앞에 장에서는 긴 내용이긴 하지만 make에 대한 기본적인 것들을 다뤘다. 이 내용에서는 앞의 장의 내용을 한번 실습해 본 상태에서 make에 대한 기타 내용을 추가하여 설명하려고 한다. 이 내용들은 make 파일을 만드는 데 있어서 부가적인 내용들이지만, 소스코드가 많아지고 makefile의 양이 많아지고 할 경우에는 유용하게 쓰이는 내용들이다. 또한 현재 C, C++ 프로젝트 중 규모가 거대한 프로젝트에서는 이 내용들이 많이 이용될 것이니 좀 내용이 길고 힘들더라도 이것까진 제대로 익혀두자.
- 가짜 대상
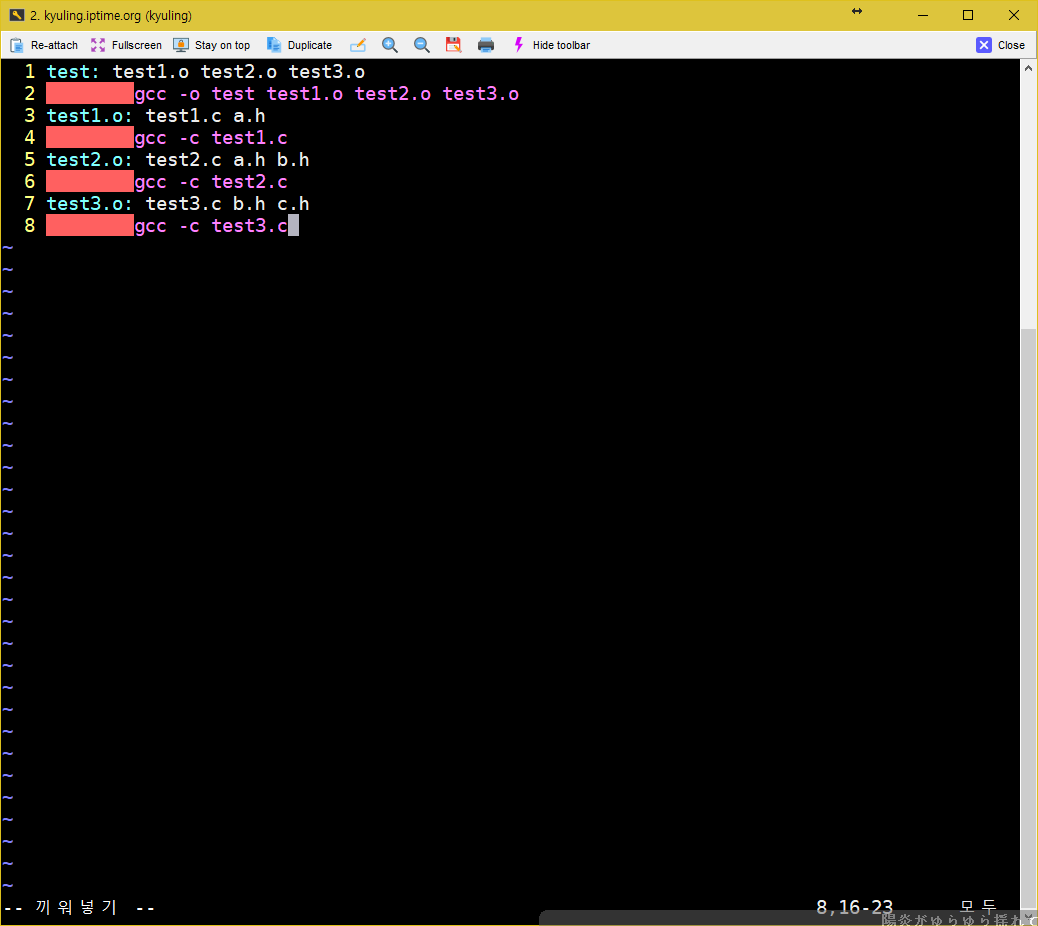
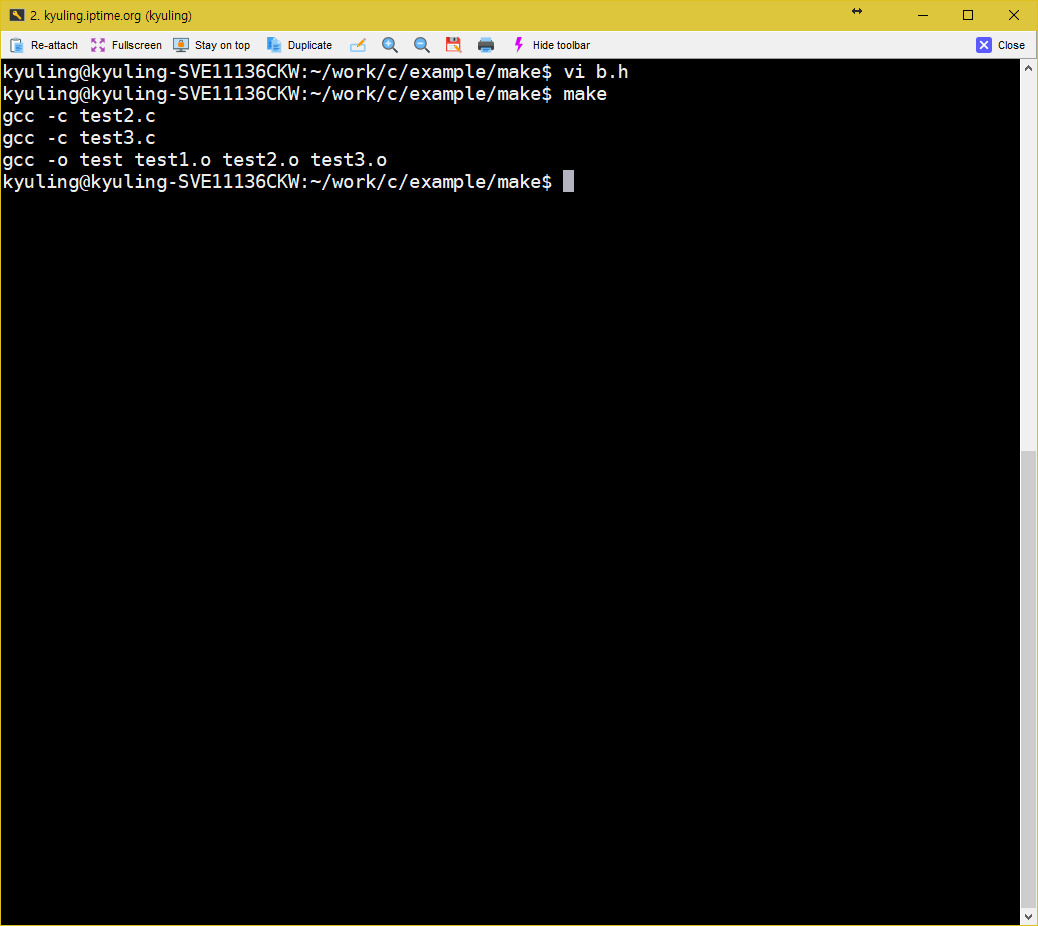
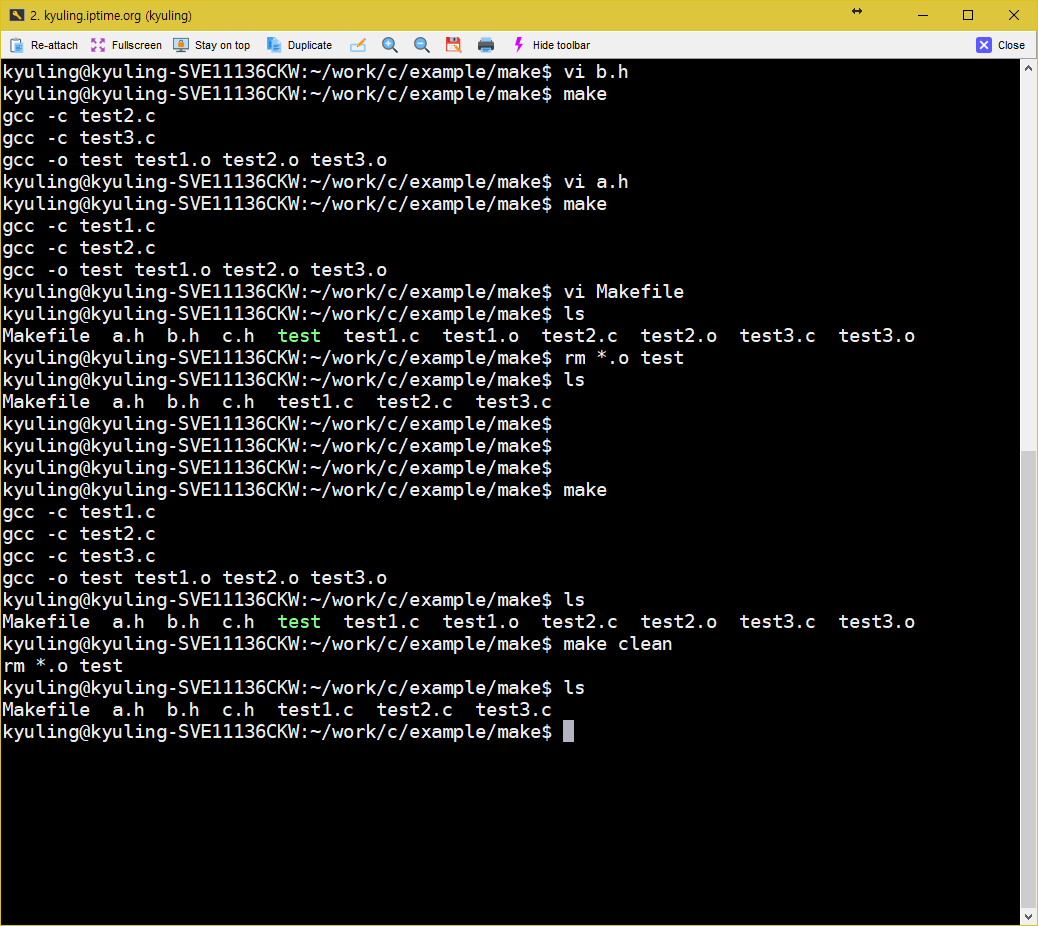
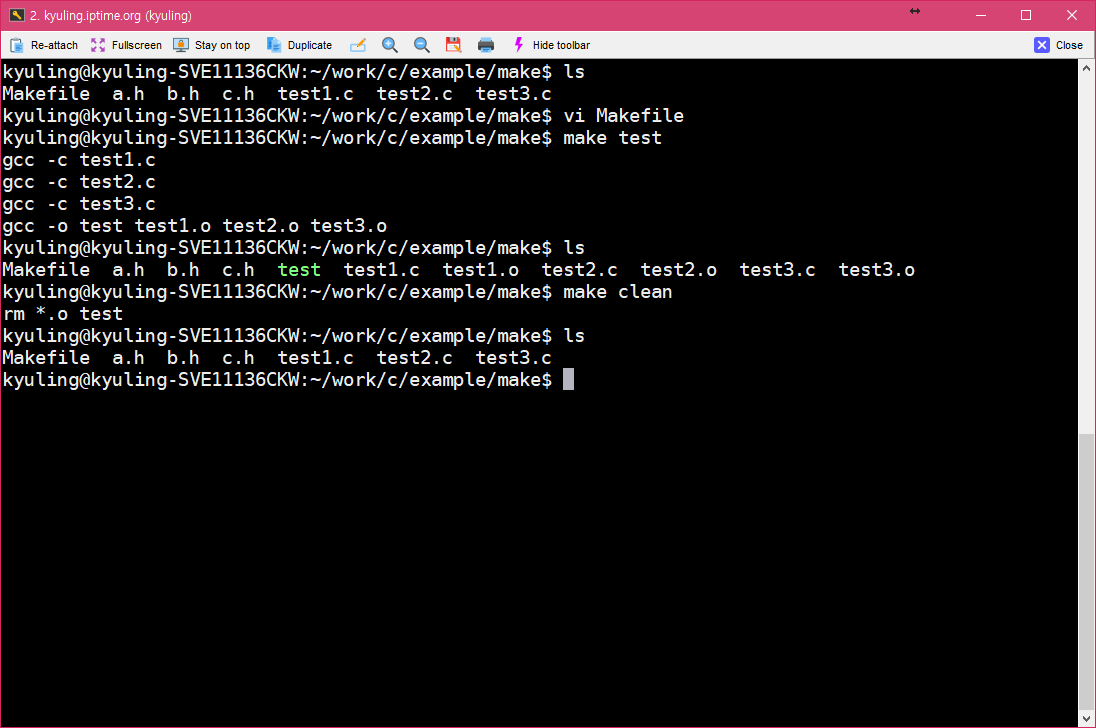
