https://youtu.be/ONMhXMxmt20
리눅스 시스템에서 파일 시스템이 없는 경우에 커널 패닉이 일어난다고 했는데, 실제로도 일어나는지를 보여주기 위해서 화면 캡쳐를 통해서 직접 보여주도록 하였다.
규링의 잡소리 & 작업장 페이지
https://youtu.be/ONMhXMxmt20
리눅스 시스템에서 파일 시스템이 없는 경우에 커널 패닉이 일어난다고 했는데, 실제로도 일어나는지를 보여주기 위해서 화면 캡쳐를 통해서 직접 보여주도록 하였다.
도커의 이미지와 컨테이너 개념글에서 다뤘던 내용입니다만, 도커는 실행중에 변경된 부분을 이미지로 생성할 수 있다고도 적었습니다. 이게 가능하도록 하는 것이 바로 Union File System(UnionFS)입니다.
이 파일 시스템은 읽기 전용의 파일 혹은 디바이스에서 변경 사항을 기록하여 저장할 수 있도록 해주는 파일 시스템이다. 읽기 전용 파일을 실행할 경우, 해당 파일에 대해 쓰기가 가능한 임시 파일을 생성하여 읽기 파일을 그대로 복제하여 실행을 하게 된다. 그 다음, 수정이 된 내용에 대해 모두 사용하였다면 쓰기 작업을 진행한 다음, 기존의 읽기 파일을 대체한다. 이러한 방식을 Union Mount라고 한다.
도커에서도 해당 이미지 파일을 기본적으로 UnionFS가 지원되는 파일이다. 이 파일을 위의 Union Mount 처리를 하여 지속적인 변경 사항을 작성하여 업데이트 되는 것이다.
UnionFS를 잘 이용한 방식은 리눅스 배포판 중에 크노픽스(Knoppix)라는 배포판이 있다. 이 배포판은 CD 혹은 DVD에서 실행하는 라이브 운영체제 형식으로 배포되는데, 부팅 과정과 운영체제의 기본 실행은 램디스크에서 부팅 및 실행을 하면서도 변경된 사항에 대해서는 컴퓨터에 연결된 보조 저장장치(쓰기 가능)에 저장을 하여 다음에 실행될 때 해당 변경사항을 부팅 후 읽어들여서 적용시킨다.
운영체제에서는 메모리 사용을 기준으로 커널 영역(커널 공간)과 사용자 영역(사용자 공간)을 나눕니다. 운영체제가 부팅될 때, 부팅을 위해 이용되는 맨 앞의 작은 용량 다음에 운영체제 자체의 핵심 기능들을 실행하기 위해 올려놓는 공간을 주로 커널 영역이라 하고, 그 외에 영역에 대해서는 사용자가 이용할 수 있는 영역이라 하여 사용자 영역이라고 합니다.
이제 여기서 사용자 영역에서 실행되는 실행 파일과 라이브러리를 유저랜드라고 합니다. 특히 리눅스의 경우에는 커널만으론 부팅을 할 수 없습니다. 그래서 파일시스템에서 데이터를 불러오는데, 이때 불러오는 것은 부팅에 필요한 최소한의 실행 파일과 라이브러리, 그리고 고유의 패키징 시스템을 포함한 데이터를 불러옵니다. (시스템 데몬, 윈도우 라이브러리, 그래픽 라이브러리, 그 외 각종 라이브러리 등) 이 라이브러리들을 불러오면서 가상 메모리를 이용할 수 있게 되는 것 뿐만 아니라 사용자가 사용할 수 있는 공간을 만들 수 있도록 해줍니다. 운영체제 내용 정리할 때 다시 저세히 다루기로 하죠.
음.. 뭐랄까. 도커에는 이미지와 컨테이너라는 개념이 있는데, 이 기본적인 부분에 대해서도 사실 좀 나눠서 설명할 수 있느냐 아니냐에 따라서도 이야기가 좀 달라집니다. 조금만 보면 금방 다른 이야기라는 것이 알 수 있지만, 한번의 설명글이 있는 쪽이 좀 더 좋겠군요. 우선 이미지가 좀 많이 좋은 것이 있어서 그걸 가져와서 설명을 하겠습니다.
