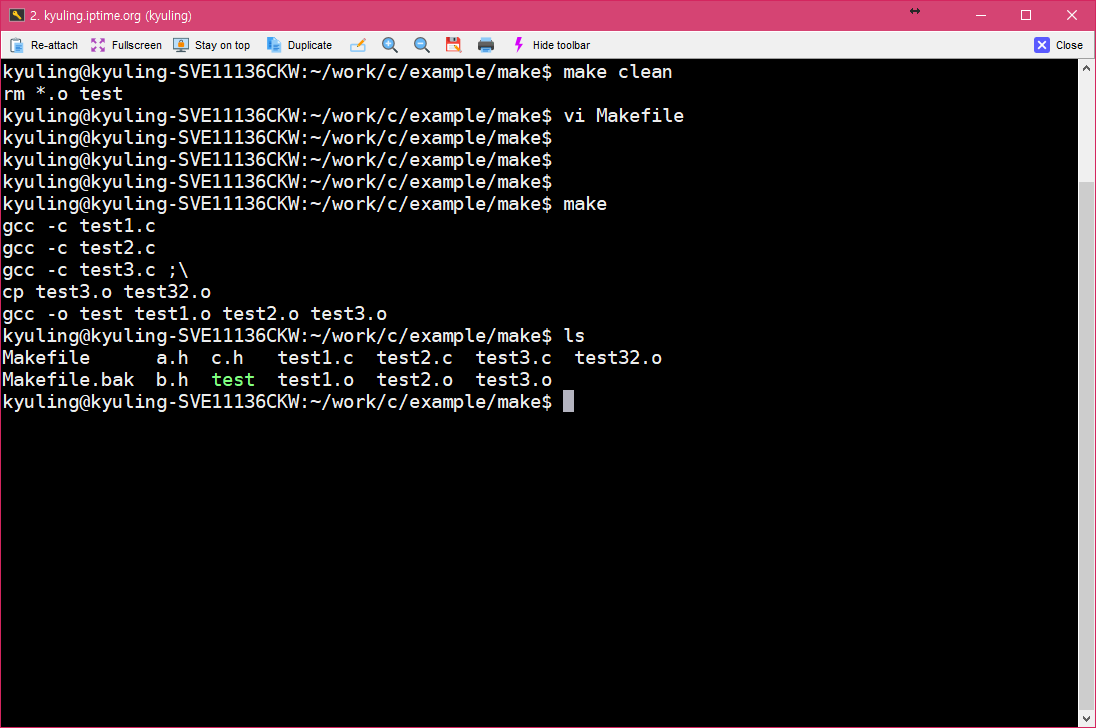
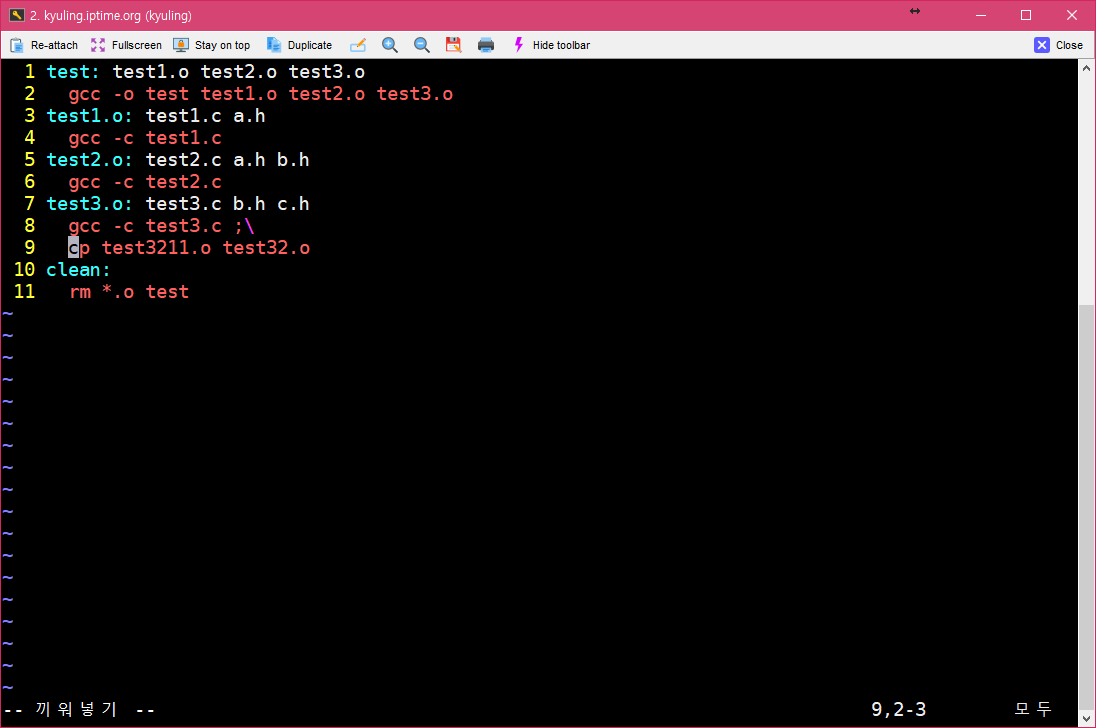
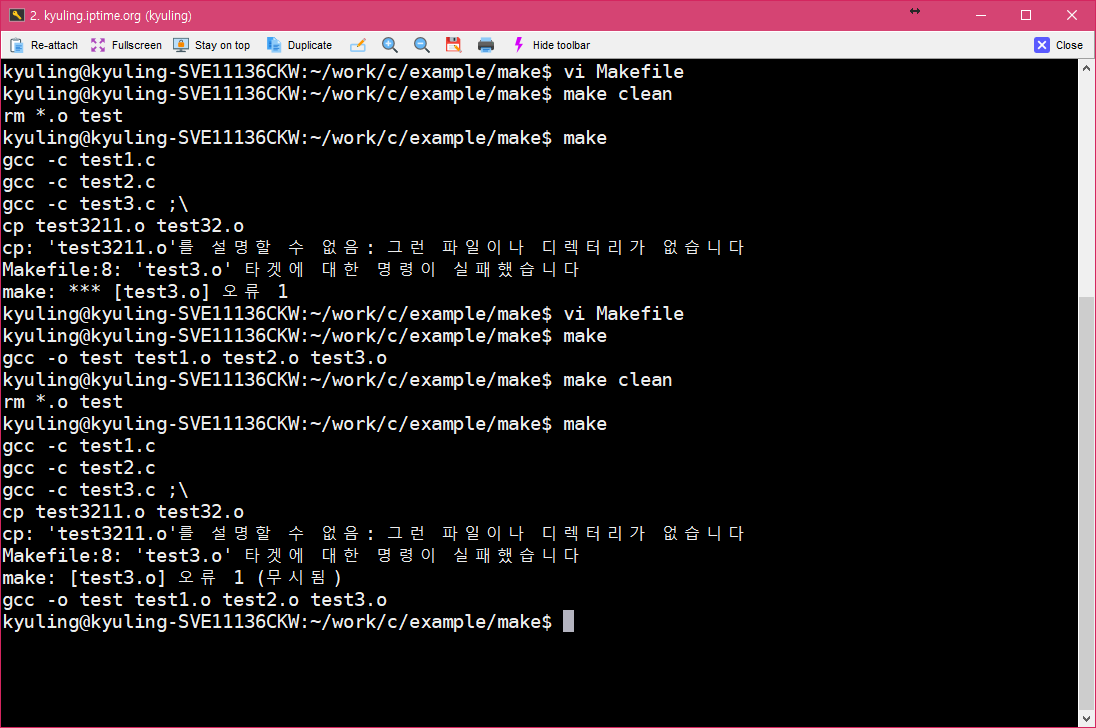
make를 실행하다 보면 make는 대상이 있는지, 대상이 의존하는 파일이 수정되었는지의 여부에 따라 필요한 명령을 실행한다. 하지만, 중간 명령의 실행에 실패하면 오류 메시지를 출력하면서 바로 동작을 멈춘다. 이럴 때, 명령이 실패해도 작업을 계속 진행하고 싶을 경우에는 이 과정을 무시할 수 있어야 하는데, make 파일 내 명령어 앞에 하이픈(-)을 삽입하여 주면 된다. 이것도 예시를 확인하자.
