break문은 반복 제어문인 for. while, do-while, 그리고 switch의 중첩에서 쓰이는데, 반복작업을 하는 중괄호에서 벗어나도록 하는 데 이용된다. 그리고 중첩된 반복문 내에 있을 경우에는 가장 가까운 반복문을 벗어나는 데 이용된다. 문장을 적절하게 벗어나는 것 또한 중요한 것이기 때문에 사용하는 것을 잘 확인해야 한다.
예시 프로그램으로 살펴보자. 키보드로부터 문자를 입력받아 출력하는데. \n을 입력받으면 break문에 의해 while문을 빠져나가는 것을 볼 수 있다.
while문과 for문은 시작 부분에서 종료 조건을 검사한다. 그에 반해 do-while문은 문장을 우선 실행하고 반복문 마지막에 종료 조건을 검사한다. 그래서 적어도 한 번의 문장 실행을 하도록 한다. 이 문장도 구조를 보여주도록 하겠다.
do
{
문장;
} while (조건식);
구조를 작성한 이유는 do-while문에서는 조금 조심해야 하는 부분이 있다. 우선 저 시작점에 do를 잘못 보고 혼돈할 수 있다. 소스코드가 길어지고 좀 많아지면 그렇게 되는데, do-while의 범위를 제대로 확인하기 위해서 중괄호를 쳐 주는 것이 좀 더 낫다. 그리고 while 뒤에 조건식을 적고 나서 반드시 세미콜론을 적어줘야 한다.
for문은 주어진 조건식이 참인 동안에는 특정 부분의 명령을 반복 수행하는 제어문이다. 이건 좀 구조식을 보는 쪽이 좋다. for문의 구조식은 일단 다음과 같다.
for (초기식 ; 조건식 ; 변환식) {
문장;
문장;
}
for문을 만나면 일단 초기식이 먼저 처리된다. 그리고 나서 조건식이 참인지 거짓인지를 확인하여 참이면 문장을 실행하고 변환식을 계산하고 다시 조건식을 평가한다. 반면에 거짓이면 문장을 실행하지 않고 for문이 종료된다. 문장으로 또 다른 for문이 될 수도 있는데 이를 중첩된 반복문이라고 한다. (물론 while도 할 수 있다.) 그리고 수식을 생략해도 되는데, 수식을 생략할 경우에는 무한반복을 의미한다. 그러나 세미콜론 만큼은 생략할 수 없다.
프로그램을 짤 때, 동일한 작업을 반복하게 되는 경우가 발생한다. 예를 들어, 1부터 1000까지의 합을 계산하고자 할 때, 먼저 다음과 같이 1을 0으로 초기화된 sum이라는 변수에 더해서 sum에 저장한다.
sum = sum + 1;
2를 다시 sum에 더해서 저장하고, 이러한 동작을 1000 까지 진행을 하면 1부터 1000까지 더하게 된다.
sum = sum + 2;
…….
sum = sum + 1000;
이 문장을 보면, 특정한 규칙을 가지고 반복된다는 것을 볼 수 있다. 이와 같이 동일한 부분이 반복적으로 실행되어야 하는 경우에 효율적인 제어를 하는 제어문을 반복문이라고 하며, while, for, d0-while 문이 있다. 이들에 대해서 하나 하나 살펴보도록 하는데, while을 먼저 살펴본다.
while문은 주어진 조건이 참인 동안에 반복문 내의 명령문을 실행하고 그렇지 않으면 반복문 다음에 나오는 명령문을 실행한다. 즉, 조건식이 참이면 그 문장을 실행하고 다시 while문의 시작 부분으로 가서 조건을 평가한다. 그리고 조건이 참이면 다시 문장을 실행하고 다시 조건을 평가한다. 이 작업을 거짓이 될 때까지 반복한다.
while문을 이용한 프로그램의 예시를 아래와 같이 작성하였다. 입력된 문자 ch가 A보다 크거나 같으면 문자열을 계속 출력한다. 초기에 Z가 입력되어 있는데, 이 Z를 출력하고 ch를 Y로 변경한다. 그리고 나서 다시 조건을 체크하여 참이 되었으니 Y를 출력하고 X가 값으로 되는 것이다. 그렇게 하여 A까지 출력한다.
그리고 while을 무한히 반복하게 할 수 있는데 조건식에 1(혹은 true)을 작성하면 된다. 그리고 이를 빠져나오기 위해서는 break 문을 이용하면 된다.