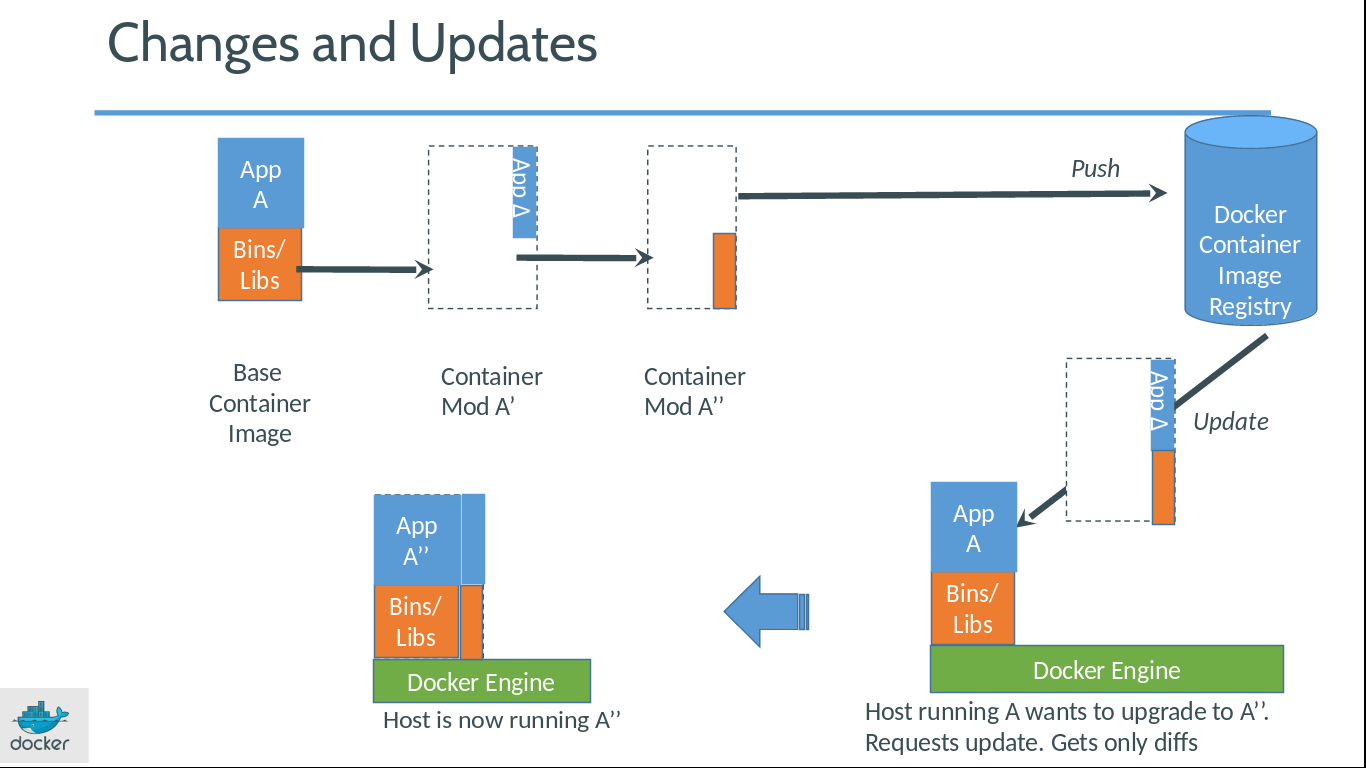
우선은 가장 기본이 되는 베이스 이미지가 있습니다. 이는 리눅스 배포판의 유저랜드만 설치된 파일을 말합니다. 보통은 리눅스 배포판 이름으로 구성되어 있습니다. 아니면 리눅스 배포판 유저랜드(사용자 공간)에 Redis나 Nginx 등이 설치된 베이스 이미지도 만들 수 있습니다. 그래서 도커의 이미지라고 하면 주로 베이스 이미지에 필요한 프로그램과 라이브러리, 소스를 설치한 뒤 파일 하나로 만들어낸 것을 가리킵니다. 각 리눅스의 배포판 이름으로 된 베이스 이미지는 배포판 특유의 패키징 시스템을 이용할 수 있습니다. 우분투라면 apt-get을, 레드햇 계열이라면 요즘은 DNF를 이용하겠군요. 또한 원하는 베이스 이미지는 직접 만들어서 사용할 수 있습니다.
근데 이것이 매번 베이스 이미지에다가 필요한 프로그램과 라이브러리, 소스 등을 추가하다 보면 용량이 큰 이미지가 지속적으로 생길 것이라고 생각하는데, 위의 그림과 같이 변화된 곳만 별도로 이미지가 생기고, 실행할 때에는 베이스 이미지와 바뀐 부분이 합쳐져서 실행됩니다. 그래서 도커는 초기 환경이나 업데이트된 환경이나 그렇게 큰 구조를 가지지 않습니다.
