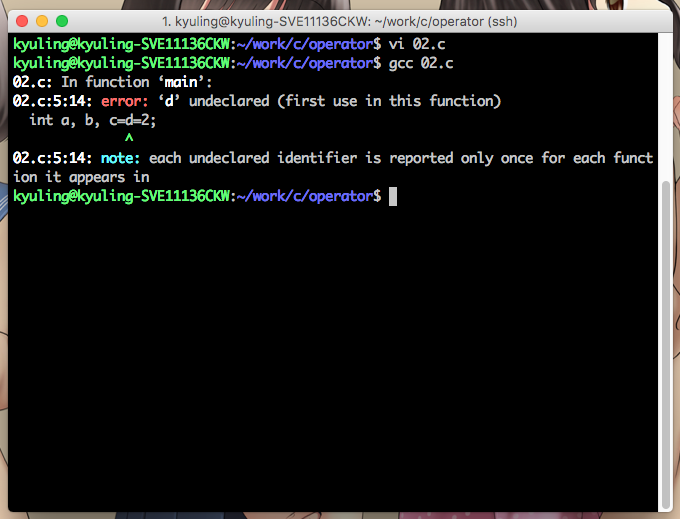
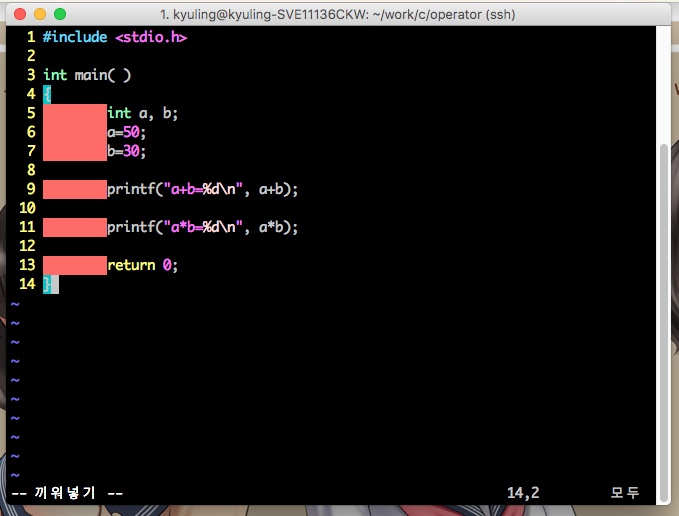
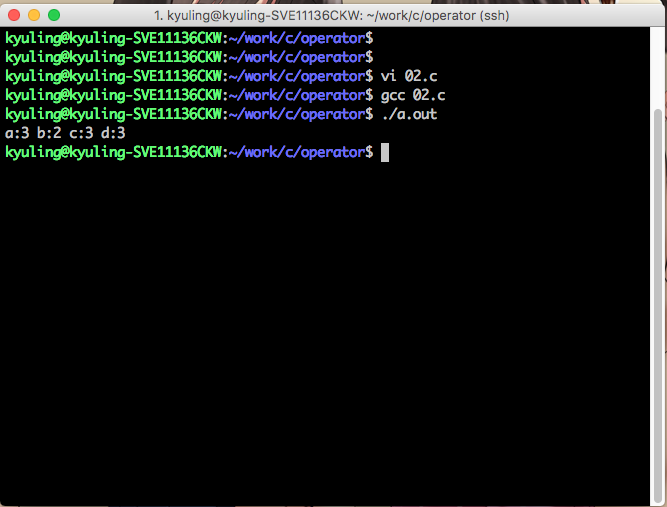
이 글은 글의 내용이 한번에 쭉 이어져서 글이 좀 길다. 그래서 예시 코드와 실행 결과를 슬라이드 쇼로 만들어서 삽입하였으니 읽을 때 양해를 부탁한다.
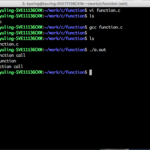
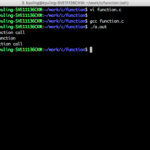
프로그램의 시작은 main이라는 함수에서 시작을 한다고 했다. 그러나, 큰 프로그램을 만드는 데 있어서 main 함수 하나로만 작성하면 작성하기도 어려울 뿐더러 일일이 나열하면 반복적으로 작성해야 하는 것들도 많이 생기는데, 이를 일일이 작성할 수는 없다. 이를 위해 작업을 처리하는 단위인 함수로 나눠서 작성하면 소스코드의 길이가 짧아질 뿐만 아니라 다른 프로그램에서도 사용할 수 있도록 만들 수 있다. 함수를 사용하는 예제를 아래와 같이 확인한다.