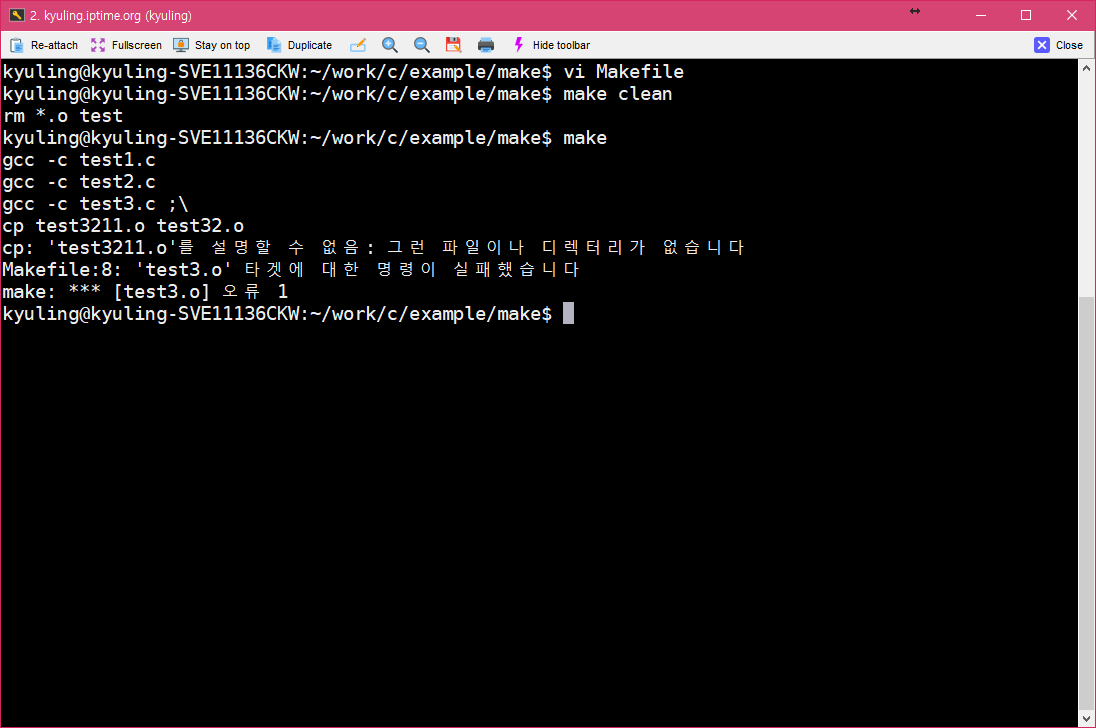
확실하게 없는 파일을 복사하려 하고 있다. 이 경우에 실제로 make를 하게 되면 오류가 난다.
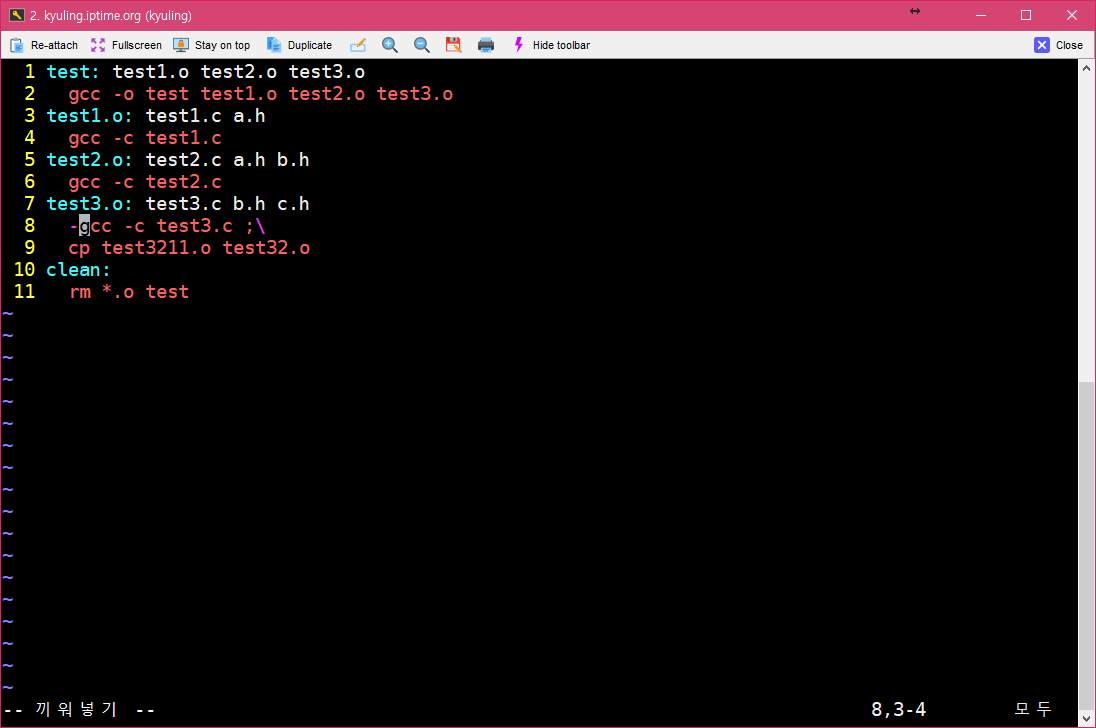
이제, 오류가 나는 줄을 처리하는 곳에 하이픈을 붙여서 실행하면 오류가 나지 않고 마저 실행되지 않았던 명령이 실행될 것이다.
이 결과를 다시 보기 위해서 clean으로 다 지운 후, 다시 컴파일을 시도해 보았다. 그러면 아래와 같이 오류 명령과 함께 무시됨이라고 해서 해당 처리가 무시되었다는 것을 볼 수 있다.
이로써 Makefile을 만드는 데 있어서 가장 기본이 되는 내용들을 전부 살펴보았다. 이 외에도 매크로라던가 사용 규칙, 옵션 들을 좀 더 살펴봐야 하지만, 여기까지만 알아도 공부하는 수준에서의 make 파일의 관리는 될 수 있다. 셸 스크립트 배우는 거 같으면서도 코드 컴파일 및 클리어 기능을 통해서 어느 정도 관리를 할 수 있는 구조가 이런 것이구나를 확인할 수 있는 것은 중요한 요소라고 본다.
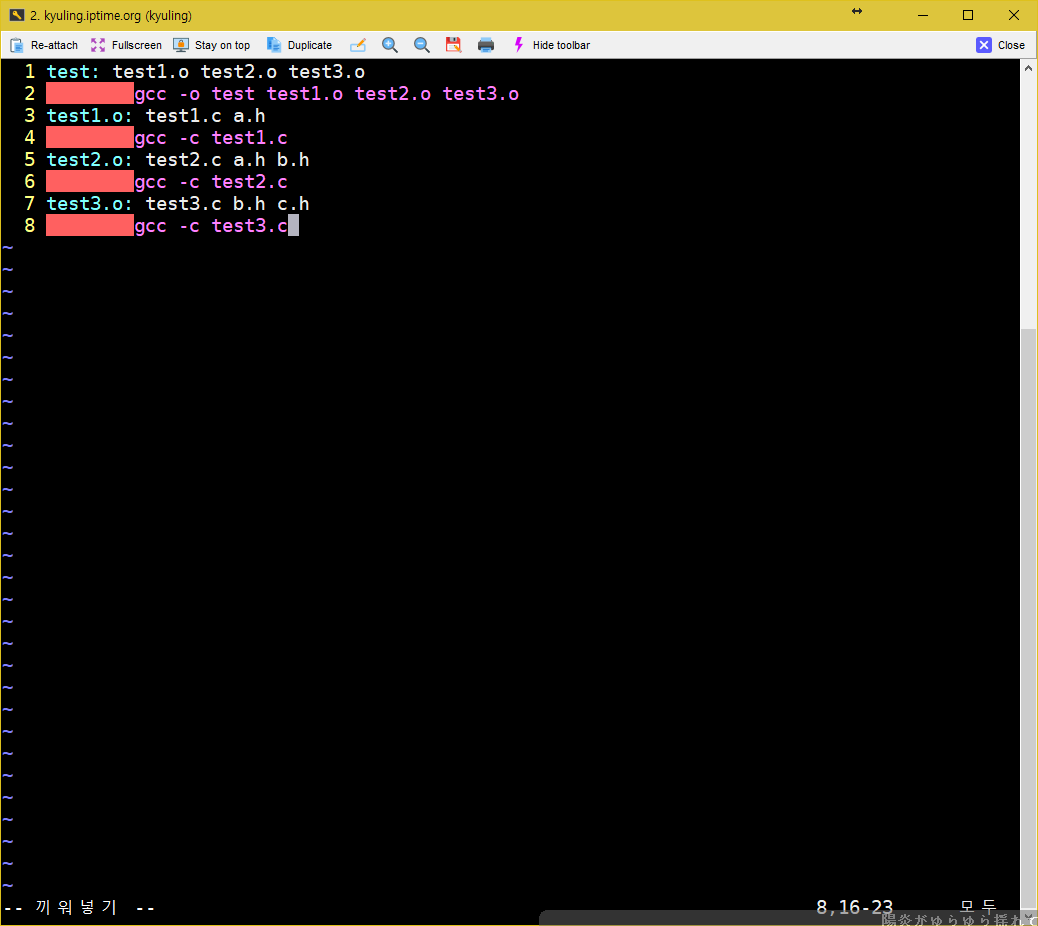
첫 줄에는 test라는 대상을 생성하는 데 test1.o, test2.o, test3.o 세 파일이 필요한 것을 알 수 있다. 그리고 두번째 줄에서 test1.o를 생성하는데 test1.c, a.h가 필요하고, 세번째 줄에서 test2.o를 생성하는 데 test2.c a.h b.h가, test3.o를 생성하는 데 test3.c b.h c.h가 필요하다는 것도 알 수 있다. 그리고 이 4줄의 코드가 전부 의존되는 파일들이 이어져 있다는 것을 알 수 있다. 이게 바로 의존성이다. 한 개 이상의 파일들이 서로를 필요로 하고, 그에 맞게 연결되어 있는 것이다. 이 경우에는 의존 관계 트리 형태로 최종 test를 만드는 데 필요한 헤더와 소스코드 파일이 트리 구조로 이어져있을 수 있다.