make 파일의 대상에는 실행 파일과 오브젝트 파일 뿐 아니라 사용자가 임의로 정한 레이블 이름이 올 수 있다고 하였다. 이를 구체적으로 살펴보기 위해서 아래와 같은 make 파일을 작성하였다.
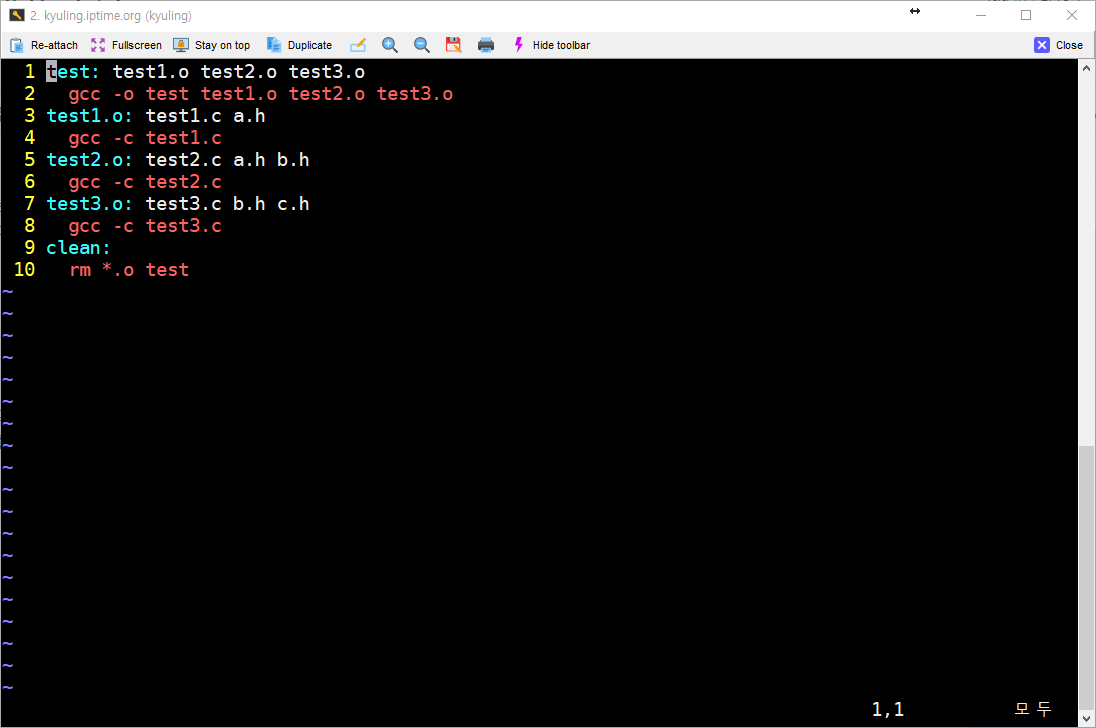

중요한 것은 여기에 있는 바로 clean 레이블이다. clean이라는 대상은 실제 파일에 대응하지 않는 형태의 레이블이다. 이를 두고 가짜 대상이라고 하는데, 이런 가짜 대상은 사용자가 원할 때 make가 특정 명령을 실행하도록 하기 위해 만들어 사용한다.
그리고 clean은 의존성을 갖지 않기 때문에 make는 clean 대상을 만날 때마다 대상이 항상 최신으로 업데이트 된 상태로 간주한다. 이 대상을 구성하려면 다음과 같이 실행해야 하는데, 다음 결과를 보면 알 수 있듯 clean을 대상으로 삼는 명령이 실행된다.