아래에는 도커 이미지에 대한 버전 업데이트의 의존 트리를 보여줍니다. 구조를 보시면 개발자들이 개발한 소스코드의 버전 관리 트리와 비슷한 구조인 것을 보실 수 있습니다.

거의 git하고 비슷하죠. 16진수의 특정 ID로 구분되고, 각 이미지에 대해서는 독립적인 형태로 진행됩니다. consumer, nodeflakes, nodeflakes-server로 최종적인 구조에서 별도의 작업 단위로 branch가 진행되어 조금씩 수정되어 이용되는 구조인 듯 합니다. 정리하자면, 도커는 이미지를 통째로 생성하지 않고, 바뀐 부분에 대해서만 생성을 진행한 뒤, 부모 이미지를 계속 참조하는 방식으로 동작합니다. 도커에서는 이를 “레이어”라고 합니다.
도커의 이미지는 파일입니다. 그렇기 때문에 저장소에 올린 뒤에 다른 곳에서도 받을 수 있습니다. 그리고 저장소에 올릴 때에는 자식 이미지와 부모 이미지를 함께 올립니다. 받을 때도 똑같습니다. 이후에는 수정된 이미지만 주고 받는 구조입니다.
이미지에 대한 설명은 여기까지이고 이제 컨테이너에 대한 설명을 하겠습니다. 컨테이너는 이미지를 “실행한 상태”입니다. 이미지로 여러 개의 컨테이너를 만들 수 있습니다. 운영체제로 생각해 본다면 이미지는 [실행 파일]이고 컨테이너는 [프로세스]입니다. 이미 실행된 컨테이너에서 변경된 부분을 이미지로 생성할 수도 있습니다. 이렇게 운영체제와 비교해서 보니, 도커는 특정 실행 파일 또는 스크립트를 위한 특정 실행환경이라고도 볼 수 있겠군요. 그러면 이제 앞에서 봤던, 아래의 그림과 같은 설명이 이해가 되는 겁니다. 하이퍼바이저와 게스트 운영체제의 자리를 도커가 가지고 가는 구조죠.

리눅스와 유닉스 계열에서는 파일 실행에 필요한 모든 구성요소가 잘게 쪼개져 있습니다. 이는 시스템 구조가 단순해지고 명확해지는 장점이 있습니다만 의존성 관계를 해결하기 어려워지는 단점을 가지고 있습니다. 그래서 리눅스와 유닉스 계열에서는 각 배포판마다 미리 컴파일 된 형식으로 프로그램을 배포하고 그 의존성을 미리 검사할 수 있는, 일명 패키지라는 시스템이 만들어지게 됩니다. 하지만 서버를 실행할 때마다 일일이 소스를 컴파일하거나 패키지를 설치하고 설정하고 하는 작업은 상당히 귀찮은 작업입니다. 서버 대수가 많아지면 더 할 말이 없습니다. 이때 도커 이미지를 사용하면 실행할 서버가 몇 대든간에 이미지를 실행하여 컨테이너를 계속 만들어 쓰면 됩니다.
도커에 대한 설명을 하다보면 거의 항상 설명하고 하는 것이 있는데, 바로 LXC(LinuX Container)입니다. 오래전부터, 리눅스/유닉스 환경에서는 chroot라는 명령어를 제공했습니다. 이 명령어는 파일 시스템에서 루트 디렉터리(/)를 변경하는 명령어입니다.
