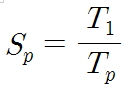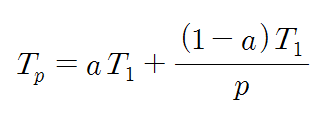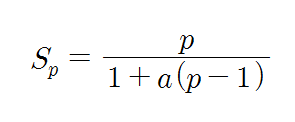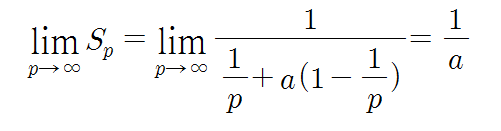컴퓨터시스템을 분류하는 방식은 여럿 존재한다. 가장 널리 사용되는 방식이 바로 Flynn의 분류(Flynn’s classificaation) 방식이다. 방식 이름은 어색할 지 모르겠지만, 내용을 보면 아마 금방 “아, 그거!”할 것이다. 이 분류 방식에서는 프로세서들이 처리하는 명령어와 데이터의 스트림의 수에 따라 디지털 컴퓨터를 네 가지로 분류하고 있다. 여기서 맘ㄹ하는 스트림이란 하나의 프로세서에 의하여 순서대로 처리되는 일련의 명령어들과 데이터들의 흐름을 말한다. 즉, 명령어 스트림이란 프로세서에 의해 실행되기 위하여 순서대로 나열된 명령어 코드들의 집합을 의미하고, 데이터 스트림이란 그 명령어들을 실행하는 데 필요한 순서대로 나열된 데이터 집합을 의미한다.
명령어와 데이터 스트림을 처리하기 위한 하드웨어 구조에 따른 Flynn의 분류와 간략한 설명은 다음과 같다.
- SISD 조직(Single Instruction stream Single Data stream): 한 번에 한 개씩의 명령어와 데이터를 순서대로 처리하는 단일프로세서 시스템에 해당한다. 이러헌 시스템에서는 명령어가 순서대로 실행되지만, 실행 과정은 여러 개의 단계들로 나누어 시간적으로 중첩시킴으로써 실행 속도를 높이도록 파이프라이닝되어 잇는 것이 일반적이다. 또한 SISD 시스템에서 하나의 프로세서 내에 여러 개의 명령어 실행 유니트들이나 ALU 들을 포함함으로써, 동시에 두 개 혹은 그 이상의 명령어들을 동시에 실행하는 슈퍼스칼라(superscalar) 구조도 많이 사용되고 있다. 파이프라이닝과 슈퍼스칼라는 프로세서 내부에서 병렬처리를 이용하는 구조라고 할 수 있다.
- SIMD 조직(Single Instruction stream Multiple Data stream): 배열 프로세서(Array Processor)라고도 불린다. 이러한 시스템은 여러 개의 프로세싱 유니트(PU)들로 구성되고, 프로세싱 유니트들의 동작은 모두 하나의 제어 유니트에 의해 통제된다. 모든 PU들은 하나의 제어 유니트로부터 동일한 명령어를 받지만, 명령어 실행은 서로 다른 데이터에 대하여 이루어진다. 또한 모든 PU들이 기억장치를 공유하는 경우도 있고, 각 PU가 기억장치 모듈을 독립적으로 가지는 분산 기억장치 구조도 가능하다.
- MISD 조직(Multiple Instruction stream Single Data stream): 한 시스템 내에 n개의 프로세서들이 있고, 각 프로세서들은 서로 다른 명령어들을 실행하지만, 처리하는 데이터들은 하나의 스트림이다. 다시 설명하면, 프로세서들이 파이프라인 형태로 연결되어서, 한 프로세서가 처리한 결과를 다음 프로세서로 보내는 방식이다. 그러나 이 조직은 컴퓨터 구조 설계자들이 관심을 끌지 못하고 있으며, 실제로 이러한 시스템은 이론으로만 존재한다.
- MIMD 조직(Multiple Instruction stream Multiple Data stream): 대부분의 다중프로세서 시스템(multiprocessor system)과 다중컴퓨터 시스템(multiple-computer system)이 이 분류에 속한다. 이 조직에서는 n개의 프로세서들이 서로 다른 명령어와 데이터를 처리한다. MIMD 시스템은 프로세서들간의 상호작용 정도에 따라 두 가지로 나뉘는데, 그 정도가 높은 구조를 밀결합 시스템(tightly-coupled system)이라 하고, 그 정도가 낮은 구조를 소결합 시스템(loosely-coupled system)이라고 한다. 밀결합 시스템의 전형적인 구조는 기억장치가 모든 프로세서들에 의하여 공통으로 사용되는 공유 기억장치(shared-memory architecture) 구조이다. 소결합 시스템은 각 프로세서들이 자신의 지역 기억장치(local memory)를 가진, 독립적인 컴퓨터 모듈로 구성되고, 프로세서들간의 통신은 메시지 패싱(message-passing) 방식에 의해 이루어지는 구조를 가지고 있다.
병렬 프로그래밍을 배울 때, 혹은 멀티코어 CPU에 대한 자료를 봤을 때 봤던 내용들이 많이 있을 것이다. 병렬컴퓨터는 프로그램 코드와 데이터를 병렬로 처리하는 시스템이므로, Flynn의 컴퓨터 분류들 중에서 SIMD와 MIMD 조직이 그에 해당하는 조직이다.
그리고 최근에는 SISD 조직에 해당하는 단일프로세서 시스템도 프로세서 내부에 파이프라이닝과 슈퍼스칼라 구조를 이용하기 때문에 병렬처리를 구현하는 시스템으로 볼 수 있다. 이러한 SISD 구조의 프로세서들을 다이에 여렷 구성하고 내부에서 병렬로 제어 가능하도록 연결함으로써 병렬처리만을 위한 프로세서를 연구하기도 한다.