- 주석
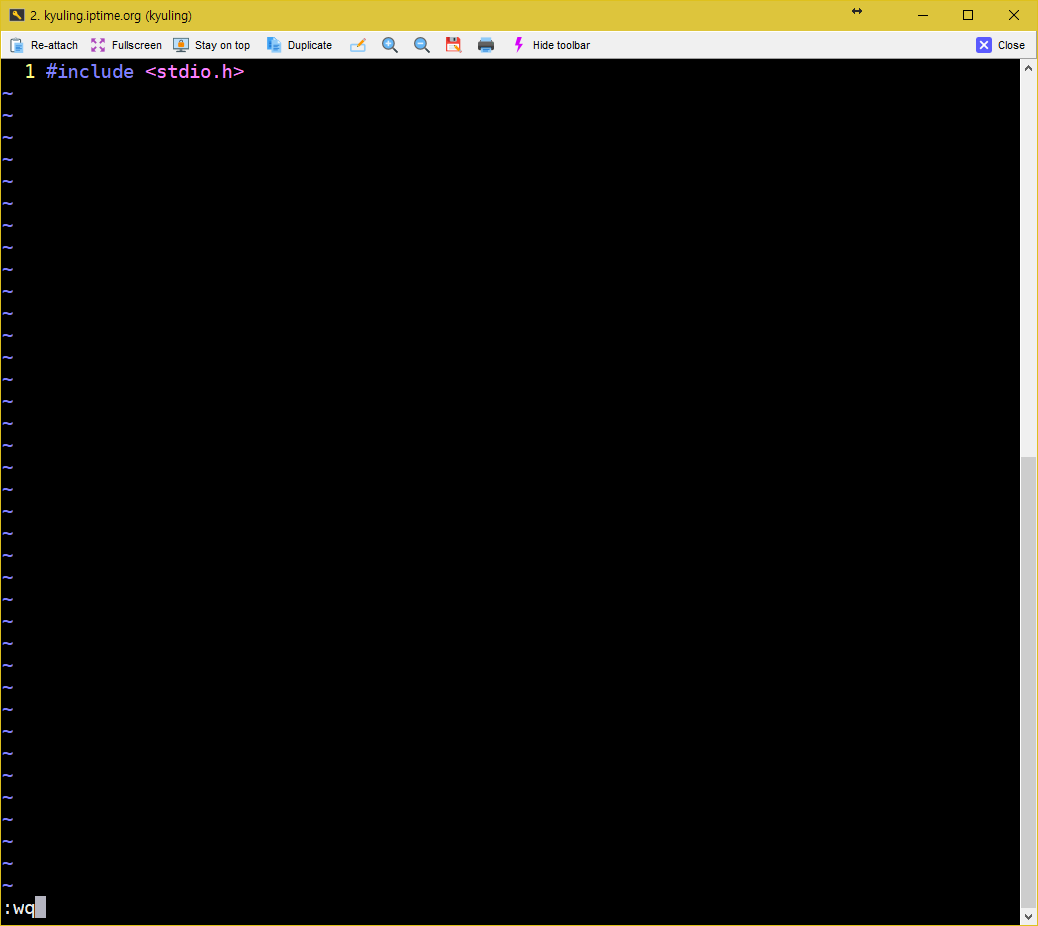
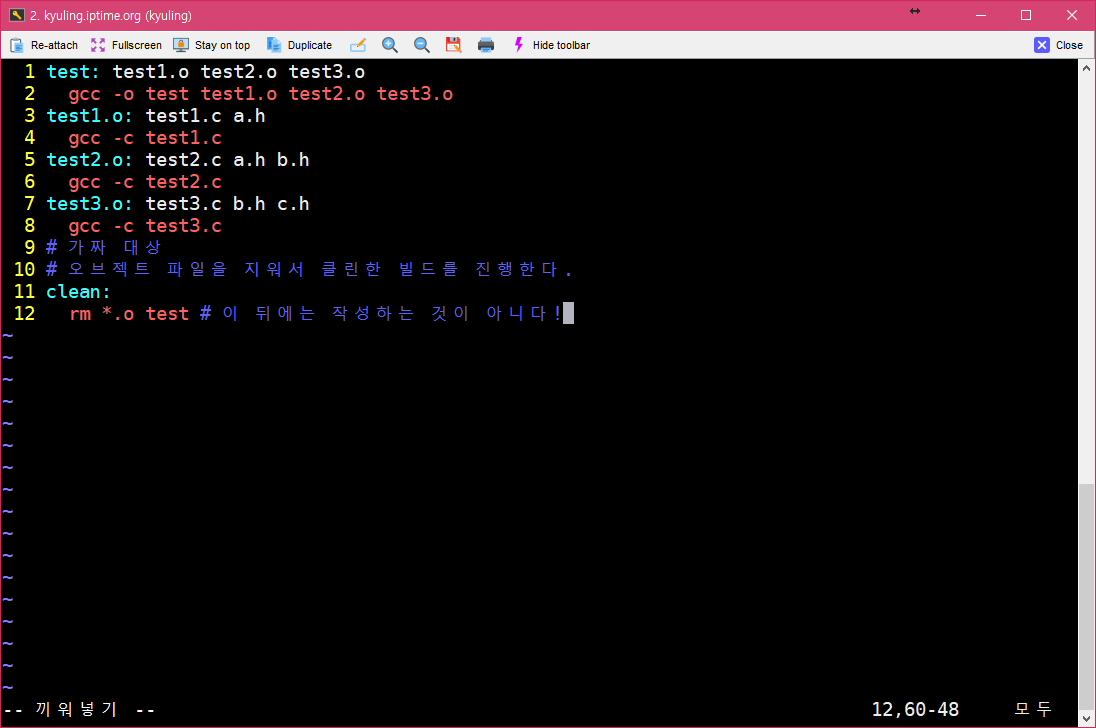
주석은 개발자와 다른 사람이 코드를 이해하는 데 도움이 많이 된다. 필자의 경우에는 주석을 엄청나게 이용하는 편이다. 주석문을 삽입하면 추후에 자신이 작성한 코드를 수정하고자 할 때 훨씬 쉽게 수정할 수도 있고, 다른 사람들이 작성한 코드도 주석문의 내용을 통해 쉽게 이해할 수 있기 때문이다. 그래서 make 파일에도 주석을 이용하여 작성할 수 있는데, #이 앞에 있으면 그 뒤의 문장은 주석이 된다. 단, 프로그램 코드의 주석과 달리 명령 라인 뒤에 주석을 붙이지는 않는다. 셸이 #에 대해서 메타 문자 형태로 인식하여 이것을 변환하려고 시도할 수 있기 때문이다. 리눅스를 쓰는 친구들은 configure 파일에도 보면 주석을 작성하는 데 옵션 뒤에 주석을 쓰는 것을 보지 못했을 것이다. 이와 같은 원리로, 따라서 주석은 코드와 전혀 관계 없는 곳에 작성한다.
- 자동 의존 관계 생성
의존 관계의 경우, gcc에서 자동으로 생성할 수 있는 방법이 있다. gccmakedep 명령어를 이용하면 의존 관계를 자동적으로 생성할 수 있다. 그런데, 이 작업을 거치기 전에, 우분투 사용자들은 다음과 같은 명령어로 패키지를 하나 설치해야 한다.
sudo apt-get install xutils-dev
이 작업은 gcc의 기본 환경인 make에 있는 것이 아니라 imake라고 별도의 패키지에 있는데, 이걸 포함하고 잇는 것이 바로 저것이다. (페도라 계열을 그냥 바로 gccmakedep을 설치하면 알아서 저걸 깔아준다.) 그러지 않으면 오류가 난다.