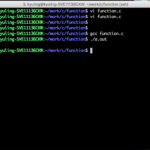
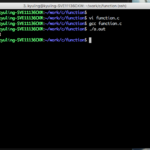
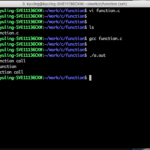
C언어에서는 main 함수 내에 있는 문장을 순차적으로 실행하는데, 예시 소스의 11번째 라인에 있는 func(); 는 func 함수를 실행하시오라는 의미이다. 그래서 func 함수를 실행을 하고, 함수 실행이 다 끝아면 다시 main 함수의 다음 줄인 12번 줄을 실행한다.
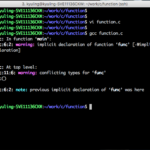
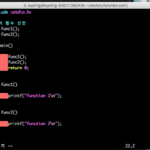
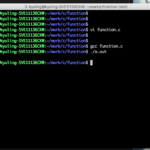
함수 또한 정의를 해야 main 함수에서 알 수 있다. 그래서 main 함수 위에 함수를 작성한 것이 바로 함수를 정의한 것이 된다. 만약 main 함수 밑에 함수를 정의하면 오류를 발생시킬 것이다. 아래의 예시는 직접 오류를 발생시켰다.
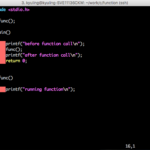
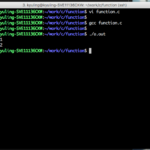
이런 경우에는 함수를 별도의 변수처럼 한 줄로 선언함으로써 해결할 수 있다. 함수 선언은 함수 호출 전에 어떤 함수가 정의되어 있는지 먼저 알려주는 것으로, 일반적으로 프로그램 시작 부분에 나타낸다. 선언이 위에 있으면, 함수를 직접 정의하는 부분이 호출하는 함수보다 아래에 있어도 상관이 없다. 지금 학습하는 데 있어서 호출하는 함수는 main 함수이므로, main 함수보다 아래에 함수를 정의하려면 main 함수 위에 함수 선언을 따로 해줘야 한다.
함수를 정의하는 작업을 그냥 위에 하면 되지 않느냐고 묻는 사람들이 많은데, 함수의 수가 많거나 함수간에 호출의 경우에는 어떤 것을 먼저 정의하고 나중에 정의하느냐에 따라서도 구성을 생각해야 하는 경우가 생긴다. 함수가 함수를 부르는 경우에는 특히 더더욱 심각한 문제가 된다. 그래서 미리 헤더를 삽입하는 곳 아래에 함수들을 미리 선언하고 사용한다. 그러면 별도로 이해력이 떨어지는 코드를 짜지 않아도 된다.
함수를 선언하는 예시는 아래와 같이 구성하면 된다.
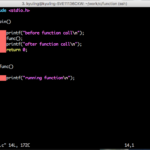
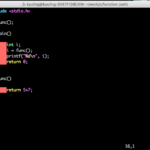
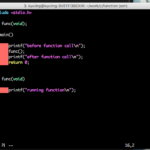
프로그램은 대부분 여러 개의 함수를 사용한다. 그래서 함수를 하나 더 추가해보도록 한다.
지금까지 작성한 함수는 기존의 main 함수와는 다른 걸 볼 수 있다. 그렇다. return을 마지막에 작성해 주지 않았다. 함수를 실행하고 나면 해당되는 반환값이 없는 것이다. 그래서 void형을 앞에 적어줬다. 그리고 함수를 호출할 때, 어떤 값을 전달해 주지도 않았다. 함수는 반환값과 전달하는 매개변수에 따라서 다음과 같이 분류할 수 있다.