명령
명령(command)에 정의된 명령은 대부분 컴파일러 호출이고, 대상이 의존하는 파일 중 변경된 파일이 있거나 대상이 존재하지 않을 때 실행된다. 명령에는 일반적으로 쉘에서 쓸 수 있는 모든 명령어를 사용할 수 있으며, bash의 기반이 되는 bash 쉘 스크립트도 지원한다. (이거 땜에 솔직히 쉘 프로그래밍을 공부하는 거라고 보면 된다.)
그리고 명령을 사용할 때는 다음과 같이 반드시 탭 문자로 시작해야 한다. make가 명령어인지 아닌지를 구분하는 것이 바로 탭 문자이기 때문이다. 또한 탭 문자 크기만큼 스페이스바로 미는 사람들(특히 초심자들)이 있는데, 그렇게 하면 안된다. 필자는 블로그 글을 쓰기 편하게 하려고 탭 대신에 스페이스로 밀어서 글을 작성하였다. 그러나 실제로는 그렇게 안짠다.
이제 이걸 간단한 예시로 알아보려고 한다. 예시에 작성한 내용이 좀 많아서 그렇지 앞에서 설명한 내용대로 움직이는 지 확인하는 예시이다.
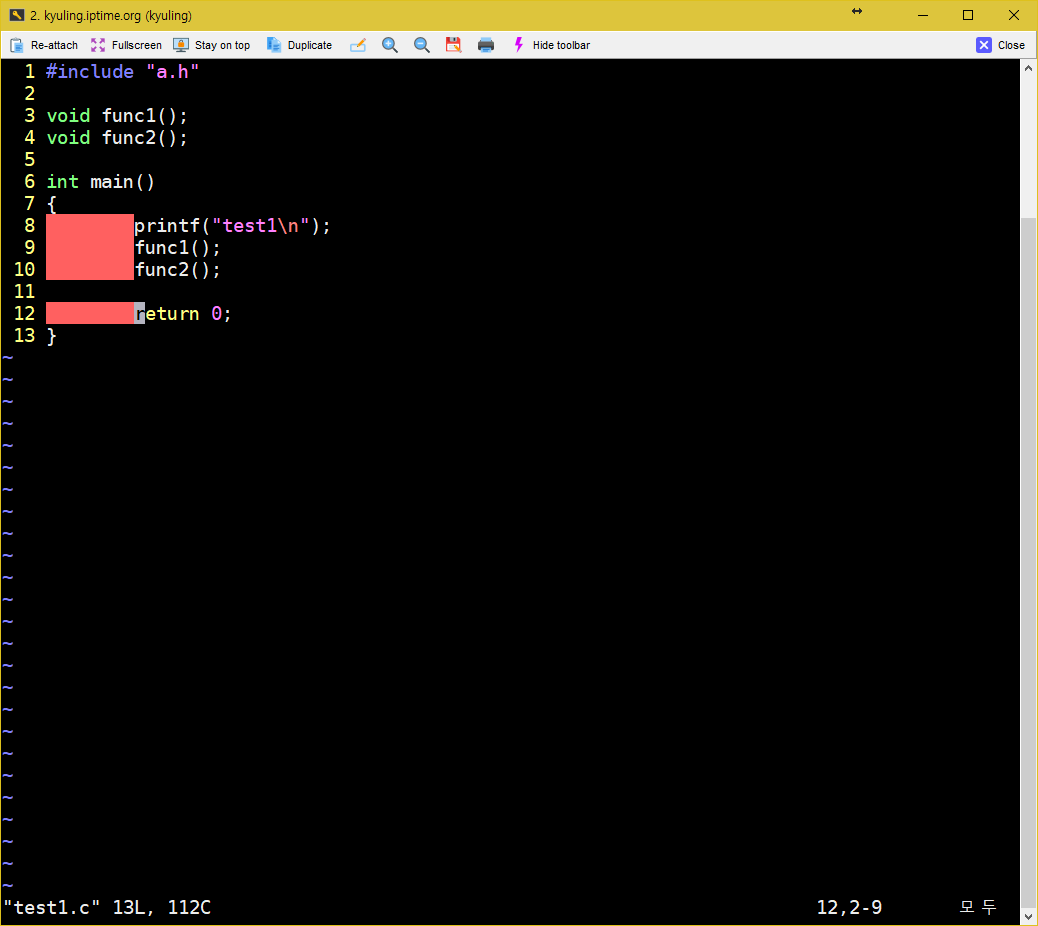
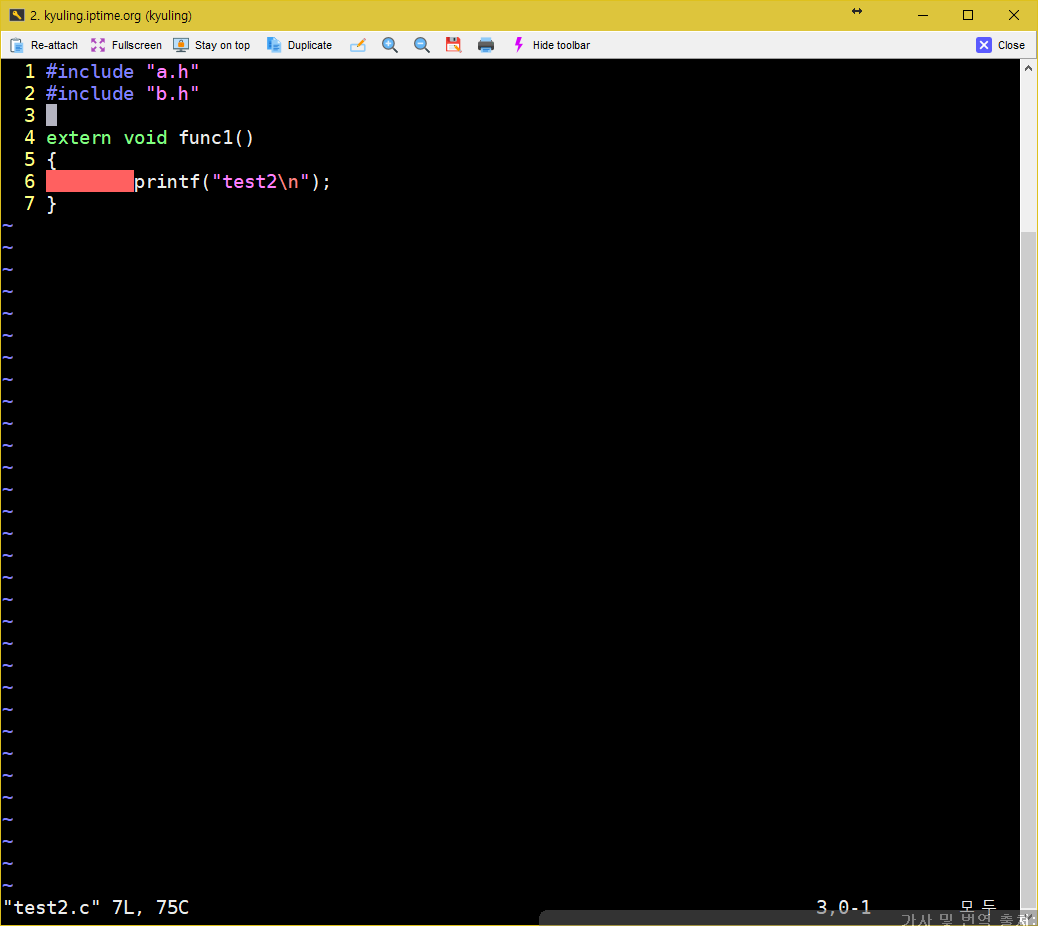
우선 test1.c test2.c test3.c 파일을 각각 만들어준다.
위와 같이 소스코드를 작성한 후, 참조하는 헤더를 touch로 만들어준다. 참고로 stdio.h 헤더 일부러 include 안했다. 나중에 보자. 그리고 터치로 파일 만들어서 내용이 비어 있어도 컴파일 하는 데 있어서 상관은 없다. 파일이 없으면 파일 없는 에러를 내지만, 사용자 헤더 내용이 없는 건 오류가 되지 않는다.
이제 Makefile을 작성한다. vi Makefile 이라고 해서 아래와 같이 작성을 한다. 참고로 짝수줄 앞에 빨간 영역이 바로 탭 영역으로 구분을 한 곳이다.