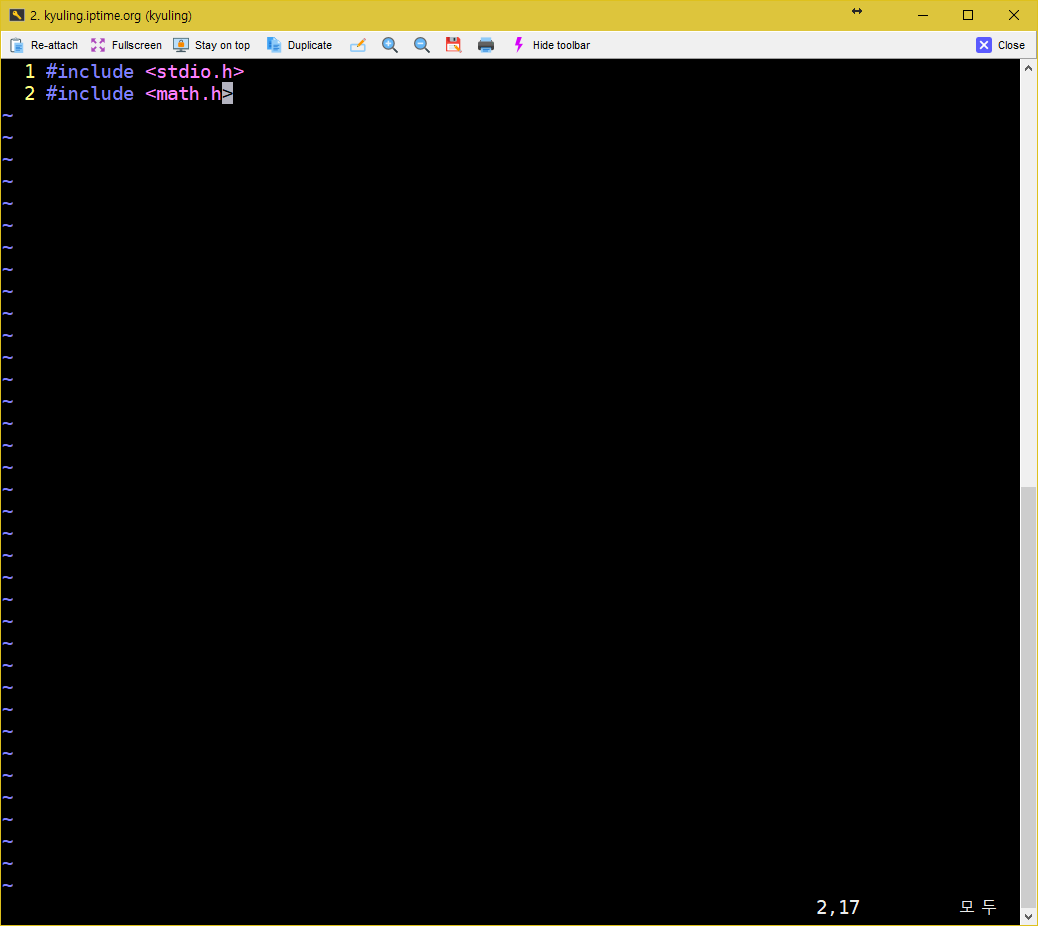
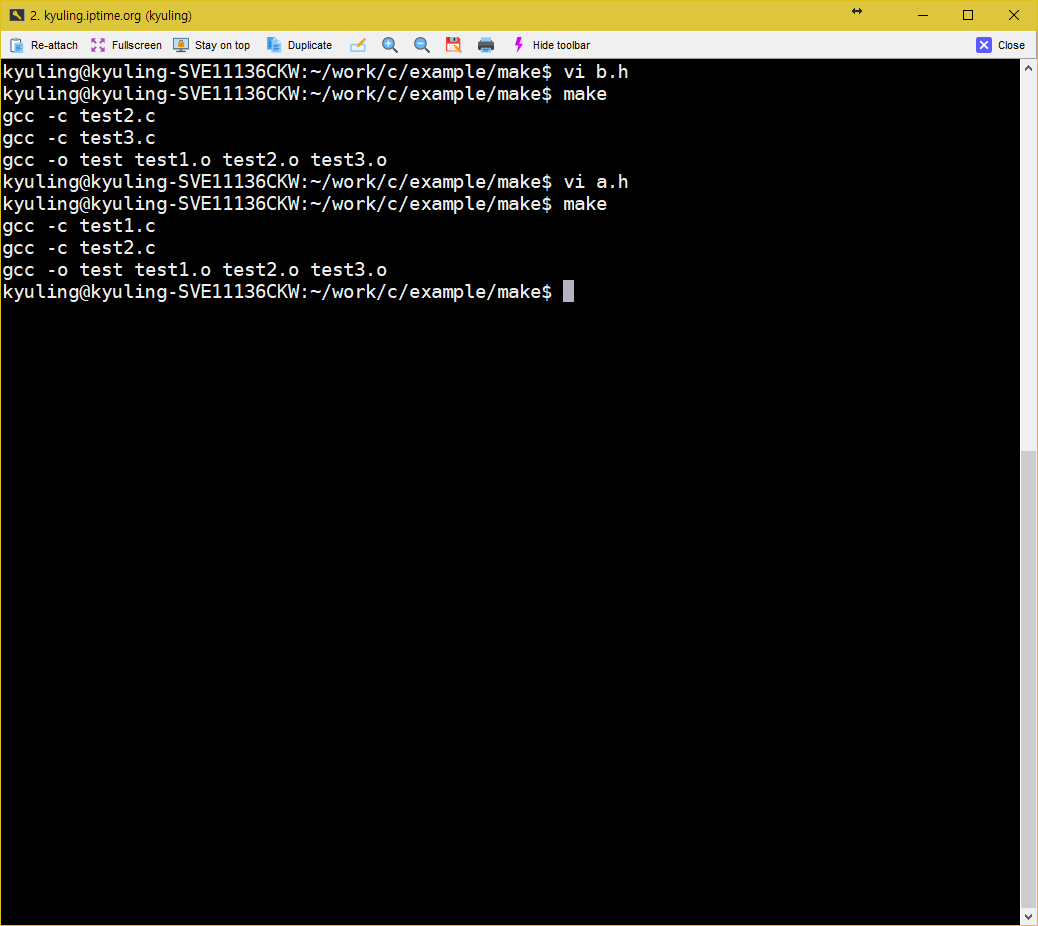
그럼 의존성은 어떻게 자동으로 만들 수 있는지 확인해 보겠다. 우선 전에 이용하던 make 파일을 수정한다.
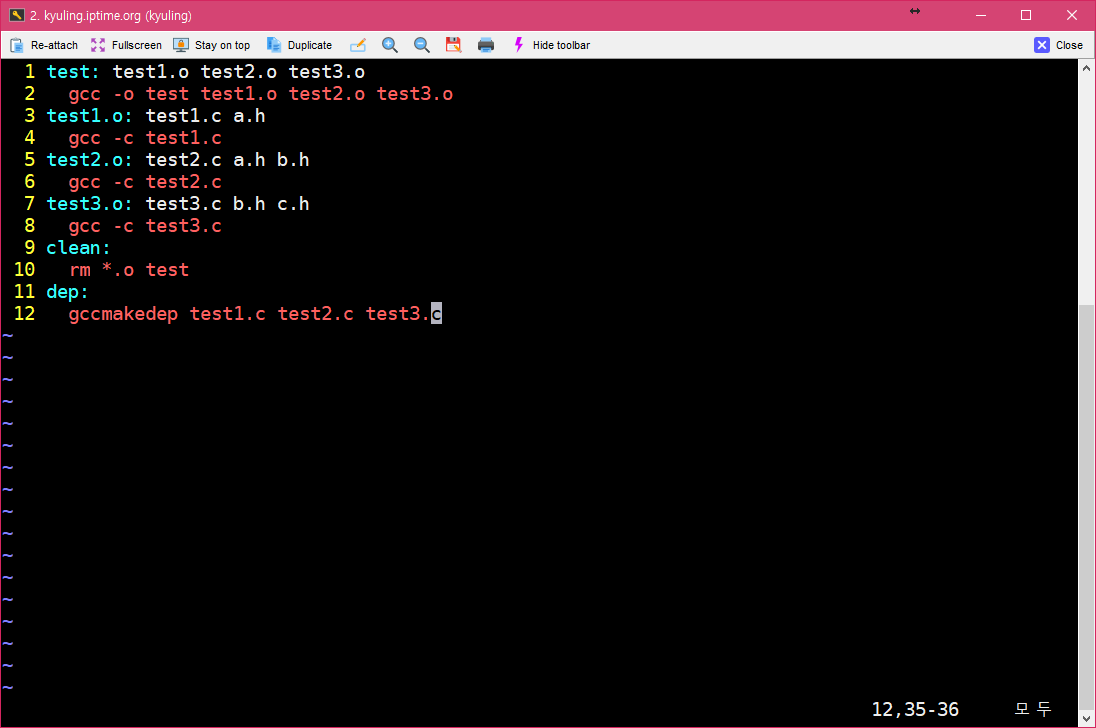
dep이라는 가짜 대상을 만들고, gccmakedep 명령으로 세 코드의 의존성을 생성하도록 하였다. 그리고 저장 후 빌드를 할때, 아래와 같이 나오면 위의 패키지가 설치되어 있지 않은 것이다.
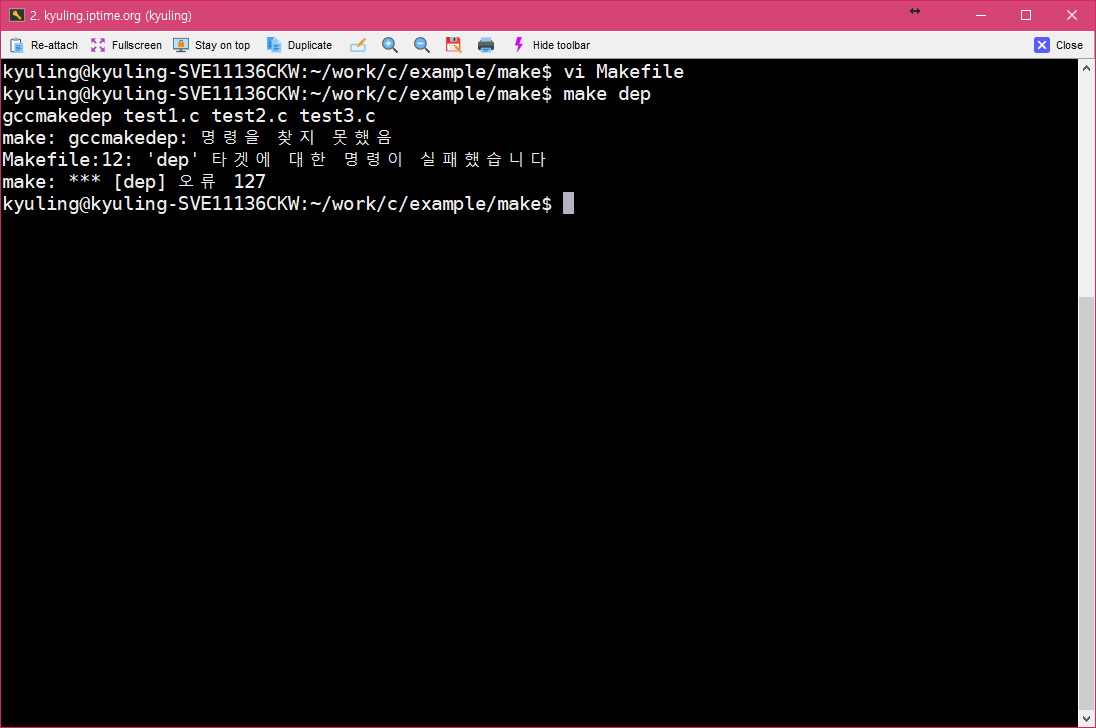
아래와 같이 나와야 정상적으로 끝난 것이다.