앞에서 살펴본 if문의 경우에는 참과 거짓, 단 둘의 경우에 대해서만 처리를 하는 데 적합한 반면, switch문의 경우에는 다양한 조건을 처리하는 데 적합하다. 해당 수식의 값에 따라 여러 방향으로 분기하기 위한 분기문이다. 구조를 한번에 보기 쉽도록 구성된 예시를 보면서 문법의 설명을 진행하겠다.
숫자 1,2,3을 넣으면 해당되는 문장이 출력되고, 그 외에 것들이 들어오면 hello others가 출력되는 프로그램이다. 입력된 숫자 i가 수식이고, i의 조건이 1,2,3인지를 확인하는 것이 바로 case 문이다. case의 상수식 조건에 일치되면 그 문장을 실행을 하게 된다.
그리고 그 외에 어디에도 해당되지 않는 경우에는 default에 있는 값이 실행된다. default의 경우에는 실제로 작성하지 않아도 된다. 즉, 생략이 가능하다.
근데 이 프로그램의 경우, 실행을 하게 되면 아래와 같이 실행이 된다.
정상이다. 일치하는 상수식에 포함된 문장만 실행되지 않고 아래 쪽 모든 문장을 실행하게 된 것이다. 이를 해결하기 위해서는 해당 실행 문장이 실행이 끝났다는 것을 표현해주는 break문을 작성해 줘야 한다. break문을 작성하여 수정한 예시와 그 결과는 아래와 같다.
이제는 해당되는 상수식을 실행한 다음에 switch문을 빠져나온 것을 볼 수 있다. 여러 문장을 실행하기 위해서는 그냥 case문 아래에 여러 문장을 작성하고 마지막에 break만 있으면 된다.
if문은 제어문이다. 제어문이란 프로그램의 실행 순서를 변경하는 문장으로 여러 문들이 있는데, 그 중에서도 if문을 확인해 보도록 하겠다.
if문은 조건에 따라 프로그램 프름이 변경되기 때문에 분기문이라고 하며, 조건식이 참이면 문장을 실행하고, 거짓이면 실행하지 않는다. 예제 프로그램을 작성하였는데, 소문자이면 대문자로 변환하여 출력하는 프로그램이다.
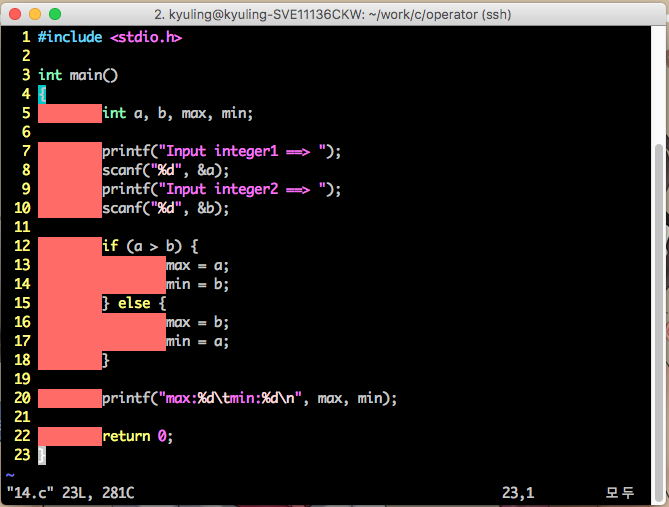
위에 예제에서는 조건식이 참일 경우에 실행하는 문장은 하나다. 그러나 많은 프로그램들은 여러 문장을 실행하는데, 이를 때에는 중괄호를 이용하려 처리한다. 해당 조건이 성립하면 그 다음에 나오는 중괄호의 내용들을 실행하는 것이다. 아래의 예시는 두 개의 정수를 비교하여 큰값과 작은값을 판별하는 것이다. max와 min 값을 설정해야 하기 때문에 여러 문장으로 처리되고, 그걸 위해 중괄호를 이용하였다.