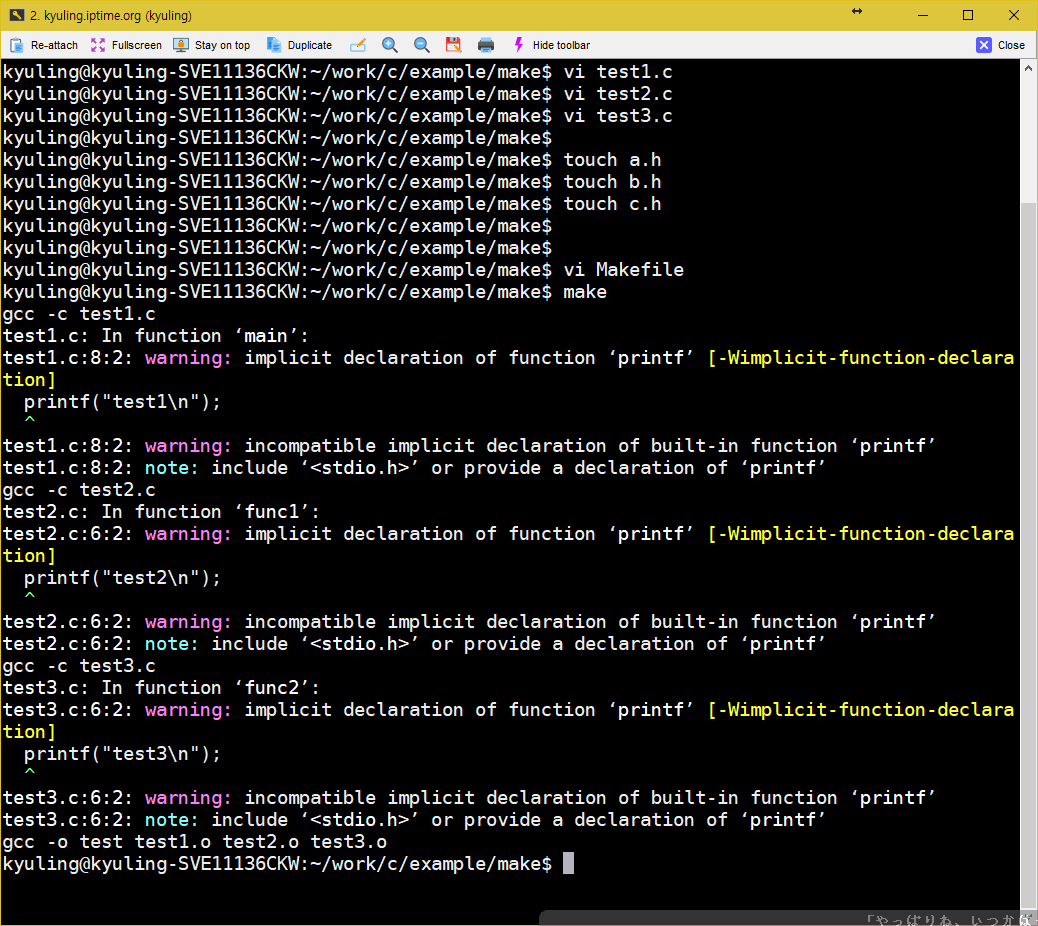
작성 후, make를 입력하면 명령들이 실행되는 것을 볼 수 있다. 아래와 같이 나오면 정상이다. stdio.h 헤더가 없어서 경고를 출력한 것이다. 파일 자체는 두번째 화면과 같이 다 만들어졌다.
여기서 중요한 것이 있다. 바로 Makefile의 실행 순서이다. 분명히 작성할 때에는 test를 맨 먼저 적었을 텐데, 정작 실행은 test1.o, test2.o test3.o 순서로 실행이 진행되었다.
즉, make가 Makefile에서 설정된 순서대로 실행이 되는 것이 아니라는 것이다. 바로 의존되는 관계 트리에서 가장 아래에 있는 의존성을 먼저 실행하게 된다. 가장 하위 대상에 속한 명령이 실행되고, 그 다음으로 해서 탐색 루트르 따라 올라가서 마지막에 제일 높은 의존을 가진 test가 실행된 것이다.
아까도 이야기를 잠깐 적었지만, 파일이 없는 것은 중요한 오류다. 그렇기 때문에 의존성이 있는 파일의 경우에는 의존성을 체크하여 의존 파일이 만들어져 있는지, 새로 만들어야 하는지를 탐색하면서 순서를 정리하여 빌드해 주는 것이다. 상당히 중요한 내용이고 Makefile이 엄청 커지게 되면 이게 제대로 구분이 가지 않는 경우도 많이 생긴다. 따라서 의존도 체크하는 것은 상당히 중요한 일이다.
또한 make 명령의 경우에는 각각의 타겟을 단독으로 실행할 수 있다. 우선 아래처럼 최종 완성본인 test를 지워보고 나서 make test를 통해 test만 실행해 보았다. 그러면 test는 오브젝트 파일 셋이 그냥 그대로 있으니 바로 컴파일해서 파일을 만들어내면 되는 것이다.
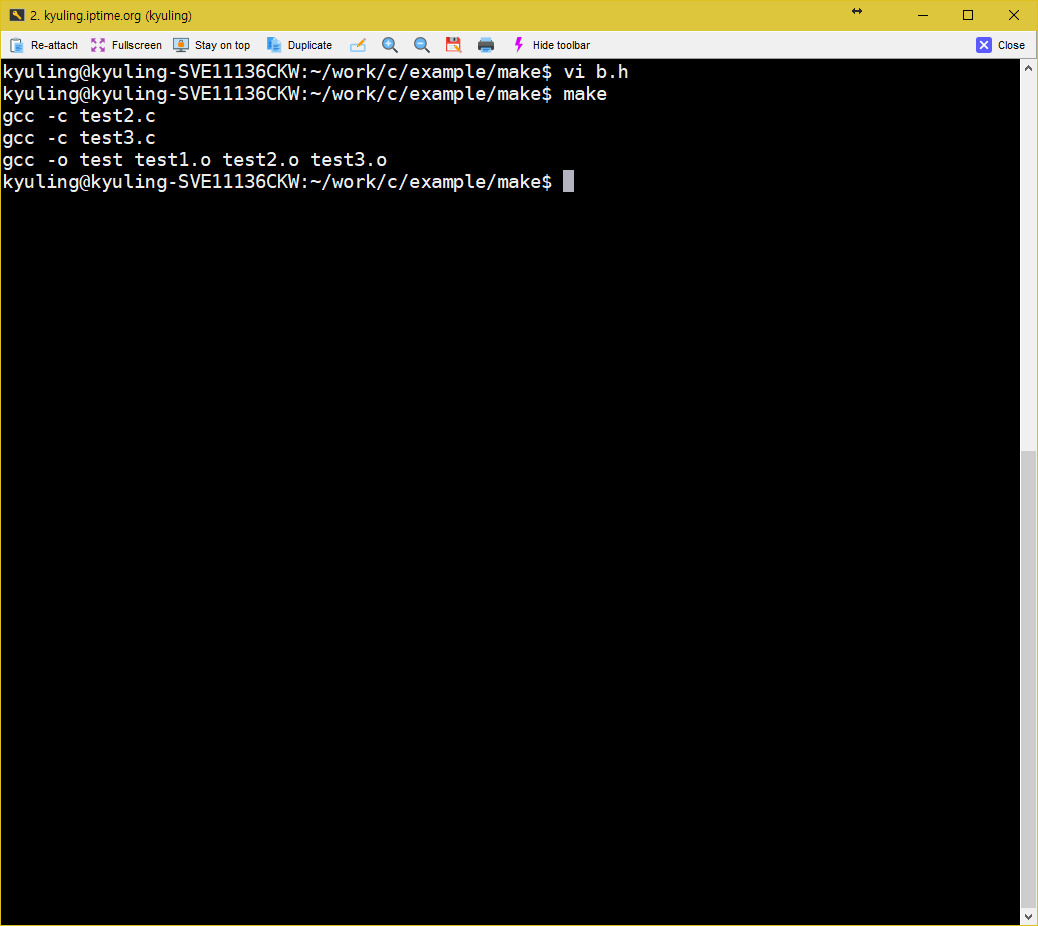
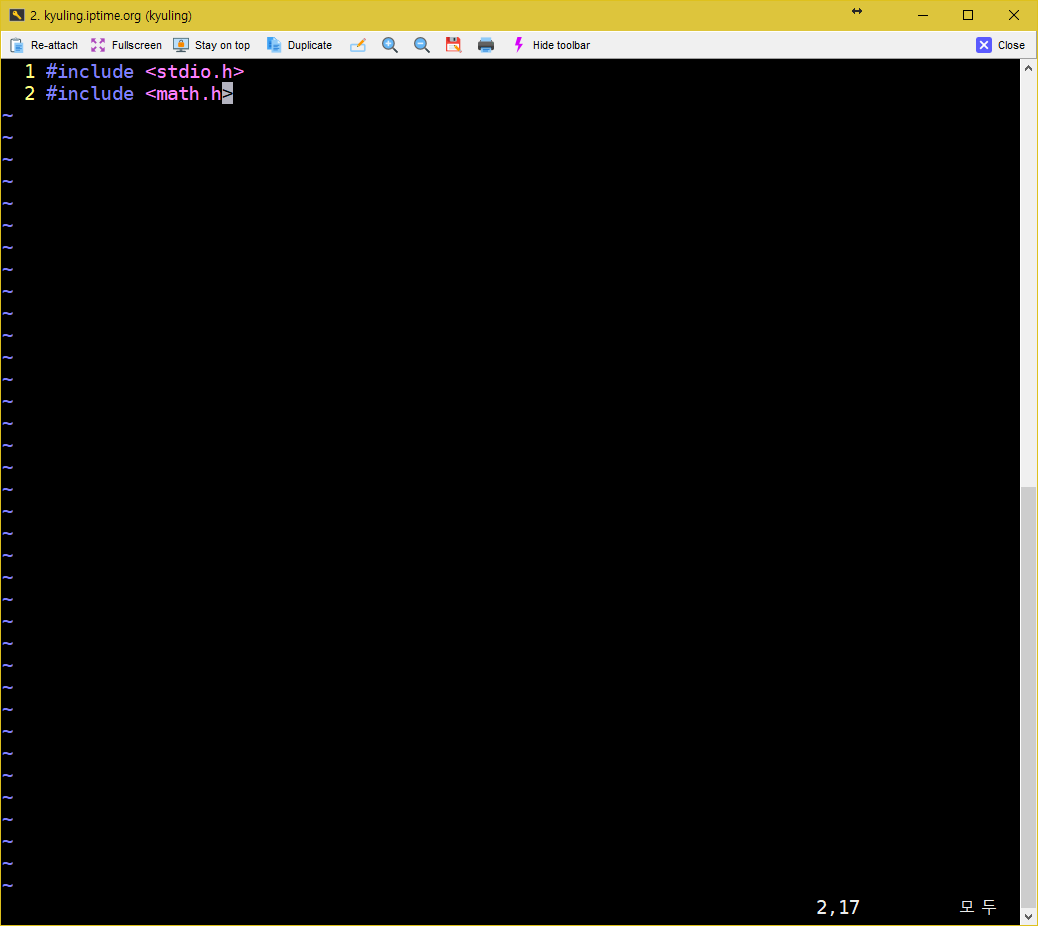
파일이 수정된 경우에 대해서도 알아보자. 우선 b.h 파일에 아까 작성하지 않았던 stdio.h를 선언해주자.