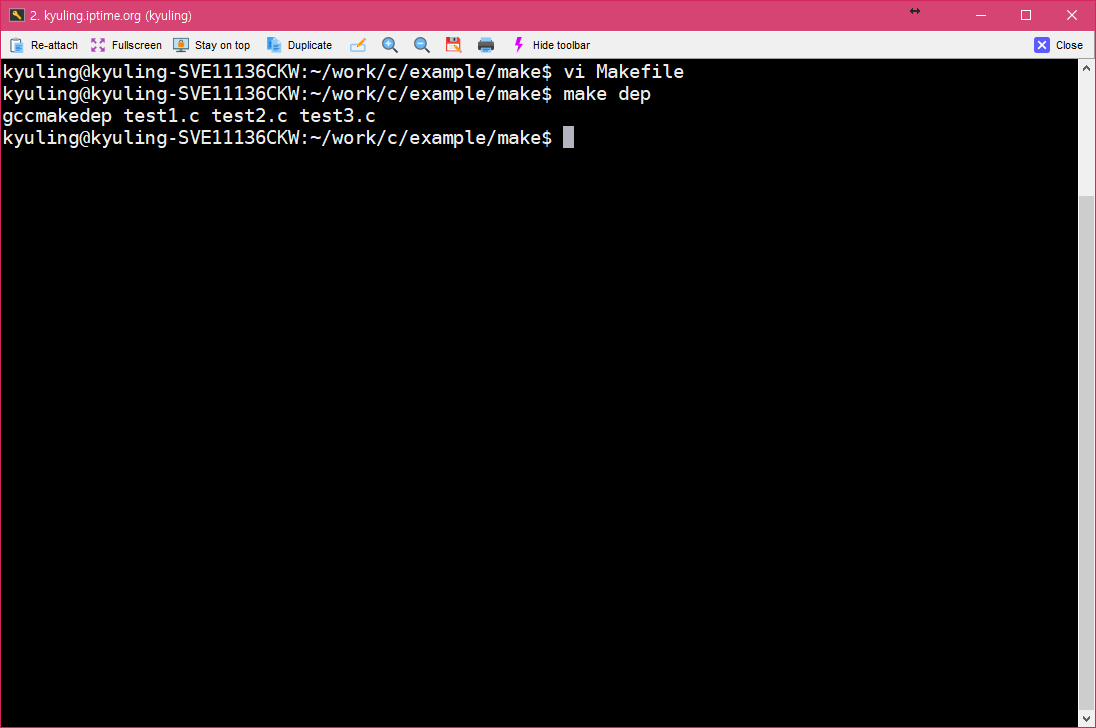
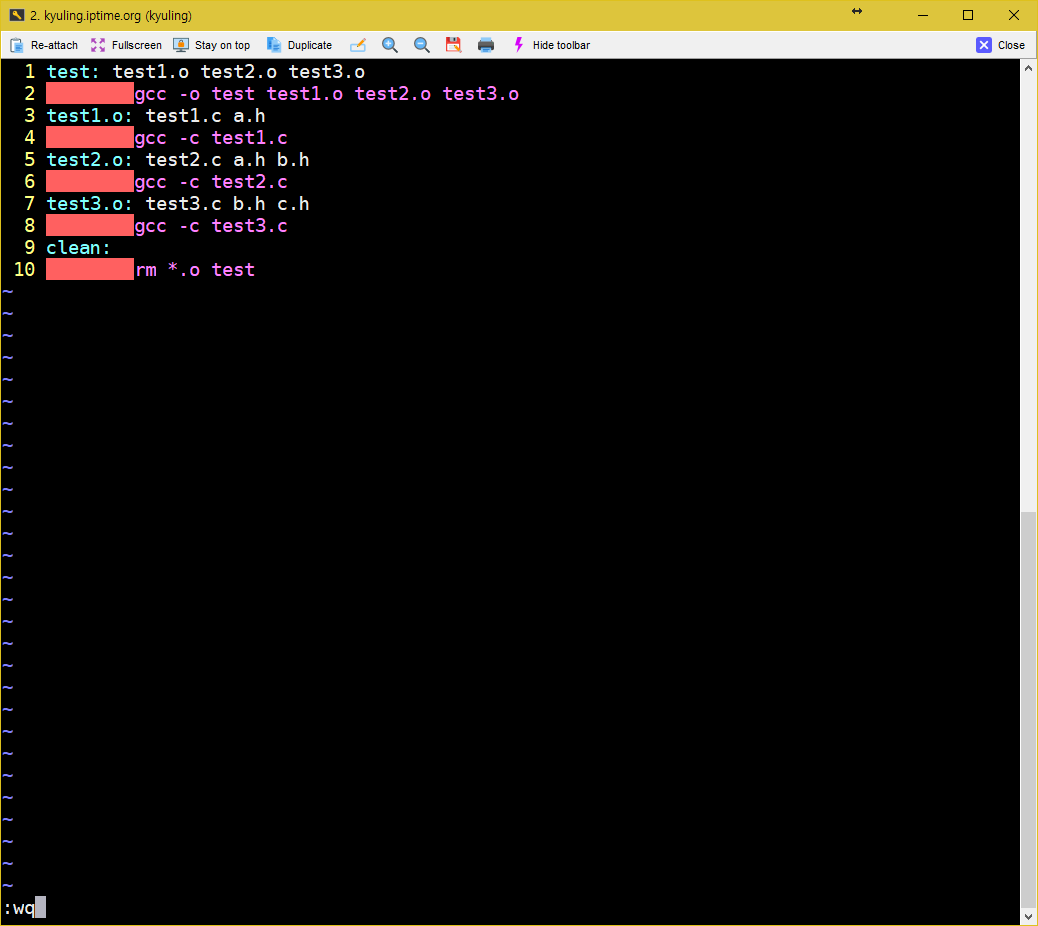
그리고 나서 Makefile을 열어 보면 아래와 같이 작성되어 있는 것을 알 수 있다.
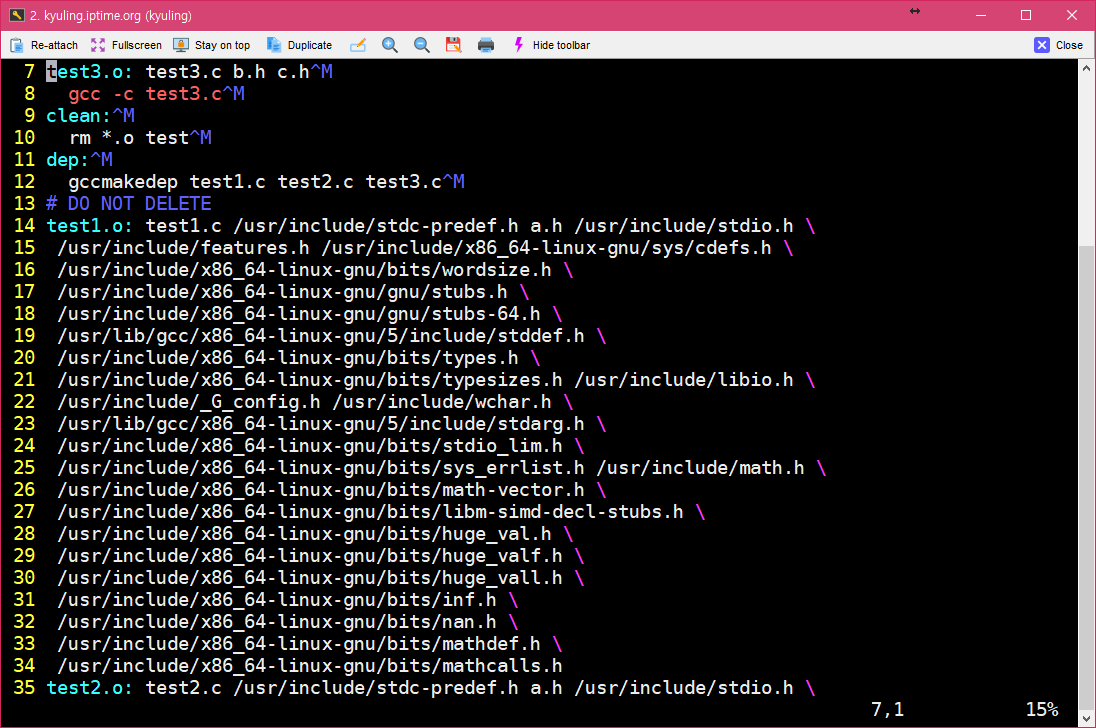
주석으로 DO NOT DELETE라고 적힌 곳부터가 자동으로 생성된 코드이다. 각각 사용자가 작성한 헤더인 a.h 말고도 다른 것들이 더 있는데, 저것들이 a.h 안에 삽입되어 있는 stdio.h와 연관된 의존 헤더들이다. 현재 시스템이 어떤 컴파일러, 어떤 라이브러리가 설치되어 있느냐에 따라서 의존된 결과가 다를 수 있다.