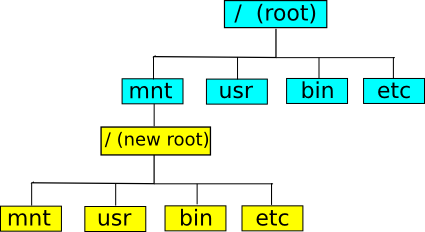
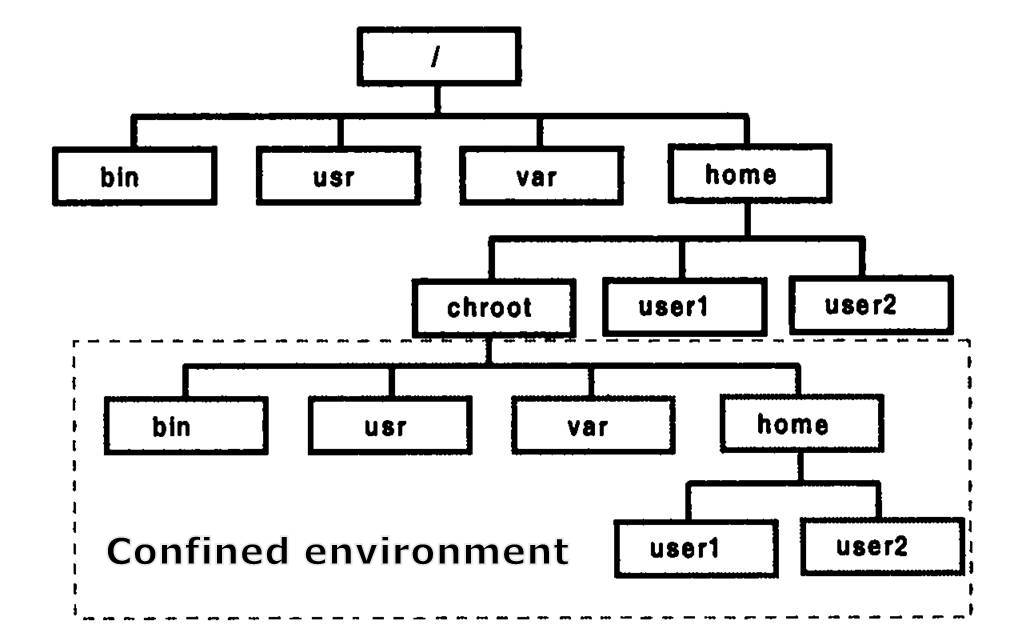
이렇게 특정 디렉토리를 루트 디렉토리로 변경하게 되면chroot jail이라는 환경이 생성되는데, 이 안에서는 바깥의 파일과 디렉터리에 접근할 수 없게 됩니다. 경로 자체가 격리되기 때문에 서버 정보의 유출과 피해를 최소화하는 데 주로 이용되어 왔던 기술입니다. 그러나 chroot는 chroot jail에 들어갈 실행 파일과 공유 라이브러리를 직접 준비해야 하고 설정 방법 또한 상당히 복잡합니다. 또한 완벽한 가상 환경이 아니기 때문에 제약 또한 상당히 많습니다. 이러한 환경을 Confined Environment라고 합니다.
이후에 리눅스에서는 LXC라는 시스템 레벨의 가상화를 제공하게 됩니다. LXC는 컴퓨터를 통째로 가상화하여 OS를 실행하는 것이 아니라 리눅스 커널 레벨에서 제공하는 일종의 격리된 가상 공간을 제공합니다. 이 가상 공간에는 운영체제가 설치되지 않고 호스트의 리눅스를 그대로 이용하기 때문에 가상 머신이라고 안하고 컨테이너라고 합니다. 아래의 이미지가 LXC를 설명하기 가장 좋은 이미지인 듯 하군요.
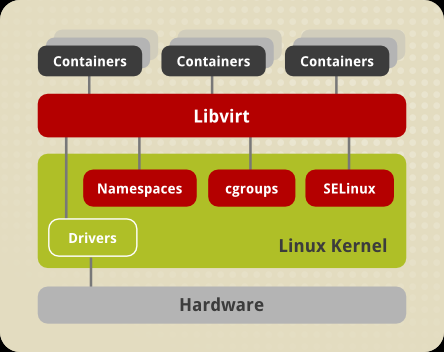
리눅스 커널의 자원 일부를 그대로 이용합니다. 리눅스 커널의 cgroups(control groups)를 통해 CPU, 메모리, 디스크, 네트웤 자원을 할당하여 완벽한 가상 공간을 제공합니다. 또한 프로세스 트리, 사용자 계정, 파일 시스템, IPC 등을 별도로 격리시켜서 호스트와 별개의 공간을 따로 만듭니다. 이렇게 격리된 곳이 바로 namespaces입니다. 마지막으로 보안 관리를 제공하는 SELinux(Security-Enhanced Linux) 또한 가상화된 공간에서 제공하여 보안도 호스트와 같은 수준으로 제공합니다. 즉, cgroups와 namespaces, SELinux 기능을 활용하여서 가상 공간을 제공하게 되는 겁니다. 추가적으로 필요한 자원이 있다면 드라이버를 가상 환경에 연결하여 지원해줍니다.