이 다음에 make를 진행하게 되면 b.h 파일이 의존성 파일 목록에 있는 작업들이 다시 실행될 것이다. test1의 경우에는 연관이 없기 때문에 빌드가 되지 않았다.
이번에는 a.h 파일을 수정하였다.
마찬가지로 a.h와 의존되는 파일이 다시 컴파일되었다. 헤더가 완전히 다 들어갔으니 경고도 날라오지 않는다.
참고로 이미 다 컴파일 되어 있는 상태에서 다시 make로 컴파일을 하게 되면 ‘up to date”라는 문장을 보게 된다. 이미 다 업데이트 되었으니 안해도 된다는 것이다.
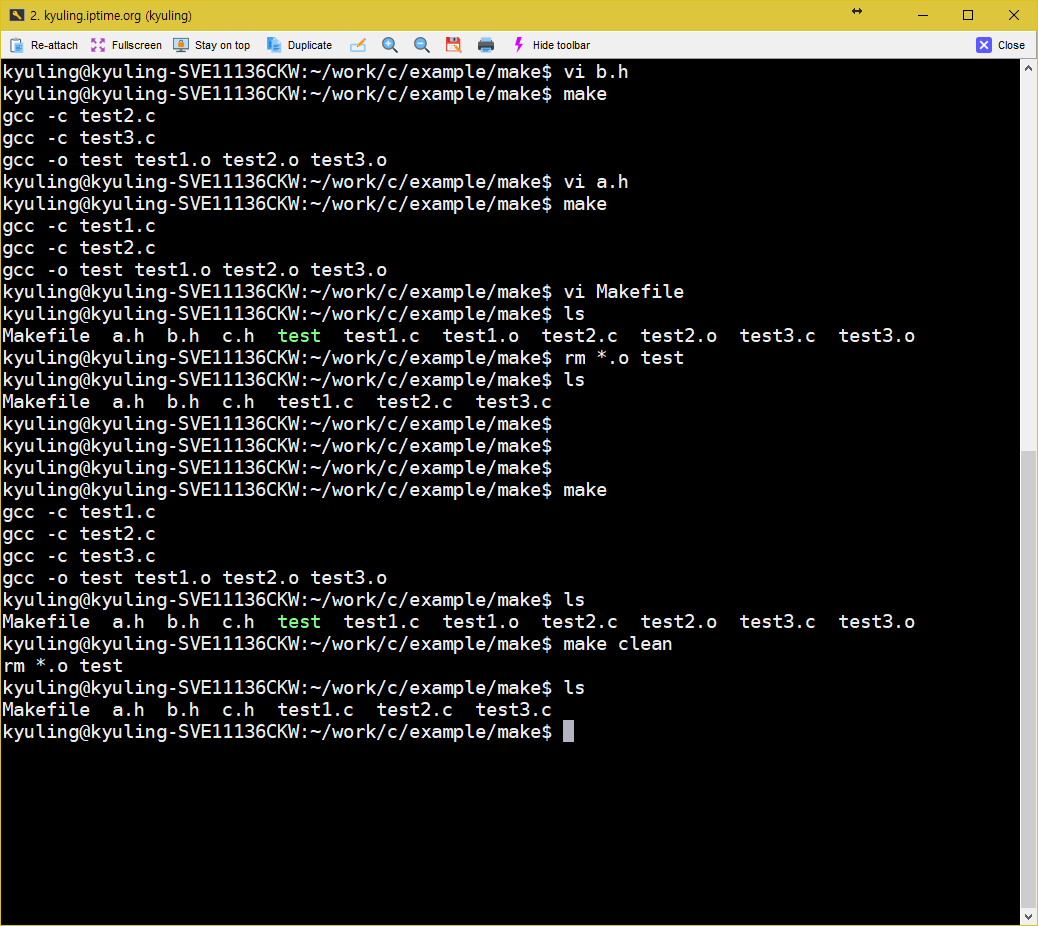
이제 레이블을 Makefile에 추가해 보겠다. clean이라는 레이블로, 다시 새로 빌드할 때마다 일일이 찾아서 지울 수 없으니 Makefile에 작성하였다.
저 명령이 정확한 것인지 쉘에 직접 입력하여 확인하였다. 오브젝트 파일과 최종 결과물인 test가 지워졌다. 그리고 이걸 다시 make로 생성 후, make clean으로 clean 레이블을 실행하였다. 그러니 삭제 코드가 그대로 실행되는 것을 볼 수 있다.
이것이 바로 make의 기본적인 사용법과 기본적인 내용이었다. 이 외에도 여러모로 알아둬야 하는 추가적인 내용 및 옵션들에 대해서도 정리를 하겠지만, 일단 이전 실습때 작성했던 C 파일들 중에 골라서 별도의 폴더를 만들고, 해당 파일과 Makefile을 만들면서 연습해 봐도 좋다.
프로그래밍을 할 때는 아무리 작은 수정이라도 수정을ㄹ 하면 소스 파일을 재컴파일해야 실행 파일에 수정 내용이 반연된다. 그런데 파일 하나나 작은 수의 파일로 이루어진 프로그램에서는 별 문제가 없으나, 여러 파일로 이루어진 대규모 프로그램인 경우에는 파일 하나만 수정해도 몯든 파일을 재컴파일해야 하게 되므로 부담이 크다. 이와 같이 여러 파일이 이루어진 프로그램을 개발할 때, 통합 개발툴의 경우에는 설정도 간단하고 자동으로 관리까지 해주니 편한 반면 리눅스 환경에서 개발을 할 경우에는 이 여러 파일로 이루어진 프로그램 코드의 컴파일을 관리해줄 수 있어야 한다.
make는 주어진 조건으로부터 대상을 만들어내는 다목적 프로그램으로, 다수의 소스 파일로 구성된 큰 프로그램 중 어떤 파일이 변경되었으므로 재컴파일이 필요한지 판단해 프로그램 개주성 작업을 효율적으로 수행하는 역할을 해준다. 그리고 이 때, 어떤 일을 해야 하는지 make에 알려줄 정보를 담고 있는 파일이 makefile이다. make 자체로도 여러모로 옵션과 기능들이 있는데 이 기능들에 대해서는 하나하나 살펴보도록 하겠다.
성능을 개선시키기 위해 코드를 최적화하여 불필요하거나 비효율적인 계산 과정을 효율적으로 대체하여 코드의 크기와 실행 시간을 줄인다. 그러면 컴파일 시간이 늘고 컴파일 과정에서 메모리 사용량이 늘어나기도 하는 단점이 존재하기도 한다. 실행 최적화를 위해 진행하는 과정에서 발생하는 것인데, 사람이 직접 최적화하는 과정 또한 존재하지만 컴파일러에 의한 자동 최적화 또한 존재한다. 이 옵션은 컴파일러에 의한 자동 최적화를 다룬다.
-O
뒤에 숫자를 써줌으로써 최적화 단계를 구분할 수 있다. gcc의 버전마다 차이가 나고, 값이 커질수록 더욱 최적화된 결과물이 나온다. 일반적으로는 -O1, -O2를 주로 이용하고, 오래된 gcc에서도 -O3까지는 기본적으로 지원한다.
-O1 | -O 옵션과 같은 간뎨의 옵션으로 최소한으로 스레드 분기 동작 횟수를 줄이고, 호출된 각 함수 반환 시 스택에 인수를 모아 두었다가 동시에 꺼내게 해준다.
-O2 | -O1 단계의 최적화와 함께 프로세서가 닫른 명령어의 결과나 캐시 메모리 또는 메모리의 데이터를 기다리는 동안 컴파일러가 다른 명령어를 실행하도록 한다. 컴파일 시간이 더 오래 걸리지만, 수정된 코드는 더 최적화되어 실행이 빨라진다.