- 긴 명령어 쓰기
바로 위에 그림에 자동으로 생성된 의존 관계를 보면, \로 끝이 끝나는 걸 볼 수 있다. 이것이 바로 명령어가 옆으로 길어져서 다음 라인으로 옮겨 쓰기 위해 이용하는 것이다. \의 뒤에는 아무것도 작성하지 않고 바로 다음 문장으로 넘어간다. 여러 문장으로 하고 싶을 경우에는 끊어야 할 부분에 \를 입력하여 다시 길게 작성한다.
- 여러 개의 셸 명령 사용
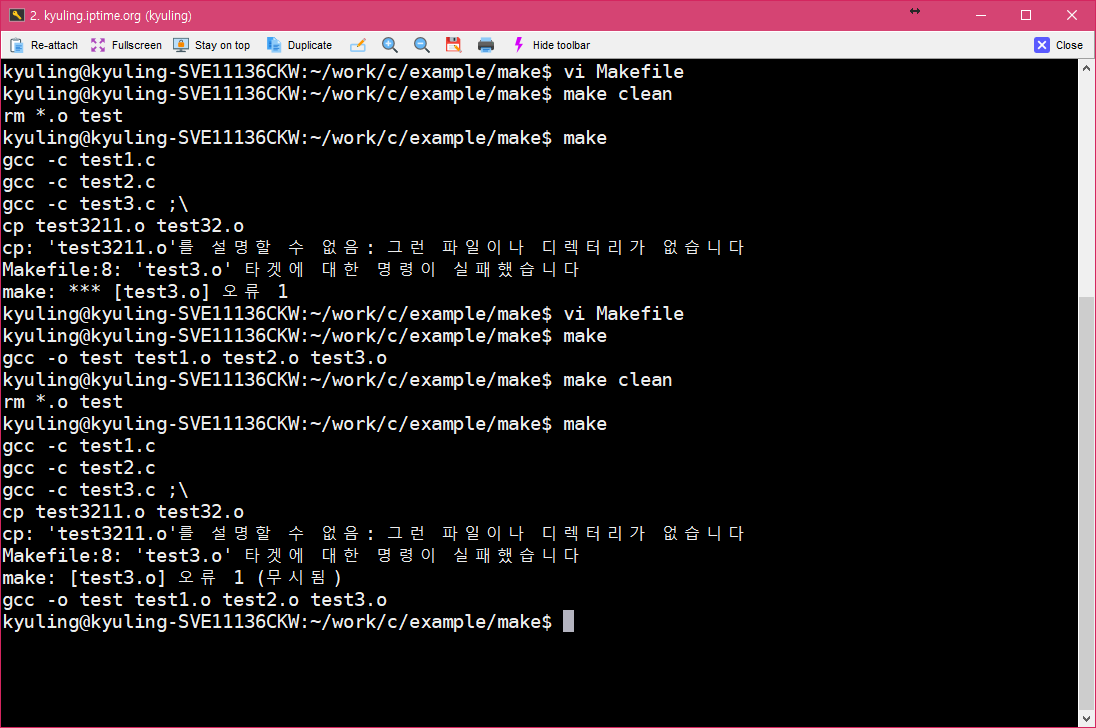
make 파일 내에서는 모든 셸 명령을 사용할 수 있다. 그러나 모든 명령이 다른 셸 안에서 실행되기 때문에 하나 이상의 명령을 사용할 때 문제가 생길 수 있는데, 이를 해결하기 위해서 세미콜론(;)을 이용하여 작성을 한다. 아래와 같이 적으면 오류가 나는 상황인데,
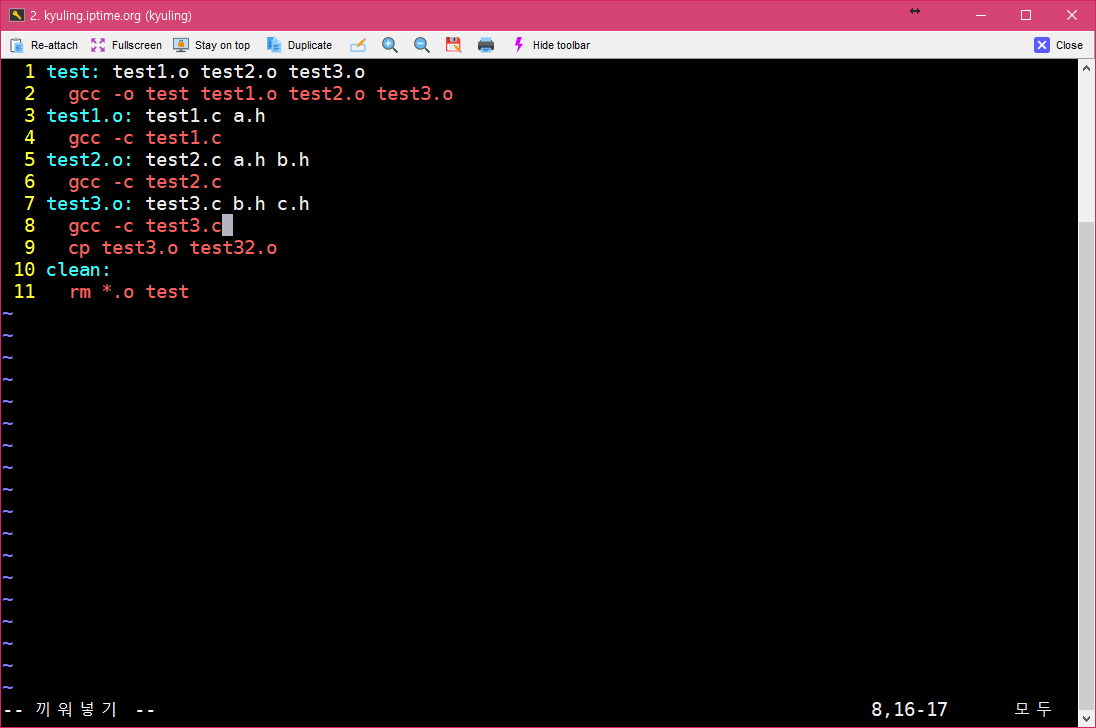
세미콜론을 넣고 한 문장으로 작성하면 된다.
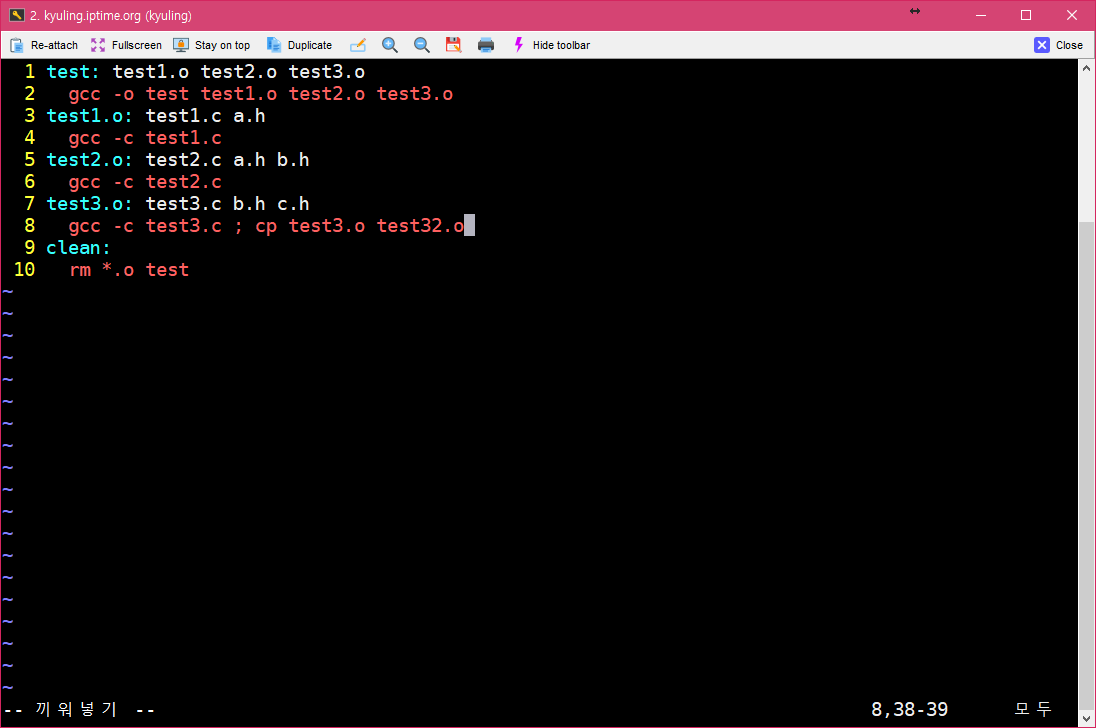
물론, 다음 문장으로 넘겨서 쓰는 것도 가능하다.