하지만, LXC는 격리된 공간에 대한 지원만을 할 뿐, 개발 및 서버 운영에 필요한 부가 기능에 대해서는 상당히 부족한 상황입니다. 도커는 이 리눅스 커널에서의 cgroups, namespaces, SELinux 기능을 기반으로 하여 이미지, 컨테이너의 생성 및 관리 기능과 다양한 부가 기능을 지원할 수 있도록 개발된 것입니다. 그래서 도커에 대한 설명을 하다 보면 자연스럽게 LXC에 대한 설명도 같이 들어가게 됩니다.
도커가 처음 개발될 당시에는 LXC를 통해 구현되었다고 과거 문서들에는 많이 나와있지만, 0.9 버전 이후로부터는 libcontainer를 개발하여 이용하는 것으로 알려져 있습니다. 도커 문서에는 실행 드라이버라고 하는데, native, lxc 중 선택해서 사용할 수 있습니다. lxc는 LXC에서 이용하던 라이브러리입니다. 어떤 것을 이용하는 것이 더 좋은지에 대해서는 여러모로 논의가 이어지고 있습니다만, 양쪽 다 열심히 업데이트 되고 있어서 어떻게 될지는 모르겠군요.
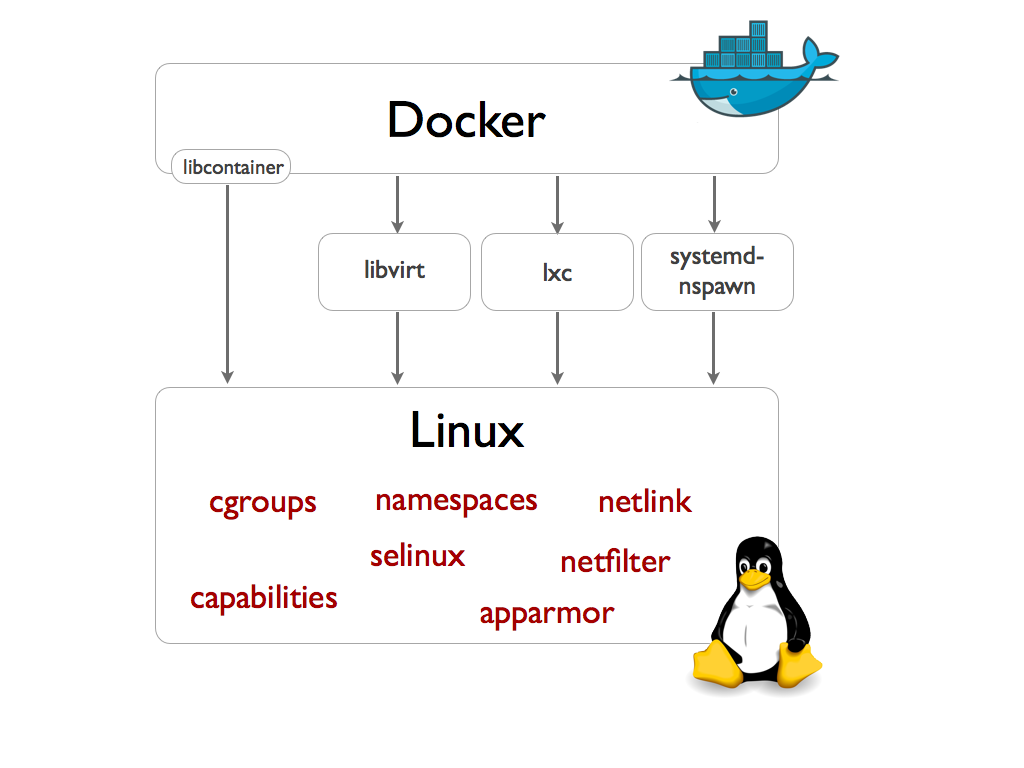
도커 자체를 사용하는 입장에서는 그렇게 어렵게 사용하진 않습니다. vmware, kvm, virtualbox, hyper-v 등의 가상 머신을 써왔다면 충분히 쓸 수 있습니다. 구조 또한 비슷합니다. 가상 머신을 만들어서 리눅스를 설치하고, 각종 프로그램과 DB를 설치 후 개발한 프로그램을 올리고 서비스를 실행했습니다. 그리고 이 가상 머신을 여러 서버에 복사해서 실행하면 이 가상 머신 하나로 여러 서버를 계속 만들어냅니다. 도커 또한 마찬가지입니다. 이미지를 만들고, 각종 프로그램과 DB를 설치 후 개발한 프로그램을 올리고 서비스를 똑같이 실행합니다.