-O3 | -O2 단계의 모든 최적화와 루프 해체, 그 밖의 프로세서 전용 특징을 포함하여 최적화한다.
이걸로 일단 간단하게 gcc의 옵션을 다 다뤄봤다. 이제 make에 대한 글로 이어지겠다.
이 블로그에서는 솔직이 엄청 간단한 레벨에서만 C 언어를 주로 다뤄왔다. 그러나, 대부분의 C 언어를 처음 다루는 사람에게는 이 예제를 따라하다가도 실수를 해서 오류가 많이 생기기도 한다. 그럴 때, 왜 컴파일이 안되지?” 하는 사람들이 있다. 사실 몇 줄 안되는 프로그램이라 쉽게 잡을 수 있다만, 몇 만 라인 이상의 프로그램의 버그를 찾는 것은 쉽지 않다. 이러한 이유로 디버깅을 위한 프로그램인 gdb를 이용하기도 한다. gdb에 대한 것은 나중에 확인해 보겠다.
-g, -ggdb 옵션은 이런 디버거를 사용해 디버깅을 할 때, 좀 더 쉽게 할 수 있도록 정보를 삽입해주는 옵션이다. 그 중에서도 -g 옵션에 대해서 살펴보겠다.
-g
-g 옵션은 디버깅 정보의 양에 따라 3 단계로 된다. -g1, -g2, -g3 이렇게 구성되어 있는데, -g로만 하면 기본적으로 -g2로 인식된다. 이 단계에 대한 자세한 내용은 다음과 같다.
-g1 | 역추적 스텍 덤프 생성에 필요한 정보를 포함하지만 지역 변수, 문장 번호를 위한 디버깅 정보는 삽입하지 않는다.
-g2 | 확장 기호 테이블, 문장 번호, 지역과 외부 변수에 대한 디버깅 정보를 삽입한다.
-g3 | -g2 옵션의 디버깅 정보와 모든 매크로 관련 정보를 삽입한다.
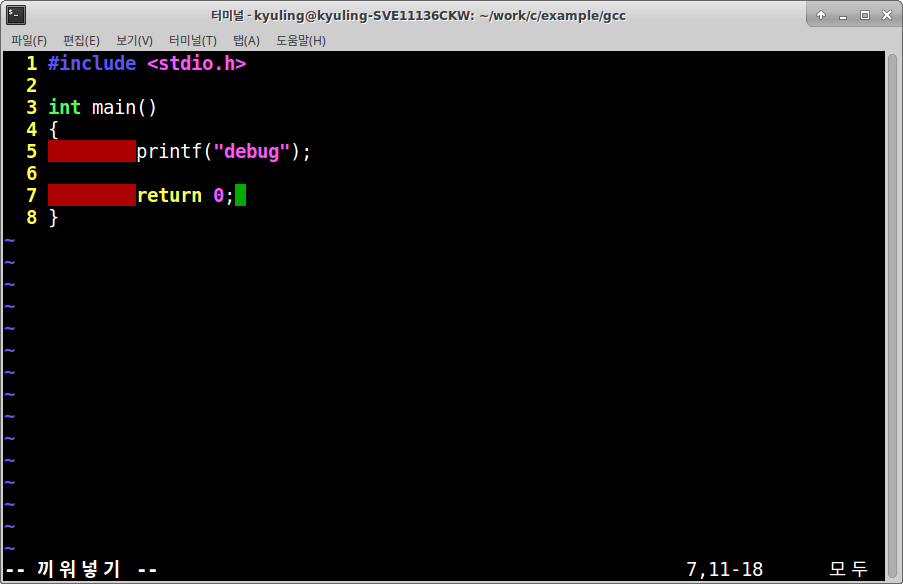
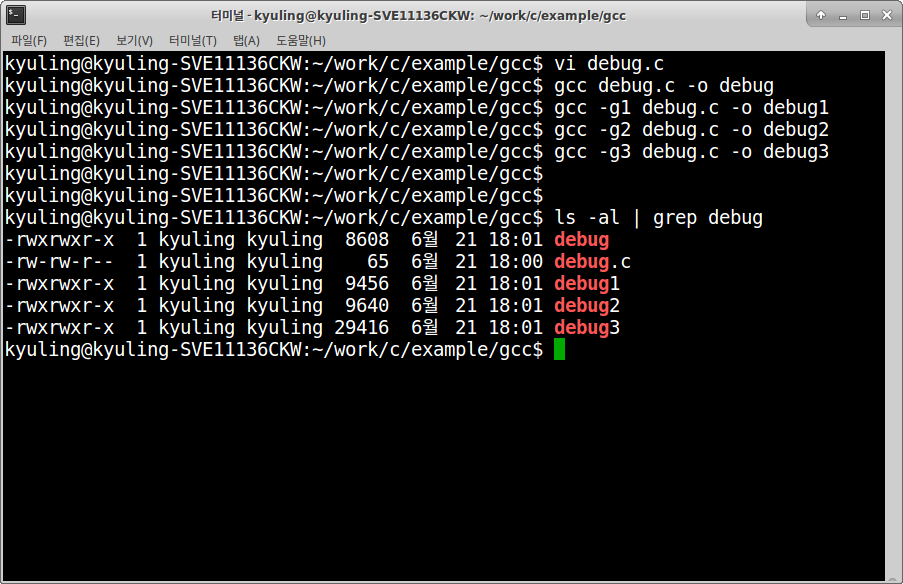
이를 확인하기 위해 간단한 예시 프로그램을 작성하였다.
hello world 레벨의 간단한 코드이다. 이 프로그램에 -g 옵션을 적용시켜 컴파일을 진행하고, 결과물의 파일 사이즈를 확인해 보기로 하였다.
옵션이 커지면 커질수록 사이즈가 늘어나는 것을 볼 수 있다. (kyuling 뒤에 쓰여진 숫자가 파일 사이즈이다.) 늘어난 사이즈만큼 디버깅 정보가 추가되었다는 것이다.
-ggdb 옵션도 -g 옵션과 거의 유사하나 다른 점이 있다면, 디버깅 작업을 도와주는 추가 정보가 필요하고, gdb 외에 다른 디버그에서는 사용이 불가능하다.
-g, -ggdb 옵션에 의한 디버깅 코드 삽입은 파일의 크기를 크게 하기 때문에 최종 실행 파일을 생성할 때에는 이러한 옵션을 주지 말고 컴파일 하는 것이 바람직하다. 이 옵션들에 의해 실행 속도 및 실행 과정에서의 차이가 발생한다. 또한 최적화된 코드의 경우에는 디버깅을 어렵게 만들기 때문에 최적화 수행은 디버깅이 다 끝난 다음에 하는 것이 좋다.
라이브러리를 지정하는 옵션 이전에, 일단 라이브러리에 대해서 간단하게 정의하고 이걸 어떻게 만드는지를 먼저 좀 써야 할 거 같다. 도중에 한번도 안적었었다.
라이브러리 함수에 대해서 살펴볼 때, 자주 사용되는 유용한 함수에 대한 오브젝트 파일을 모아둔 것을 라이브러리라고 한다고 하였다. 여기에 라이브러리에는 함수 목록 또한 포함된다.
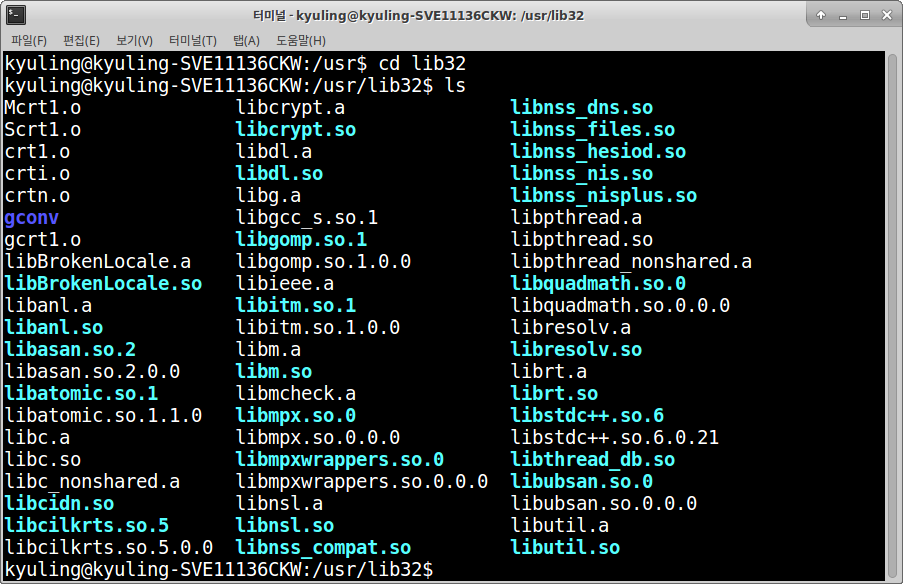
위에 화면은 예제를 만드는 노트북에 있는 라이브러리들 중 일부를 보여준다. 궁금하다면 /usr/lib32/ 폴더 안에 있는 것을 보면 된다. lib로 시작하는 이름의 파일들이 라이브러리 파일이고, 확장자는 .a다. 이 중에서 libc.a는 표준 라이브러리고, libm.a 파일은 수치 연산 라이브러리 파일이다. ar 명령어를 통해서 libc.a가 어떤 오브젝트 파일로 이루어졌는지 알 수 있다. ar 명령어는 정적 라이브러리를 생성, 조회, 편집하기 위해 이용되는 명령어이다.