반환하는 값과 매개변수가 없는 함수
반환하는 값은 있고 매개변수는 없는 함수
반환하는 값은 없고 배개변수는 있는 함수
반환하는 값과 매개변수가 있는 함수
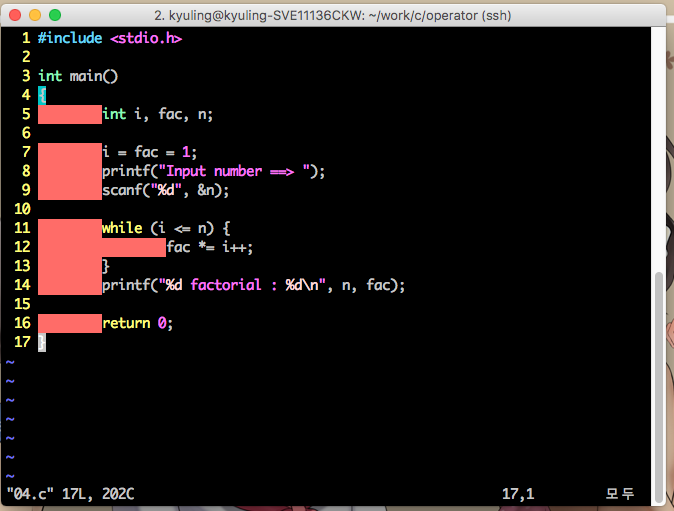
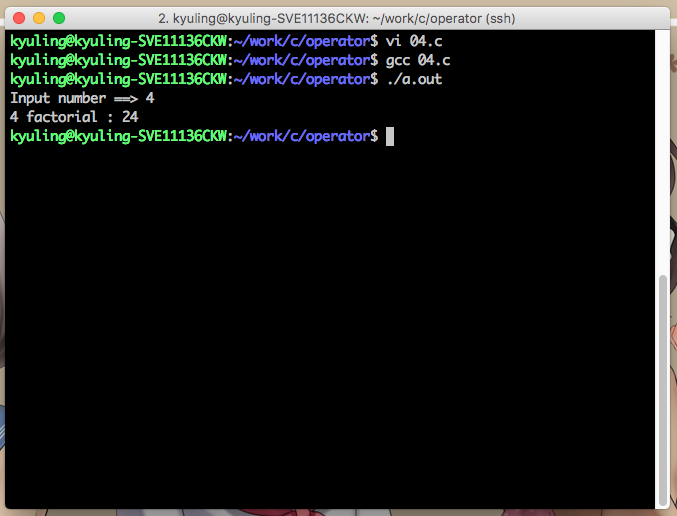
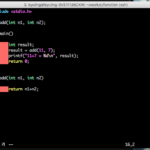
우리가 주로 작성하던 main 함수를 보면 반환값에 대한 것은 쉽게 알 수 있다. 앞에 int 라고 작성한 것은 int형 변수를 반환한다는 것이고, 마지막 줄에 있는 return값은 반환할 값이 이것이란 것이다. 그럼 일단 반환값이 있는 함수는 어떤 형식인지 예시로 확인하겠다. 아래 예시에는 return에 5+7이라고 되어 있는데, 5+7을 한 결과값을 반환하는 것이다. 그래서 반환된 값을 main에 있는 i 변수가 받아서 출력을 하니 12가 나온 것이다.
반환값이 없고 매개변수가 있는 함수는 어떤 구조인지 확인하겠다. 매개변수는 함수의 () 안에 넣으면 받아지며, 함수를 선언하고 정의할 때에도 어떤 타입의 값을 받아올 것인지를 정의해줘야 한다.
위의 예제를 보면 함수 정의하고 선언하는 부분에 보면 func(int n1, int n2) 라고 되어 있는데, () 안에 있는 저 두 변수가 매개변수가 된다. 이런 매개변수를 통해 데이터를 주고받을 수 있는데, 특히 호출하는 쪽의 매개변수를 ‘실매개변수’, 함수를 정의하는 쪽의 매개변수를 ‘형식매개변수’라고 한다. 형식매개변수의 경우에는 어떤 형식이라고만 정의해도 되고 그 변수명에 대해서는 정의를 하지 않아도 되는데, 알아보기 쉽게 하기 위해서 일부러 다 정의하는 경우이다.
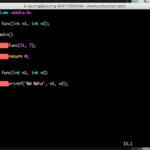
이젠 매개변수 및 반환값이 전부 존재하는 경우를 예시로 보도록 한다.
마지막으로 매개변수를 이용하지 않을 때를 보도록 한다. ()안에 아무것도 정의하지 않아도 되고, void라고 적어도 된다. 그 예제는 아래에 있다.
함수에 대해서 간단하게 알아보았다. 이를 통해 C언어의 기본적인 내용을 살펴봤다. 이젠 연산과 제어를 위한 작업을 정리할 것이다.