가상 머신 서버를 독자적으로 운영하거나 클라우드에서 서비스 형태로 운영되는 PaaS에서도 가상 머신을 이용한 서버 구성을 할 수 있게 되었는데, 이 가상머신으로의 작업은 편하고 이해하기 쉽지만 성능이 좋지 못한 단점이 있습니다. 가상화를 한 CPU나 디스크의 속도는 실제 머신에 비해 훨씬 느리기 때문입니다.
클라우드에서 쓰이는 가상화 환경들은 기존에 데스크톱에서 다른 머신들을 가상화하기 위해 쓰이던 전가상화 (full virtualization) 방식이 아닌 반가상화(para virtualization)을 이용하는 방식으로 구성되었고, 현재도 널리 쓰이지만 실제 머신에 직접 이용되기에는 아직 성능적으로 부족한 부분이 있는 것이 사실입니다.
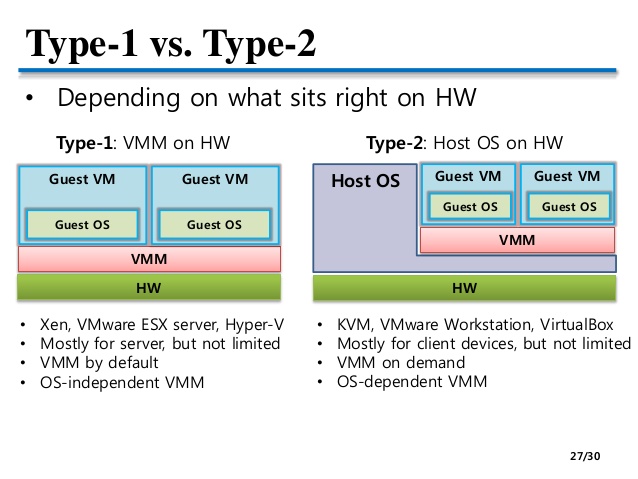
전가상화와 반가상화는 이 그림이면 설명이 될 거 같군요. 사실 가상화 이론 자체에는 이것 외에도 여러 이론들이 있습니다만, 우선은 이정도만 보면 되겠습니다. 가상 머신 자체에는 게스트 운영체제, 즉 항상 그 안에도 운영체제를 설치해야 합니다. 그러나 도커의 컨테이너 이미지에는 운영체제가 포함되지 않습니다. 그렇기 때문에 가상머신에 비해 훨씬 가벼운 상태가 됩니다. 또한 가상머신 이미지를 여러 서버에 옮겨가는 작업은 네트워크로 이루어지게 될 텐데, 네트워크 속도가 아무리 빨라졌다고 하더라도 운영체제가 설치된 이미지 자체의 용량을 생각하면 결코 적은 용량이 아니게 됩니다. 따라서 배포에 대해서도 부담이 되게 됩니다. 반면에 도커는 게스트 운영체제를 설치하지 않고 이미지에 서버 운영을 위한 프로그램과 라이브러리만 특정하게 격리해서 설치할 수 있고(샌드박스 상태라고 보시면 됩니다.), 운영체제의 자원은 호스트의 자원을 그대로 이용합니다. 이렇게 되면 이미지 용량 자체가 크게 줄어들게 되니 배포에도 부담이 없게 됩니다.
가상 머신과 비교되는 구조입니다. 한 눈에 봐도 도커를 이용한 시스템은 호스트와 그대로 작업이 처리되는데 반해 가상 머신을 이용한 쪽은 중간에 있는 게스트 운영체제에 의해 또 다시 제어되는 걸 볼 수 있습니다.
하드웨어를 가상화하고 운영체제를 가상화 하는 곳 자체가 없기 때문에 메모리 접근 속도, 파일시스템 사용 속도, 네트워크 속도 등에서 가상머신에 비해 월등히 빠른 속도를 가집니다. 도커에서 동작하는 속도를 측정한 표가 검색해서 나왔길래 같이 보도록 하죠. Linpick이라는 테스트 툴을 이용하여 호스트, kvm(가상머신), 도커를 비교한 표입니다.