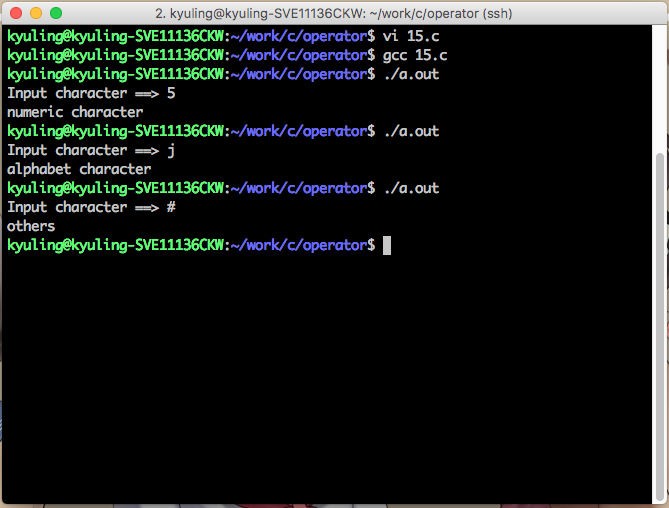
마지막으로 해당 값이 참일 경우와 거짓일 경우에 대해서 처리하는 것이다. if문 옆에 조건식이 참일 경우에는 그 다음의 것을, 거짓일 경우에는 else라고 하여 별도의 문장 뒤에 실행한다. 이 묶음을 if~else 문이라고 한다. 또한 거짓으로 나온 경우에 별도의 조건을 처리하고 싶으면 else if라고 하여 다른 조건을 처리할 수 있다. else if를 여럿 쓰면 여러 조건에 대해 비교를 할 수 있다. 그것을 다 보여주는 것이 바로 아래의 예시인데, 문자를 입력받은 것이 숫자인지 문자인지 아니면 다른 것인지를 판별하는 프로그램 예시이다. 조건이 문자인지를 비교하는 것과 숫자인지를 비교하는 것 두 조건이 존재한다.
가장 기본적인 조건문인 if문에 대해서 알아봤다. 조건문을 사용하기 시작하면 이제 슬슬 프로그램이 더 큰 프로그램을 잓헝할 수 있게 되는 것이다. ㅇㅂㅇ
난 솔직히 자바를 많이 쓰는 녀석이 아니다. 내 스스로 처음 프로젝트를 시작한다 해도 자바를 선택하지는 않는 편이다. 그런데, 자바를 써야 할 때에는 쓴다. 쓰지 못하는 게 아니라 쓰지 않는 것이다. 그래서 남들은 다 알아도 나는 모르는 것도 많다. 지금 글을 쓰는 이 제목의 정체도 마찬가지이다.
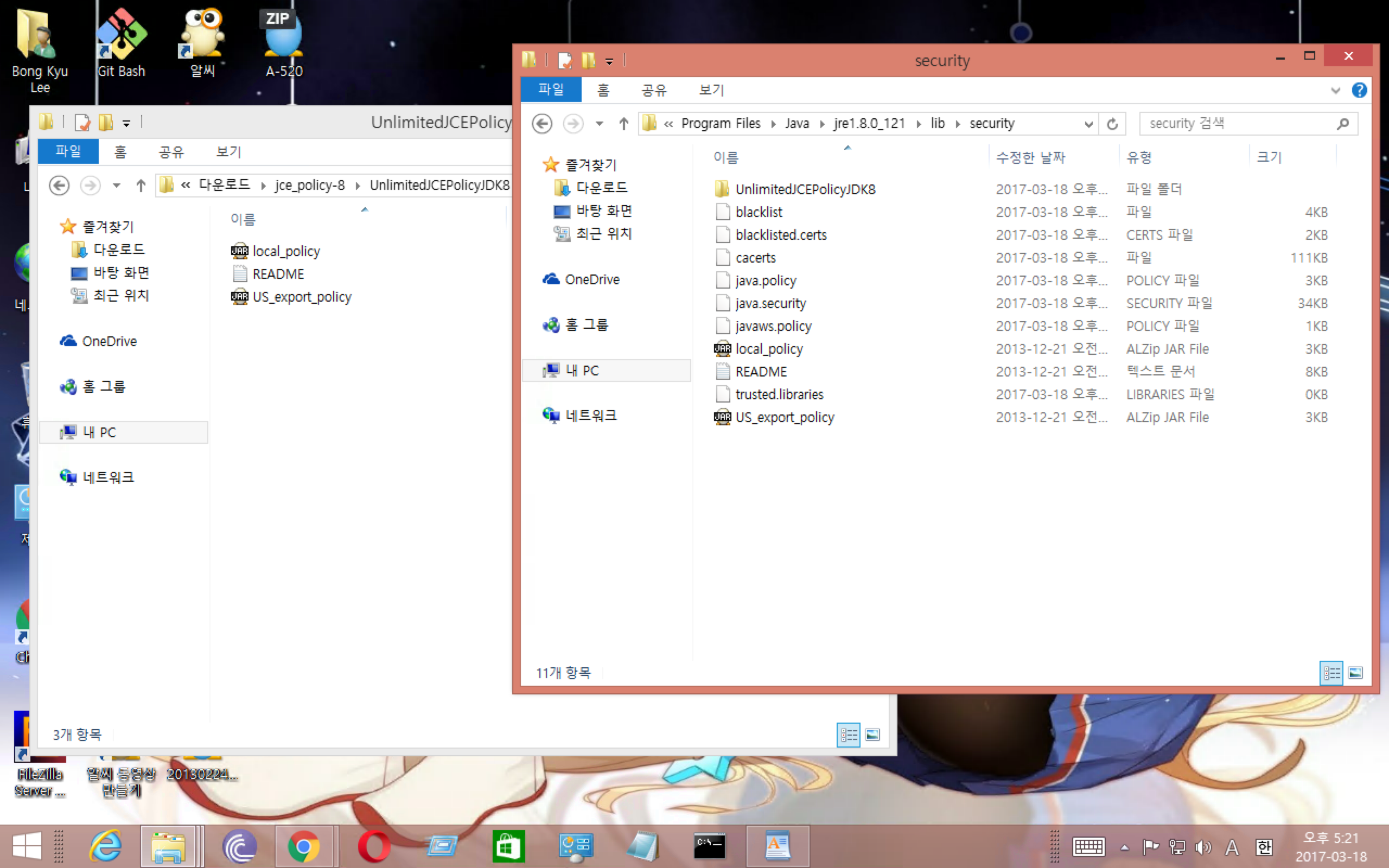
암호화를 위해서는 상당히 많은 수준의 바이트 연산을 처리해야 한다. 이건 뭐, 요즘 나오는 암호화 기법을 사용하던, 기존의 기법에서 변경된 암호화던 간에 기본적으로 처리하는 연산량이 크다. 그러나 Java SE의 경우에는 강한(strong) 암호화 기법을 이용하여 개발은 할 수 있는데, 이 길이에 제약이 있다. 이걸 “limited strength”라고 문서에 표현되어 있다. 이걸 “unlimited strength”화 하여 암호화 기법을 더욱 강력하게 해주는 것이 바로 지금 작성하는 JCE 정책 파일이다.