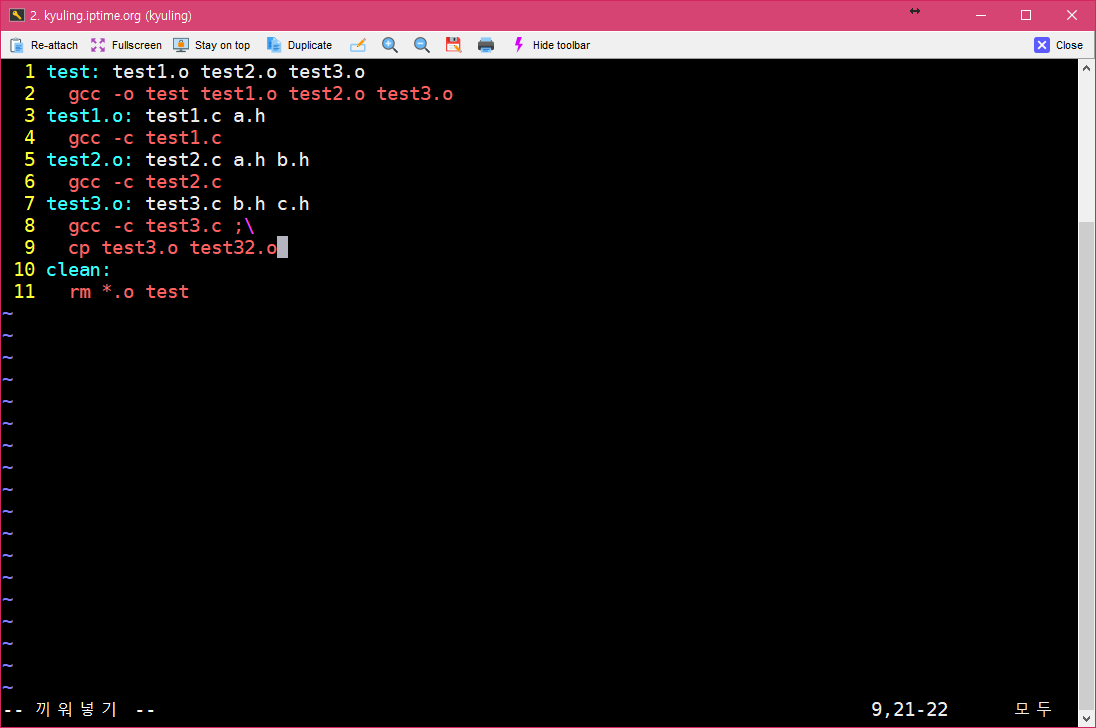
이것을 실행해 보면 확실히 test3.o 레이블을 실행할 때, 명령이 두 라인 실행되어서 복사본이 만들어지는 걸 볼 수 있다.
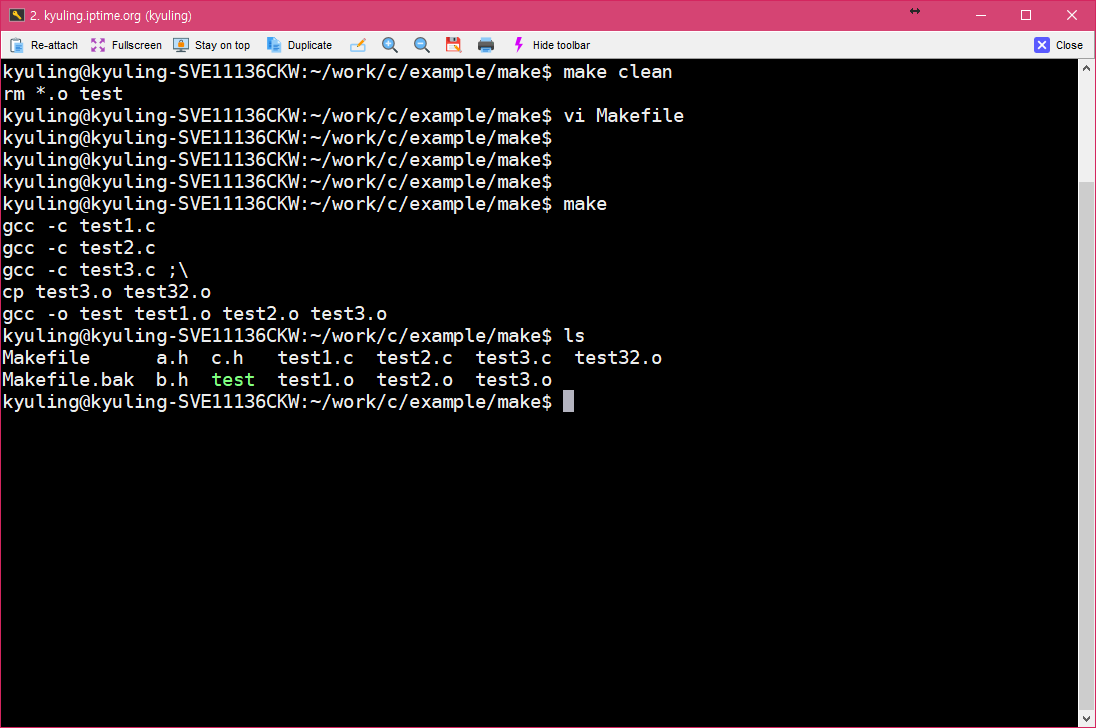
- 명령 실패 무시
make를 실행하다 보면 make는 대상이 있는지, 대상이 의존하는 파일이 수정되었는지의 여부에 따라 필요한 명령을 실행한다. 하지만, 중간 명령의 실행에 실패하면 오류 메시지를 출력하면서 바로 동작을 멈춘다. 이럴 때, 명령이 실패해도 작업을 계속 진행하고 싶을 경우에는 이 과정을 무시할 수 있어야 하는데, make 파일 내 명령어 앞에 하이픈(-)을 삽입하여 주면 된다. 이것도 예시를 확인하자.