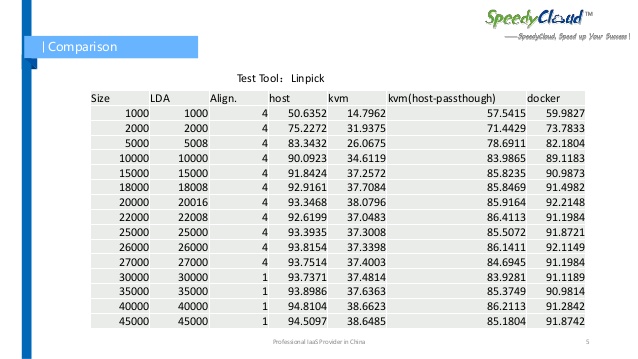
어떤 상태에서는 도커가 호스트보다 빠를 때도 있지만, 대게 호각이거나 거의 차이가 나지 않을 정도라 해도 될 정도로 미미한 차이가 발생하는 수준이군요. 그에 비하면 가상머신인 kvm의 속도는 확실히 차이가 납니다.
이러한 도커는 관리 몇에 있어서도 이미지 생성과 배포 자체에 특화된 관리 기능을 가지고 있습니다. 앞의 글에서도 도커는 파일 형태로 되어 있으며, 소스 코드 버전 관리처럼 관리할 수 있다고 했는데, 실제로 도커 이미지는 소스 관리하듯 관리할 수 있습니다. 또한 중앙에서 이미지를 올리고 받을 수 있는데, git에서 소스코드 올리고 받는 기능과 같다고 보면 됩니다. (push/pull 기능) github와 같은 기능을 하는 Docker hub(유료)도 존재합니다. 또한 API를 다양하게 지원하기 때문에 원하는 만큼 자동화도 할 수 있습니다. 따라서 개발 및 운용에서도 유용하게 할 수 있습니다.
여러 글을 쓰기로 마음먹었지만, 우선 Docker(도커)에 대해서 좀 써봐야 할 거 같습니다. 거의 모든 환경에서 많이 이용하고 있는 만큼 중요하다고 생각하네요.
도커는 Docker, inc에서 출시한 오픈소스 컨테이너 프로젝트입니다. 나온지는 얼마 안되었지만 요즘 엄청나게 이용되고 있고, 현재도 많은 스터디 그룹이 만들어져서 여기저기서 이용하고 있는 것이기도 하죠.
요즘 도커를 이용하려는 이유는 확실히 있습니다. 2009~2010년을 지나면서, 수많은 시스템들이 클라우드로 옮겨가고 있습니다. 클라우드로 옮겨가게 되면, 실제의 물리 서버를 구입하는 것이 아닌 가상 서버를 구입하고 사용하는 양만큼의 요금을 지불하게 되었습니다. 게다가 가상 서버의 구축의 경우에는 그냥 몇 번의 클릭만으로도 쉽게 할 수 있는 상황입니다.
이제 여기서 문제가 생깁니다. 가상 서버에 소프트웨어를 원하는 대로 설치하고 설정을 해야 하는데, 댓수가 많아지면 사람이 직접 하는 데 있어서 여러모로 힘들어집니다. 셸 스크립트로 설치 및 설정을 자동화하는 기술들도 리눅스 환경을 이용하던 사람들은 많이 써왔습니다. 그런 상황에서도 힘든 것이 중앙 관리 기능이나 좀 더 복잡해지는 기능들입니다. 그런 부분은 셸 스크립트로 쓰기 엄청 어려워집니다. 리눅스 서버를 써보신 분들은 아시겠지만, 리눅스 환경에서는 설치만 했다고 해서 거의 바로 쓸 수 있는 상황이 아니게 됩니다. 응용 프로그램도 많고, 호환성이 제대로 이루어졌는지도 보고, 설정 또한 여러 설정을 다 해줘야 하기 때문에 상당히 복잡해집니다. 따라서 클라우드 환경에서의 설치와 배포 기능은 엄청 어려운 일이 되고 말았습니다. 이게 은근 골아픈 것이, 실제로 보면 사소한 설정 하나땜에 운영체제와 서비스의 동작에 영향이 엄청나게 가게 되면 서비스를 하기 힘들어집니다.