이런 게 왜 있냐고 묻는 사람들이 있을 것이다. 나도 좀 궁금해서 좀 찾아봤다. 그러고 보니 여러 내용들이 나오는데, 어느 정도 조합을 하니 내용이 이해가 좀 되었다.
암호화의 강도 구성에 대해서는 어느 정도 국가간의 제약이 있다는 것이다. 암호화 기술의 수출 제약이라는 것인데, 이 내용에 대해서는 일반 사람들이 들어봤을 법한 내용으로는 공인인증서 역사에 나와있는 국내에서 개발했다는 암호화 알고리즘 이야기를 들을 수 있을 거 같다. 뭐, 이런 국가간의 암호화 기술간의 수출 제약이 있기 때문에, 기본적으로 배포되는 JDK, JRE에는 어느 정도 제약이 있는 암호화 기술을 내장하여 배포를 한다는 것이다. 자바의 배포는 글로벌하게 배포되기 때문에 어느 정도의 제약이 있게 만들었다는 것이다. 이 부분을 없애기 위해서 자바를 배포하는 쪽에서는 암호화 강도에 대한 제약을 없앤 별도의 번들을 제공한다는 것이다. 이것 또한 대부분의 국가에 적합한 암호화 정책이 적용되어 있다는 것이다.
이 정보를 보면서 알게 된 사실은, 프레임워크를 제작하여 배포하는 업체는 해당 국가의 정부에서 제한되는 것을 요구한다면 해당된 제한에 맞춰진 프레임워크를 제작하고 그리고 그에 대한 제약을 해제한 별도의 번들을 배포할 수 있는 것이 있다는 사실이다. 그리고 사용자는 해당되는 번들을 사용하더라도 법률에 정해진 어느 정도의 제약된 번들 안에서 강한 구성의 암호화를 할 수 있다는 것이다.
똑같은 파일이라 그냥 덮어쓰면 된다. 기존에 쓰던 것이 맘에 걸리면 이미 jre에 설치되어 있던 동일 파일을 백업한 다음에 덮어쓰면 된다.
이 다음에 인증서 관련된 작업을 하면 확실히 다른 작업을 할 수 있다.