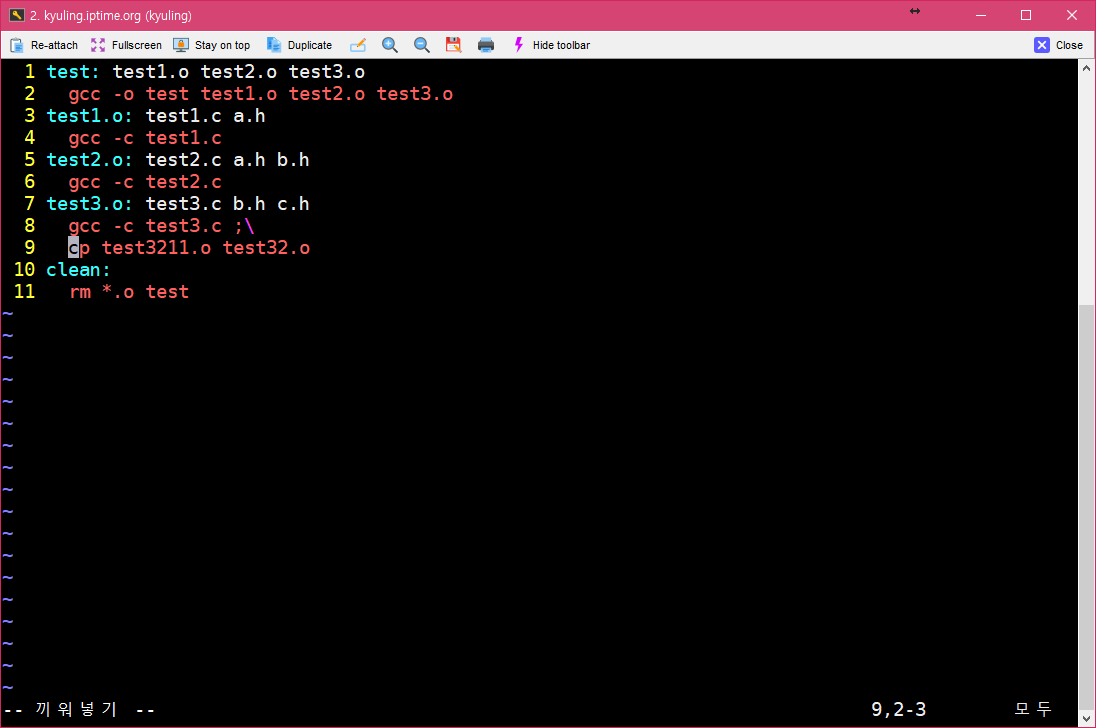
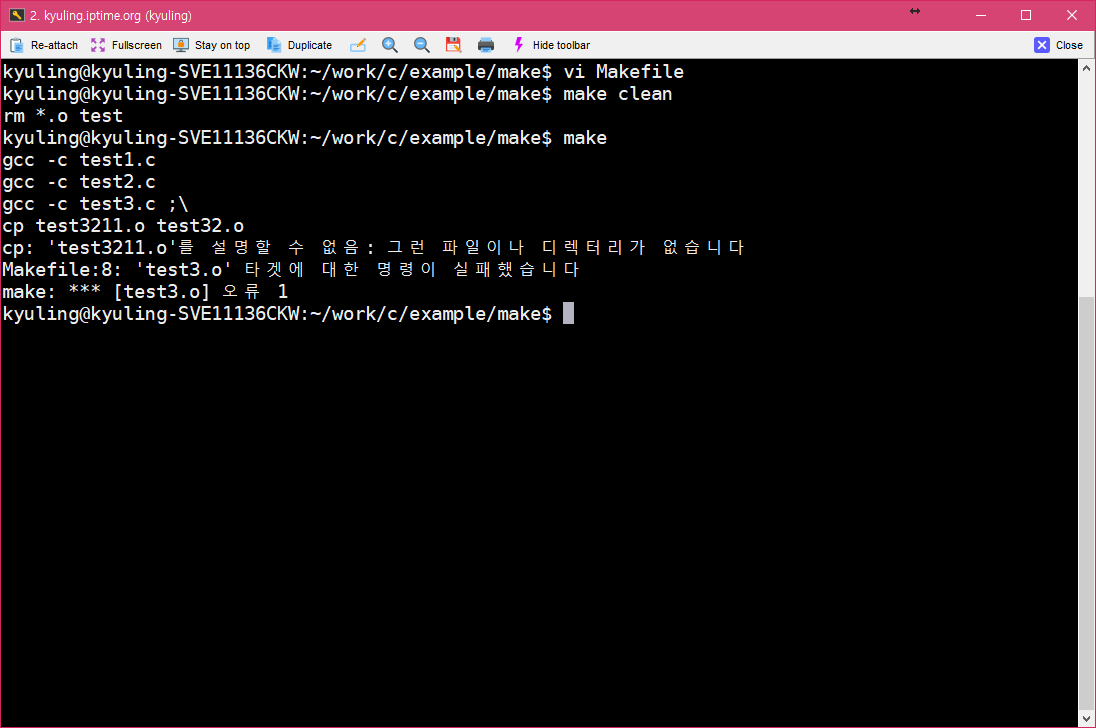
확실하게 없는 파일을 복사하려 하고 있다. 이 경우에 실제로 make를 하게 되면 오류가 난다.
이제, 오류가 나는 줄을 처리하는 곳에 하이픈을 붙여서 실행하면 오류가 나지 않고 마저 실행되지 않았던 명령이 실행될 것이다.
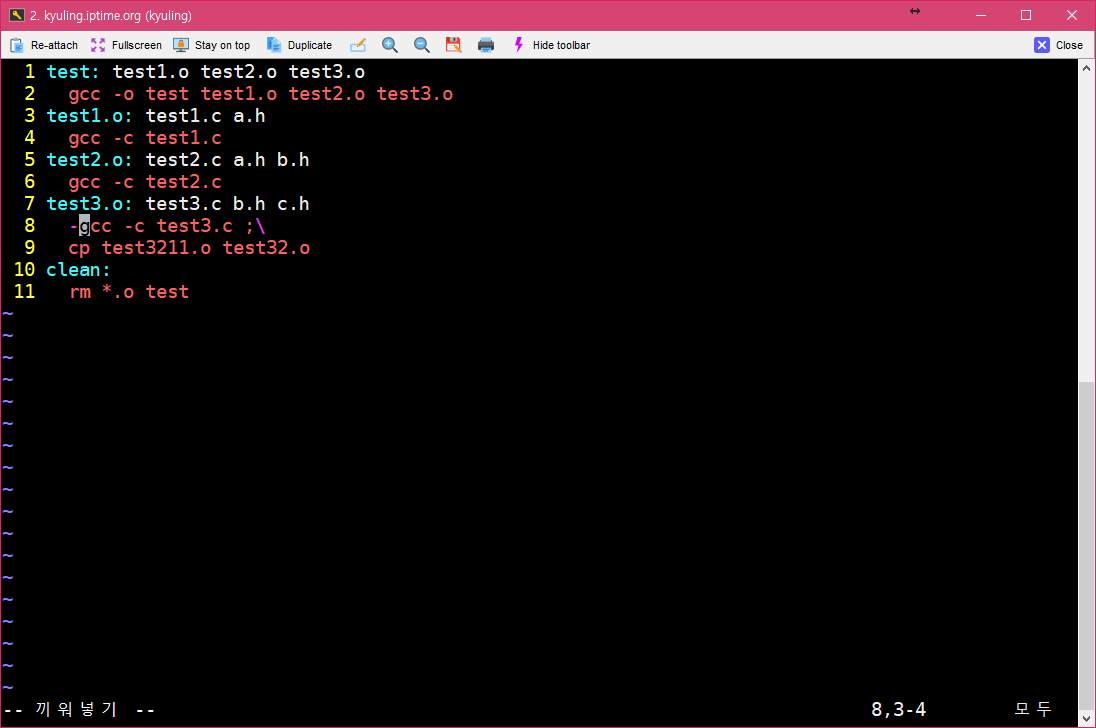
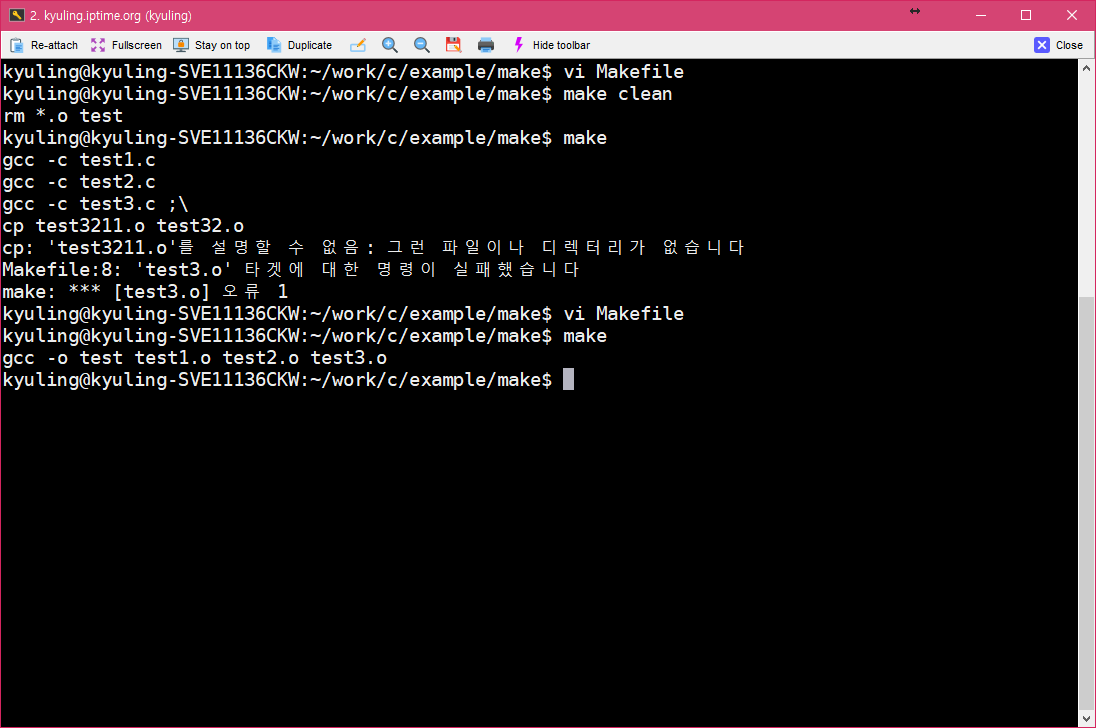
이 결과를 다시 보기 위해서 clean으로 다 지운 후, 다시 컴파일을 시도해 보았다. 그러면 아래와 같이 오류 명령과 함께 무시됨이라고 해서 해당 처리가 무시되었다는 것을 볼 수 있다.
이로써 Makefile을 만드는 데 있어서 가장 기본이 되는 내용들을 전부 살펴보았다. 이 외에도 매크로라던가 사용 규칙, 옵션 들을 좀 더 살펴봐야 하지만, 여기까지만 알아도 공부하는 수준에서의 make 파일의 관리는 될 수 있다. 셸 스크립트 배우는 거 같으면서도 코드 컴파일 및 클리어 기능을 통해서 어느 정도 관리를 할 수 있는 구조가 이런 것이구나를 확인할 수 있는 것은 중요한 요소라고 본다.