이런 상황에서 여러 아이디어가 나오게 됩니다. 가상머신의 복제를 통해서도 여러 시스템을 복제해서 설정을 바꿔 쓰기도 하지만, 설정이 복잡하면 그게 쉬운 설정은 아니게 됩니다. 그런 상황에서 나온 이론이 바로 Immutable Infrastructure입니다. 현재는 하나의 패러다임 취급되고 있는 이것은, 호스트 운영체제와 서비스 운영 환경을 분리하고, 한 번 설정한 운영 환경은 변하지 않는다는 개념(Immutable)을 도입한 것입니다. 즉, 서비스 운영 환경을 이미지라는 특정 환경으로 설정한 후, 서버에 배포하여 설행을 합니다. 이때, 서비스가 업데이트되면 운영 환경 전체가 변하는 것이 아니라 이미지만 새로 생성하여 배포하는 것으로 끝납니다. 클라우드 플랫폼에서 서버를 쓰고 버리는 것처럼, Immutable Infrastructure에서도 서비스 운영 환경 이미지를 한 번 쓰고 그냥 버립니다. 음… 그림으로 보면 좀 더 이해가 될까요.
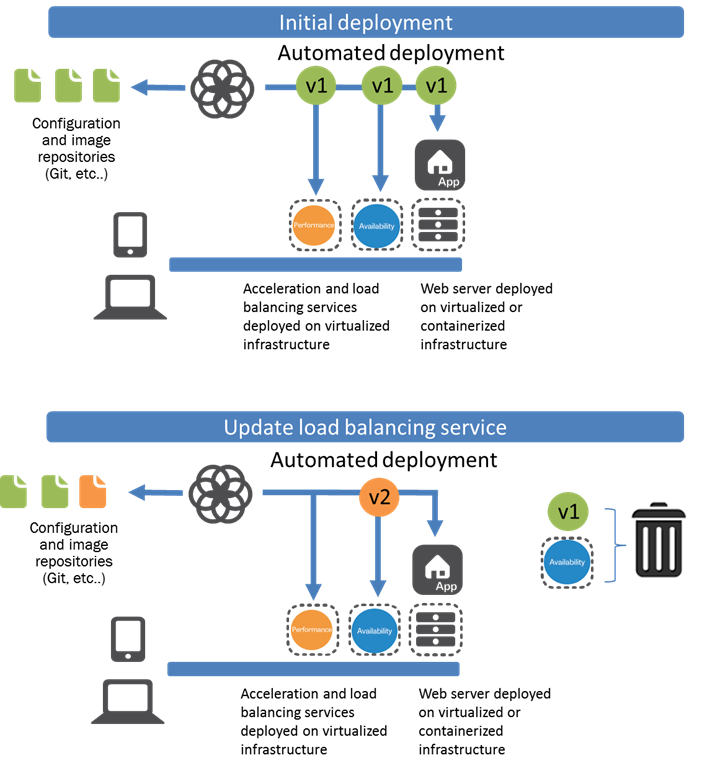
Immutable Infrastructure를 검색하면 나오는 이미지 중에 좀 이해가 쉬울 법한 것을 찾아봤습니다. 초기 생성에 대해서는 버전 생성이 그대로 이루어졌고, v2로 업데이트가 되면 업데이트 된 이미지가 적용되어 수정된 내용 그대로 적용되고, 기존의 버전을 버려집니다. 이런 시스템을 이용함으로써 여러 장점이 있습니다.
관리의 편리성: 서비스 운영 환경을 이미지로 생성했기 때문에 이미지 자체만 관리하면 됩니다. 특히 이미지를 중앙에서 관리하여 체계적인 배포와 관리가 가능해졌습니다. 또한, 이미지 생성 및 설정도 파일로 되어 있기 때문에 버전 관리 시스템을 활용하여 관리할 수 있습니다.
확장성: 이미지 하나로 서버를 계속 찍어낼 수 있습니다. 이건 클라우드 플랫폼의 자동 확장 기능과 연동하면 손쉽게 서비스를 확장할 수 있습니다.
쉬운 테스트: 개발자의 PC나 테스트 서버에서 이미지를 실행하기만 하면 서비스 운영 환경과 동일한 환경이 구성됩니다. 그래서 테스트하기 쉬워집니다.
가벼움: 운영체제와 서비스 운영 환경이 분리되었다는 것은 그만큼 가볍게 만들 수 있고 어디서든 실행 가능한 환경을 제공할 수 있다는 것이 됩니다. 특히 운영체제와의 분리로 인한 가벼움은 하나의 장점이 될 수 있습니다.
이런 Immutable Infra의 대표적인 격으로 쓰이는 것이 바로 도커입니다. 상징되는 고래 또한 위에 컨테이너라는 이미지를 싣고 있는데, 저장과 배포 기능에 대한 것을 의미한다고 하는군요.
![]()