이런 것이 왜 필요할까 싶은 사람들이 있겠지만 인증서 관련 작업을 하다 보면 “jce unlimited strength jurisdiction policy” 관련된 오류가 발견될 수 있다. 이때 필요한 것이 바로 이것이다. 이 환경에 맞춰서 개발이 되었기 때문에 그에 맞춰서 작업을 해줘야 한다. 개발할 때 jce 관련된 것들을 import 해서 작업한 것인지 아니면 ca 관련 작업에 기본적으로 필요한 것이라 jre에서 자동으로 찾아주는지 그런 자세한 부분은 내가 인증서쪽 개발을 안해봐서 자세한 건 모르겠다. 이 글도 나도 필요하다보니 오픈소스로 된 인증 모듈을 갖다 쓰는데 이런 오류가 나서 알아보고 작성한 것이다.
뭐, 이런 것이 있다는 걸 알아두는 것도 좋은 같아서 정리해서 작성했는데… 혹시 이 파일에 대해서 좀 더 자세히 아시는 분 있으면 덧글로 남겨주세요. 승인해서 같이 보고 정보를 나눠보죠. ㅇㅂㅇ
int형 데이터와 float형 데이터에 대한 연산, 즉 서로 다른 데이터형에 대한 연산은 이루어지지 않는다. 내부에서의 표현하는 방식이 전혀 다르기 때문이다. 그러나, 언어에서는 서로 다른 데이터형일 때, 작은 크기의 데이터형을 큰 데이터형으로 변호나해 연산을 할 수 있게 해준다. C언어도 해당된다.
음… 예시 코드에도 사용했던 것인데, 예시를 살펴본다.
char형은 1바이트이고, int형은 4바이트로 표현된다.
char | 01100001
int | 00000000000000000000000100000000
이 둘을 연산하기 위해서는 이 둘의 크기가 같아야 연산을 할 수 있는데, int형의 사이즈를 줄이면 데이터가 잘릴 수 있기 때문에 char형을 늘려야 한다. 데이터 형을 늘릴 때에는 앞자리를 전부 0으로 채운다.
char | 00000000000000000000000001100001
int | 00000000000000000000000100000000
이렇게 하여 둘을 연산한 결과는 int형태로 되어 연산이 된다. 실행 결과는 아래와 같다.
이런 연산 시 데이터형 자동변환에는 규칙이 있다. 규칙에 대해서는 다음과 같다.
long double형이 있으면, 다른 피연산자를 long double형으로 변환하다.
그렇지 않고 double형이 있으면, 다른 피연산자를 double형으로 변환한다.
그렇지 않고 float형이 있으면, 다른 피연산자를 float형으로 변환한다.
그렇지 않고 (unsigned) long형이 있으면, 다른 피연산자를(unsigned) long형으로 변환한다.
그렇지 않고(unsigned) int형이 있으면, 다른 피연산자를(unsigned) int형으로 변환한다.
그렇지 않으면 char형 또는 short형을 int 형으로 변환한다.
이게 왜 이렇게 되는지는 컴퓨터 구조에서 숫자 연산 과정을 살펴보면서 이 규칙을 보면 잘 이해가 될 것이다. (이래서 기본 이론이 진짜 중요하다.)
그리고 C언어에서는 사용자가 임의로 현 변환을 할 수 있다. (다른 언어도 마찬가지) 이 때 사용하는 연산자가 캐스트 연산자이다. 변환하려는 변수 앞에 괄호를 처리하여 바꾸려는 형을 작성해준다. 아래의 예시를 보면, 10.7과 30.8같은 소수점 연산자를 int형으로 변환하였다.
특정 변수를 선언할 때, 해당되는 사용 값 만큼의 메모리를 선언한다. 그러나 임의의 데이터형의 크기만큼 메모리를 할당받을 수도 있는데, 이를 동적 할당이라고 한다. (이 부분에 대해서는 나중에 자세히 확인하도록 하겠다.) 이러한 경우에는 해당 변수가 얼마나 사이즈를 잡고 있는지 모르는 경우가 많다. 그래서 사이즈를 확인하기 위해 sizeof라는 연산자를 사용한다. 출력되는 변수의 크기는 바이트 수이다.
사용법은 다음과 같다.
sizeof(int) – int형의 크기
sizeof(num) – num 변수의 크기
실제로 프로그래밍을 하다 보면 이 사이즈를 알아야 하는 경우가 상당히 많다. 그렇기 때문에 자주 쓰일 것이다. 예시대로 꼭 해서 출력해보자.