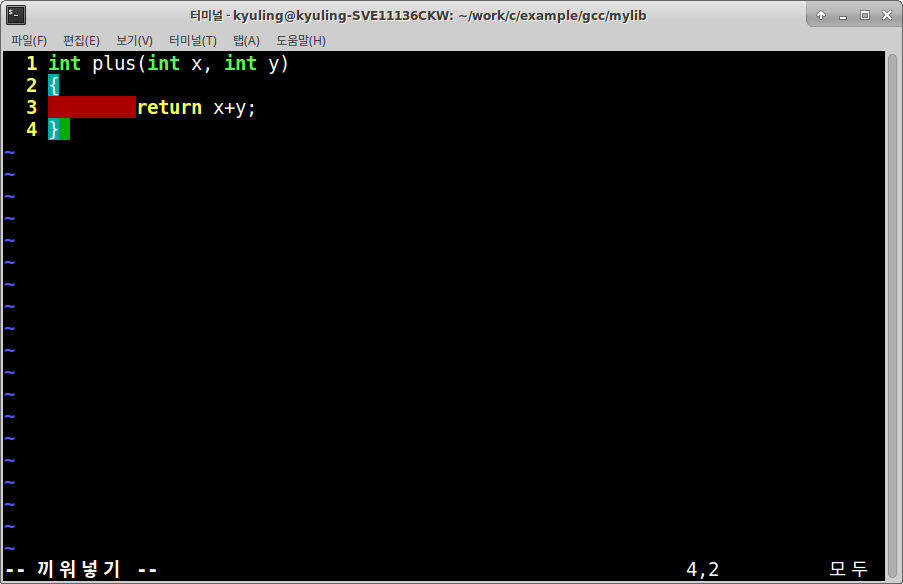
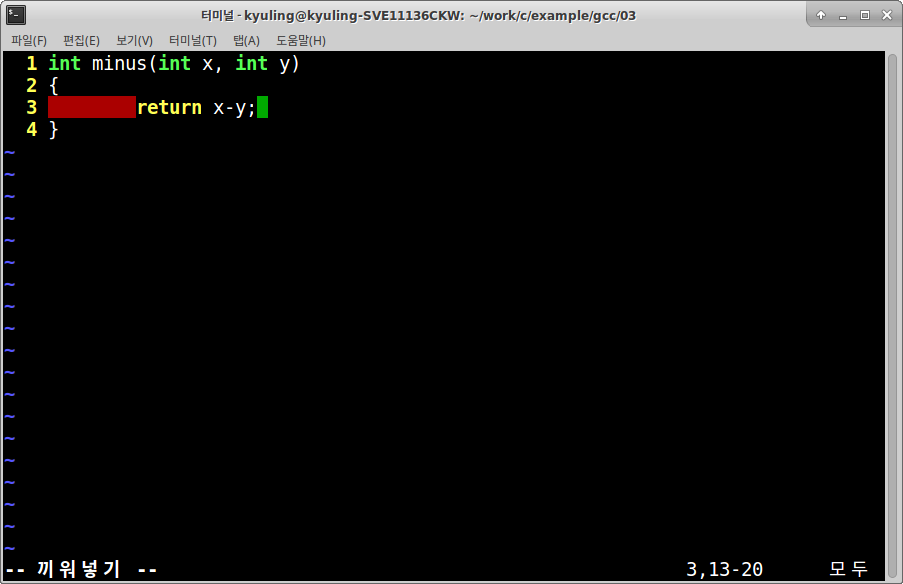
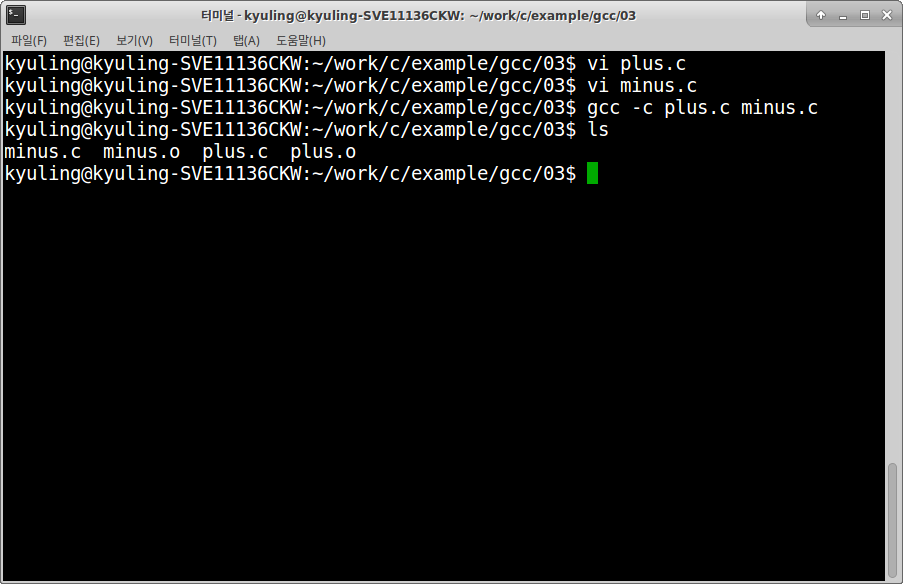
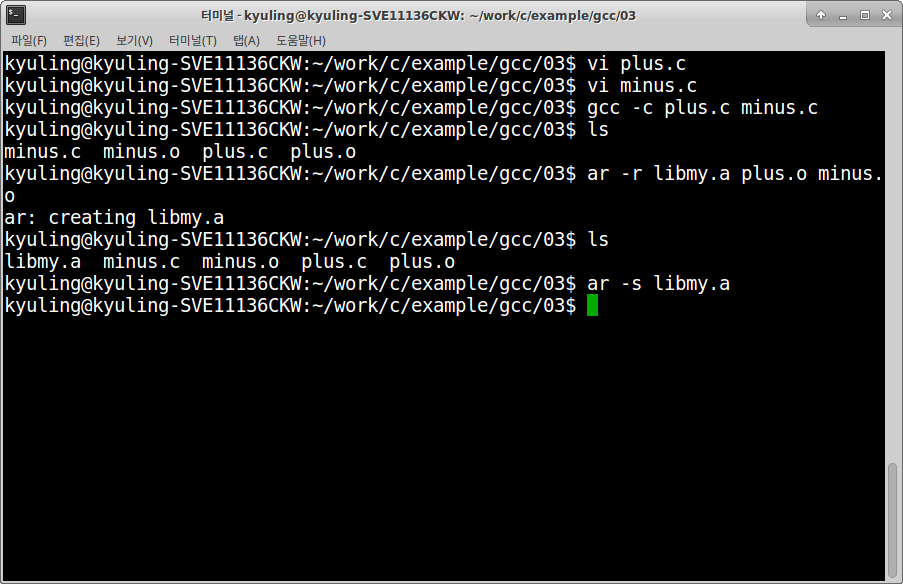
라이브러리를 직접 만들어보기 위해서 실제로 예시를 작성해 보기로 하겠다. 라이브러리 파일로 이용하기 위해 두 함수를 각각의 파일로 만들어서 오브젝트 파일까지 만들었다.
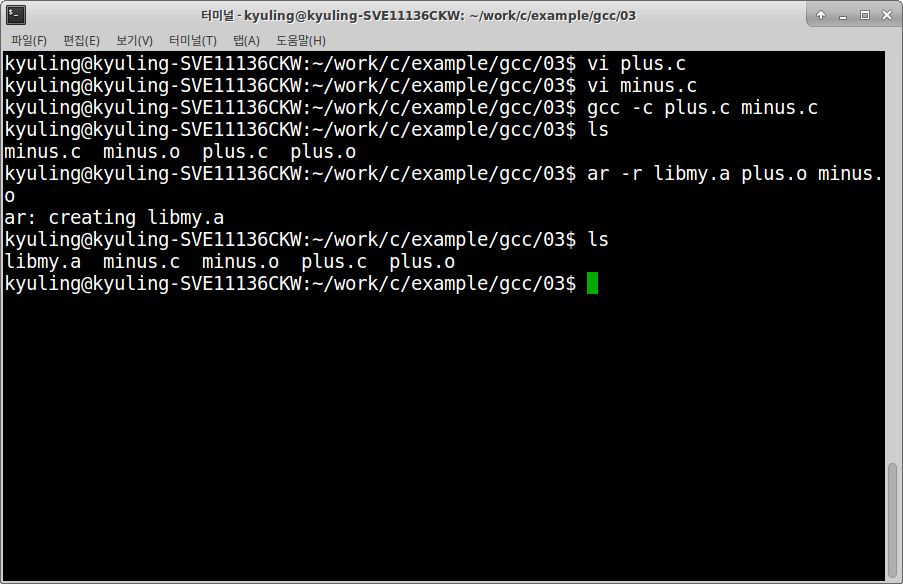
이제 plus, minus 함수를 이용할 수 있는 라이브러리 파일을 생성할 준비가 끝났다. ar 명령어를 사용하면 라이브러리 파일을 생성할 수 있는데, r옵션을 이용하여 .a 파일을 먼저 생성한다.
라이브러리가 생성되었다. 그리고 나서 이제 라이브러리에 목록을 추가하여 완벽하게 처리해야 하는데, s 옵션을 이용하면 알아서 목록을 생성한다.
이제 해당되는 옵션에 대해서 살펴보도록 하겠다.
-l
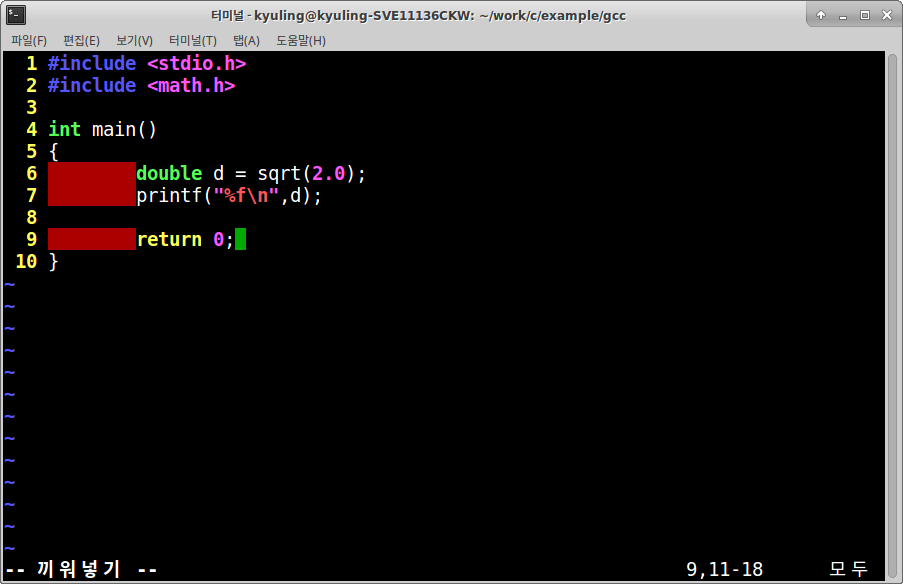
표준 라이브러리가 아닌 라이브러리를 사용하고자 할 때 그 라이브러리를 지정해 주는 옵션이다. 여러 라이브러리가 존재하는데, libc 표준 라이브러리에 없는 표준 함수를 이용하고자 할 때에 이용이 필요하다. 예제를 만들어봤다.
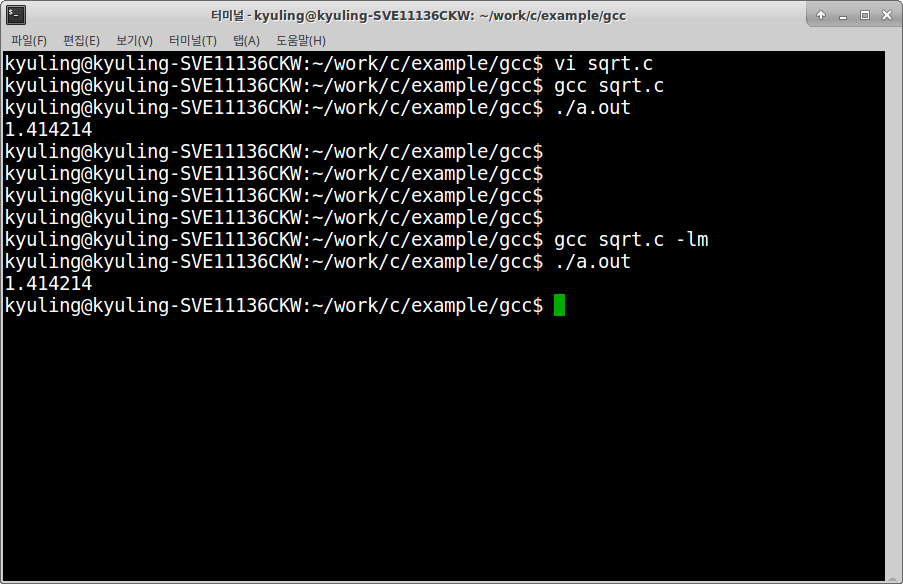
수학 함수이다. sqrt 함수인데, math.h 함수 안에 정의되어 있으며 libm.a에 정의되어 있다. 실제로 코딩을 진행하고 gcc로 실행하면 에러가 나야 정상이다. (?!)
양쪽 다 실행되었는데, 규링의 환경이 문제가 있는지 추가 글을 작성해야 할 거 같다.
원래대로라면 위에서 그냥 컴파일하면 gcc에서 오류를 내야 한다. 그래서 -l옵션을 통해 어떠한 라이브러리를 이용해야 할 것인지를 적어야 하고, 적는 이름은 lib와 뒤에 확장자를 제외한 나머지를 그대로 쓰는 것이다. lib[m].c 를 쓰기 때문에 대괄호로 작성한 m만 적는 것이다.
-L
사용할 라이브러리 위치를 지정해주므로써 사용자가 라이브러리 파일을 직접 만들어 사용하거나 새 라이브러리를 내려받아서 사용할 때 이용한다.
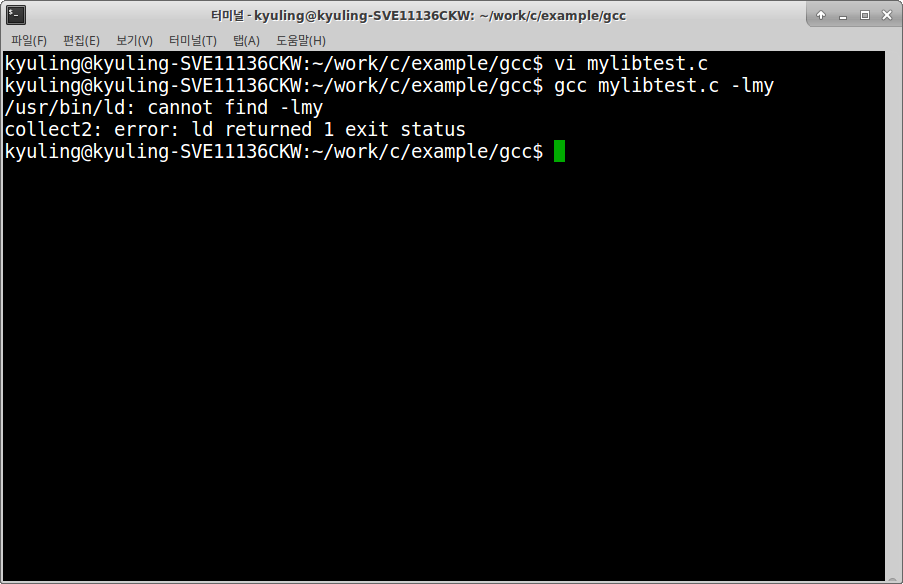
아까 만든 libmy.a를 이용한 예제 코드를 작성하였따.
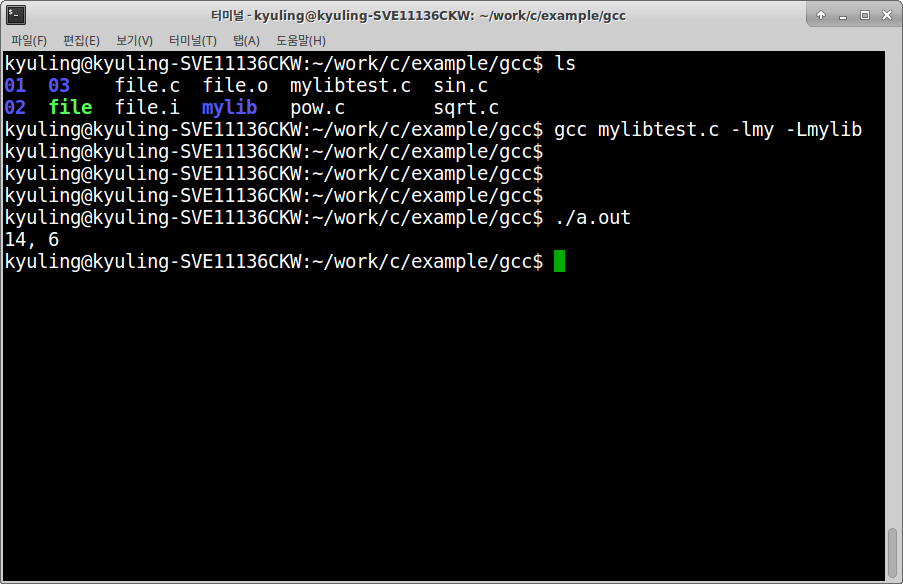
ld 링커가 에러를 냈다. 라이브러리를 찾을 때, /lib나 /usr/lib* 와 같이 정해진 디렉토리만을 찾기 때문에 그 안에 없는 libmy.a를 쓰려고 하니 오류가 발생한 것이다. libmy.a 라이브러리를 mylib 폴더로 복사해뒀다. 그래서 이걸 이용하고자 한다. 옵션 뒤에 폴더를 그대로 작성하면 된다.
라이브러리 관련된 옵션은 주로 링크에 관련된 옵션이 주로 존재하였고, 필요에 따라서 링크를 추가해주면 되는 경우가 상당히 많다.